PDF (US Ltr)
- 36.1Mb
PDF (A4)
- 36.2Mb
このページは機械翻訳したものです。
このセクションでは、NDB Cluster でレプリケーションを使用するときの既知の問題について説明します。
ソースとレプリカ間の接続が失われました.
ソースクラスタの SQL ノードとレプリカクラスタの SQL ノード間、またはソース SQL ノードとソースクラスタのデータノード間で接続が失われる可能性があります。 後者の場合にこの発生は、物理的な接続が喪失した結果 (たとえば、ネットワークケーブルの破損など) だけではなく、データノードイベントのバッファーのオーバーフローによる可能性もあります。SQL ノードは、応答が遅すぎると、クラスタでドロップされる可能性があります (これは、MaxBufferedEpochs および TimeBetweenEpochs 構成パラメータを調整することで、ある程度まで制御が可能です)。 これが発生した場合は、ソース SQL ノードのバイナリログに記録されずに、ソースクラスタに新しいデータを挿入することも完全に可能です。 このため、高可用性を保証するには、バックアップレプリケーションチャネルを維持し、プライマリチャネルを監視し、必要に応じてセカンダリレプリケーションチャネルにフェイルオーバーしてレプリカクラスタとソースの同期を保つことが非常に重要です。 NDB Cluster は、そのようなモニタリングを単独で実行するようには設計されていません。このためには、外部アプリケーションが必要です。
ソース SQL ノードは、ソースクラスタへの接続または再接続時に 「gap」 イベントを発行します。 (ギャップイベントは一種の「インシデントイベント」であり、データベースの内容に影響を与えるが、一連の変更として容易に表現できないインシデントが発生したことを示します。 インシデントの例としては、サーバー障害、データベースの再同期化、一部のソフトウェア更新および一部のハードウェア変更があります。) レプリカは、レプリケーションログにギャップが発生すると、エラーメッセージとともに停止します。 このメッセージは SHOW REPLICA | SLAVE STATUS の出力で使用可能で、レプリケーションストリームに登録されたインシデントのために SQL スレッドが停止し、手動操作が必要であることを示します。 このような状況での対処の詳細については、セクション23.6.8「NDB Cluster レプリケーションによるフェイルオーバーの実装」を参照してください。
重要
NDB Cluster はレプリケーションステータスをモニターしたりフェイルオーバーを提供したりするように独自に設計されていないため、レプリケーションサーバーまたはクラスタの高可用性が要件である場合は、複数のレプリケーションラインを設定し、プライマリレプリケーションラインでソース mysqld をモニターして、必要に応じてセカンダリ行にフェイルオーバーするように準備する必要があります。 これは、手動や、場合によってはサードパーティーのアプリケーションによって行う必要があります。 この種のセットアップの実装に関する情報については、セクション23.6.7「NDB Cluster レプリケーションでの 2 つのレプリケーションチャネルの使用」および セクション23.6.8「NDB Cluster レプリケーションによるフェイルオーバーの実装」を参照してください。
スタンドアロン MySQL サーバーから NDB Cluster にレプリケートする場合、通常は 1 つのチャネルで十分です。
循環レプリケーション. 次の例に示すように、 NDB Cluster Replication は循環レプリケーションをサポートします。 レプリケーションの設定には、1、2、および 3 という番号が付けられた 3 つの NDB Cluster が含まれます。クラスタ 1 はクラスタ 2 のレプリケーションソースとして機能し、クラスタ 2 はクラスタ 3 のソースとして機能し、クラスタ 3 はクラスタ 1 のソースとして機能するため、円が完成します。 各 NDB Cluster には 2 つの SQL ノードがあり、SQL ノード A と B はクラスタ 1 に属し、SQL ノード C と D はクラスタ 2 に属し、SQL ノード E と F はクラスタ 3 に属します。
これらのクラスタを使用する循環レプリケーションは、次の条件を満たすかぎり、サポートされます。
すべてのソースクラスタとレプリカクラスタの SQL ノードが同じです。
ソースおよびレプリカとして機能するすべての SQL ノードは、
log_slave_updatesシステム変数を有効にして起動されます。
このタイプの循環レプリケーションのセットアップは、次の図に示すとおりです。
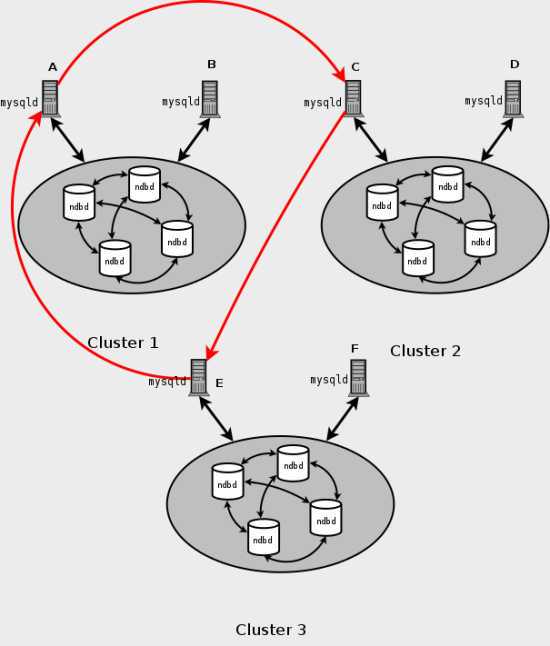
このシナリオでは、クラスタ 1 の SQL ノード A はクラスタ 2 の SQL ノード C に複製し、SQL ノード C はクラスタ 3 の SQL ノード E に複製し、SQL ノード E は SQL ノード A に複製します。 つまり、レプリケーション線 (ダイアグラムの曲線矢印で示される) は、ソースおよびレプリカとして使用されるすべての SQL ノードを直接接続します。
次に示すように、すべてのソース SQL ノードがレプリカであるわけではない循環レプリケーションを設定することもできます:

この場合、各クラスタ内の異なる SQL ノードがソースおよびレプリカとして使用されます。 ただし、log_slave_updates システム変数を有効にして SQL ノードを起動しないでください。 NDB Cluster のこのタイプの循環レプリケーションスキームでは、レプリケーションの行 (図の曲線矢印で再度示されています) が不連続である可能性がありますが、まだ徹底的にテストされていないため、実験的とみなす必要があることに注意してください。
注記
NDB ストレージエンジンは、NDB Cluster の循環レプリケーションを中断する重複キーおよびその他のエラーを抑制する多重呼出し不変実行モードを使用します。 これはグローバル slave_exec_mode システム変数を IDEMPOTENT に設定することと同等ですが、NDB Cluster レプリケーションでは必要ありません。NDB Cluster はこの変数を自動的に設定し、明示的に設定しようとする試みを無視するためです。
NDB Cluster のレプリケーションと主キー.
ノードに障害が発生した場合でも、このような場合に重複行が挿入される可能性があるため、主キーのない NDB テーブルのレプリケーションでエラーが発生する可能性があります。 このため、レプリケートされるすべての NDB テーブルに明示的な主キーを設定することを強くお薦めします。
NDB Cluster レプリケーションと一意キー.
古いバージョンの NDB Cluster では、NDB テーブルの一意キーカラムの値を更新する操作を複製すると、重複キーエラーが発生する可能性がありました。 NDB テーブル間のレプリケーションに関するこの問題は、すべてのテーブル行の更新が実行されるまで一意キーのチェックを保留することで解決されます。
この方法で制約を保留することは、現在 NDB でのみサポートされています。 したがって、NDB から InnoDB や MyISAM などの別のストレージエンジンにレプリケートする場合、一意の鍵の更新はまだサポートされていません。
一意キー更新の遅延チェックなしでレプリケートする場合に発生する問題は、次に示すように、t などの NDB テーブルを使用してソースで作成および移入され、遅延一意キー更新をサポートしないレプリカに転送されます:
CREATE TABLE t (
p INT PRIMARY KEY,
c INT,
UNIQUE KEY u (c)
) ENGINE NDB;
INSERT INTO t
VALUES (1,1), (2,2), (3,3), (4,4), (5,5);
影響を受ける行は ORDER BY オプションで決定された順序で処理されるため、t での次の UPDATE ステートメントはソースで、テーブル全体での実行で、成功します:
UPDATE t SET c = c - 1 ORDER BY p;テーブル全体ではなく一度に 1 つのパーティションに対して行の更新の順序が実行されるため、同じステートメントが複製キーエラーまたは他の制約違反で失敗します。
注記
各 NDB テーブルは、作成時に、キーで無条件にパーティション化されます。 詳細については、セクション24.2.5「KEY パーティショニング」を参照してください。
GTID は未サポート.
グローバルトランザクション ID を使用するレプリケーションは、NDB ストレージエンジンと互換性がなく、サポートされていません。 GTID を有効にすると、NDB Cluster レプリケーションが失敗する可能性があります。
マルチスレッド複製はサポートされていません.
NDB Cluster はマルチスレッドレプリカをサポートせず、slave_parallel_workers、slave_checkpoint_group、slave_checkpoint_group (または同等の mysqld 起動オプション) などの関連するシステム変数を設定しても効果はありません。
これは、レプリカが同じエポック内に書き込まれた場合、あるデータベースで発生しているトランザクションを別のデータベースで発生しているトランザクションから分離できない可能性があるためです。 また、NDB ストレージエンジンによって処理されるすべてのトランザクションには、少なくとも 2 つのデータベース (ターゲットデータベースと mysql システムデータベース) が含まれ、mysql.ndb_apply_status テーブルを更新するための要件が満たされます (セクション23.6.4「NDB Cluster レプリケーションスキーマおよびテーブル」 を参照)。 これにより、トランザクションが特定のデータベースに固有であるというマルチスレッドの要件が解消されます。
--initial での再起動.
--initial オプションを使用してクラスタを再起動すると、GCI 番号とエポック番号のシーケンスが 0 からやり直されます。 (これは通常 NDB Cluster に当てはまり、クラスタに関連するレプリケーションシナリオに限定されません。) この場合、レプリケーションに関与する MySQL サーバーは再起動されます。 この後、RESET MASTER ステートメントと RESET REPLICA | SLAVE ステートメントを使用して、無効な ndb_binlog_index テーブルと ndb_apply_status テーブルをそれぞれクリアする必要があります。
NDB から別のストレージエンジンへのレプリケーション.
ここに示す制限を考慮して、レプリカ上の別のストレージエンジンを使用して、ソース上の NDB テーブルをテーブルにレプリケートできます:
マルチソースレプリケーションおよび循環レプリケーションはサポートされていません (これが機能するには、ソースとレプリカの両方のテーブルで
NDBストレージエンジンを使用する必要があります)。レプリカ上のテーブルのバイナリロギングを実行しないストレージエンジンを使用するには、特別な処理が必要です。
レプリカ上のテーブルに非トランザクションストレージエンジンを使用するには、特別な処理も必要です。
ソース mysqld は、
--ndb-log-update-as-write=0または--ndb-log-update-as-write=OFFで起動する必要があります。
次のいくつかのパラグラフでは、ここで説明したそれぞれの問題の追加情報を示します。
NDB をほかのストレージエンジンにレプリケートする場合、複数のソースはサポートされません.
NDB から別のストレージエンジンへのレプリケーションの場合、2 つのデータベース間の関係は 1 対 1 である必要があります。 つまり、NDB Cluster とほかのストレージエンジンの間では双方向または循環レプリケーションはサポートされていません。
また、NDB および別のストレージエンジン間で複製する場合、複数のレプリケーションチャネルを構成できません。 (NDB Cluster データベースは、複数の NDB Cluster データベースに同時に複製できます。) ソースで NDB テーブルが使用されている場合でも、すべての変更のバイナリログを複数の MySQL Server で保持できますが、レプリカでソースを変更 (フェイルオーバー) するには、レプリカで新しいソースとレプリケーションの関係を明示的に定義する必要があります。
バイナリロギングを実行しないストレージエンジンへの「NDB の複製」テーブル. NDB Cluster から、独自のバイナリロギングを処理しないストレージエンジンを使用するレプリカに複製しようとすると、レプリケーションプロセスはエラー「バイナリロギングができません ... 複数のエンジンが関与し、少なくとも 1 つのエンジンがセルフロギングであるため、ステートメントをアトミックに書き込めません」 (Error 1595 ) で中止されます。 次の方法のいずれかで、この問題を回避できます。
レプリカのバイナリロギングをオフにします. これを実現するには、
sql_log_bin = 0を設定します。mysql.ndb_apply_status テーブルに使用されるストレージエンジンを変更します. このテーブルが独自のバイナリロギングを処理しないエンジンを使用することになるため、競合も解消できます。 これを行うには、レプリカで
ALTER TABLE mysql.ndb_apply_status ENGINE=MyISAMなどのステートメントを発行します。 レプリカでNDB以外のストレージエンジンを使用する場合は、複数のレプリカの同期を維持する必要がないため、これを安全に行うことができます。レプリカの mysql.ndb_apply_status テーブルに対する変更を除外. これを行うには、
--replicate-ignore-table=mysql.ndb_apply_statusを使用してレプリカを起動します。 レプリケーションでほかのテーブルを無視する必要がある場合、代わりに適切な--replicate-wild-ignore-tableオプションを使用することをお勧めします。
重要
NDB Cluster 間でレプリケートする場合は、mysql.ndb_apply_status のレプリケーションまたはバイナリロギングを無効にしたり、このテーブルに使用されるストレージエンジンを変更したりしないでください。 詳細は、NDB Cluster 間のレプリケーションを使用したレプリケーションおよびバイナリログフィルタリング規則,を参照してください。
NDB から非トランザクションストレージエンジンへのレプリケーション.
MyISAM などの非トランザクションストレージエンジンに NDB から複製する場合、INSERT ... ON DUPLICATE KEY UPDATE ステートメントを複製するときに、不要な重複キーエラーが発生することがあります。 これらを抑制するには、--ndb-log-update-as-write=0 を使用します。これにより、更新は更新としてではなく書込みとして強制的に記録されます。
NDB Cluster 間のレプリケーションを使用したレプリケーションおよびバイナリログフィルタリング規則.
レプリケートされるデータベースまたはテーブルのフィルタリングにオプション --replicate-do-*, --replicate-ignore-*, --binlog-do-db または --binlog-ignore-db を使用している場合は、NDB Cluster 間のレプリケーションが正しく動作するために必要な mysql.ndb_apply_status のレプリケーションまたはバイナリロギングをブロックしないように注意する必要があります。 特に、次の点に留意しておく必要があります。
-
--replicate-do-db=を使用すると (およびほかのdb_name--replicate-do-*または--replicate-ignore-*オプションを使用しない)、データベースdb_nameにあるテーブルだけが複製されます。 この場合は、--replicate-do-db=mysql、--binlog-do-db=mysqlまたは--replicate-do-table=mysql.ndb_apply_statusを使用して、mysql.ndb_apply_statusがレプリカに移入されていることも確認する必要があります。--binlog-do-db=を使用すると (およびほかのdb_name--binlog-do-dbオプションを使用しない)、データベースdb_nameにあるテーブルへの変更のみがバイナリログに書き込まれます。 この場合は、--replicate-do-db=mysql、--binlog-do-db=mysqlまたは--replicate-do-table=mysql.ndb_apply_statusを使用して、mysql.ndb_apply_statusがレプリカに移入されていることも確認する必要があります。 -
--replicate-ignore-db=mysqlを使用すると、mysqlデータベースにあるテーブルは複製されません。 この場合、--replicate-do-table=mysql.ndb_apply_statusも使用して、確実にmysql.ndb_apply_statusを複製する必要があります。--binlog-ignore-db=mysqlを使用すると、mysqlデータベースにあるテーブルへの変更はバイナリログに書き込まれません。 この場合、--replicate-do-table=mysql.ndb_apply_statusも使用して、確実にmysql.ndb_apply_statusを複製する必要があります。
各レプリケーションルールには次のことも必要になります。
独自の
--replicate-do-*または--replicate-ignore-*オプション。複数のルールはレプリケーションの 1 つのフィルタリングオプションで表現できません。 これらのルールについての情報は、セクション17.1.6「レプリケーションおよびバイナリロギングのオプションと変数」を参照してください。独自の
--binlog-do-dbまたは--binlog-ignore-dbオプション。複数のルールはバイナリログの 1 つのフィルタリングオプションで表現できません。 これらのルールについての情報は、セクション5.4.4「バイナリログ」を参照してください。
NDB Cluster を、NDB 以外のストレージエンジンを使用するレプリカにレプリケートする場合は、このセクションのほかの場所で説明されているように、以前に指定した考慮事項が適用されないことがあります。
NDB Cluster レプリケーションと IPv6. NDB 8.0.22 以降では、すべてのタイプの NDB Cluster ノードが IPv6 をサポートします。これには、管理ノード、データノード、および API または SQL ノードが含まれます。
NDB 8.0.22 より前では、NDB API および MGM API (およびデータノードと管理ノード) は IPv6 をサポートしていませんが、NDB Cluster 内で SQL ノードとして機能する MySQL Servers-including は IPv6 を使用してほかの MySQL Servers に接続できます。 8.0.22 より前のバージョンの NDB Cluster では、次の図の点線矢印で示されているように、IPv6 を使用してソースおよびレプリカとして機能する SQL ノードを接続し、クラスタ間で複製できます:
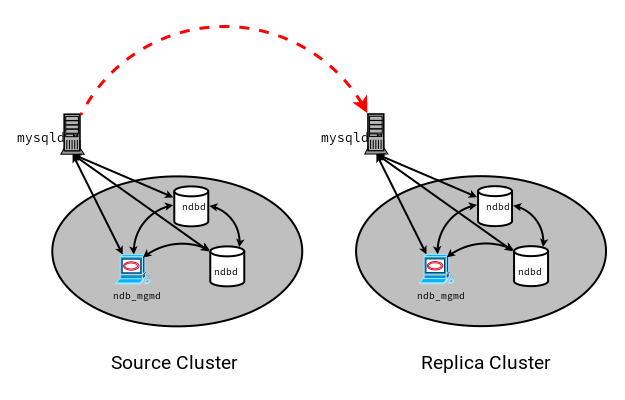
NDB 8.0.22 より前は、範囲内を起点とするすべての接続で、前の図で実線矢印で示されている NDB Cluster が IPv4 を使用する必要があります。 つまり、NDB Cluster データノード、管理サーバー、および管理クライアントはすべて、IPv4 を使用して相互にアクセスできる必要があります。 また、SQL ノードは IPv4 を使用してクラスタと通信する必要があります。 NDB 8.0.22 以降では、これらの制限は適用されなくなりました。また、NDB および MGM API を使用して記述されたアプリケーションは、IPv6 のみの環境を想定して記述および配備できます。
属性の昇格と降格.
NDB Cluster レプリケーションには、属性の昇格と降格のサポートが含まれます。 後者の実装では、不可逆型変換と非不可逆型変換が区別され、レプリカでのそれらの使用は、slave_type_conversions グローバルサーバーシステム変数を設定することで制御できます。
NDB Cluster での属性の昇格および降格の詳細は、行ベースレプリケーション: 属性の昇格と降格 を参照してください。
NDB は、InnoDB や MyISAM とは異なり、仮想カラムへの変更をバイナリログに書き込みませんが、NDB Cluster レプリケーションまたは NDB とほかのストレージエンジン間のレプリケーションに悪影響はありません。 格納された生成カラムに対する変更がログに記録されます。