PDF (US Ltr)
- 36.1Mb
PDF (A4)
- 36.2Mb
このページは機械翻訳したものです。
レプリケーションをスケールアウトソリューションとして、つまり、いくつかの合理的な制限内でデータベースクエリーの負荷を複数のデータベースサーバーに分割するために使用できます
レプリケーションは 1 つのソースから 1 つ以上のレプリカに分散するため、スケールアウトにレプリケーションを使用するのは、読取り数が多く、書込み/更新数が少ない環境で最適です。 ほとんどの web サイトは、ユーザーが Web サイトを参照したり、記事を読んだり、投稿したり、製品を表示したりするこのカテゴリに該当します。 更新は、セッション管理中、購入するとき、またはフォーラムにコメント/メッセージを追加するときにのみ発生します。
この状況でのレプリケーションでは、書込みが必要なときに web サーバーがソースと通信できるようにしながら、レプリカに読取りを分散できます。 このシナリオのためのサンプルレプリケーションレイアウトは、図17.1「スケールアウト中のパフォーマンスを向上するためにレプリケーションを使用する」で見ることができます。
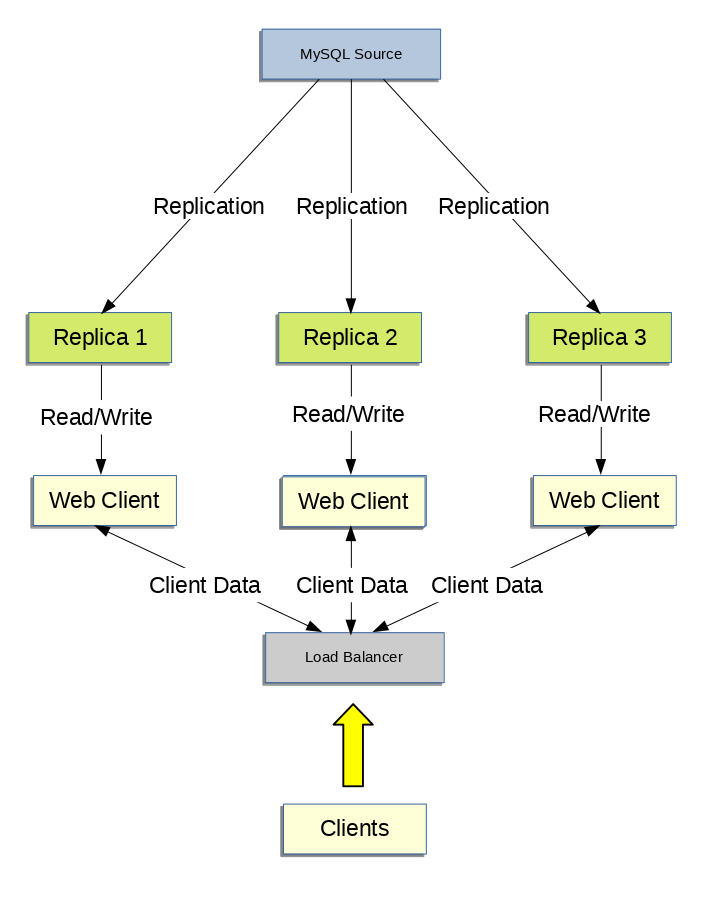
データベースにアクセスするコードの一部が適切に抽象化/モジュール化されている場合は、それを複製されたセットアップで動作するように変換することはとても効率的かつ簡単であるはずです。 すべての書込みをソースに送信し、読取りをソースまたはレプリカに送信するように、データベースアクセスの実装を変更します。 コードがこのレベルの抽象を備えていない場合、複製されたシステムのセットアップは整理するための機会および動機となります。 まずは、次の関数を実装するラッパーライブラリまたはモジュールを作成してください。
safe_writer_connect()safe_reader_connect()safe_reader_statement()safe_writer_statement()
各関数名の safe_ は、その関数がすべてのエラー条件の処理を引き受けることを意味します。 関数に別の名前を使用できます。 重要なことは、読み取りのための接続、書き込みのための接続、読み取りの実行、および書き込みの実行に対して、統一されたインタフェースを持つことです。
次に、ラッパーライブラリを使用するようにクライアントコードを変換してください。 これは、最初は苦しくて怖い工程かもしれませんが、長い目でみるとやるだけの価値があります。 ここで説明したアプローチを使用するすべてのアプリケーションは、複数のレプリカを含むアプリケーションであっても、ソース/レプリカ構成を利用できます。 こうしたコードは非常に保守しやすく、トラブルシューティングオプションを追加するのも手間がかかりません。 変更する必要があるのは、1 つまたは 2 つの関数のみです (たとえば、各ステートメントの所要時間、または発行されたステートメントのうちエラーが発生したステートメントをログに記録する場合)。
多数のコードを記述した場合は、変換スクリプトを記述して変換タスクを自動化できます。 理想的には、コードが一貫性のあるプログラミングスタイル規則を使用するべきです。 そうでない場合は、一貫性のあるスタイルを使用するために、とにかく書き換えたり、少なくとも詳しく調べて手動で整理したりすることをお勧めします。