MySQL Enterprise Monitor 8.0 Release Notes
This section describes the NDB Cluster advisors.
Note
This section does not describe the expression-based advisors. For information in the expression-based NDB Cluster advisors, see Section 20.4, “NDB Cluster Advisors”.
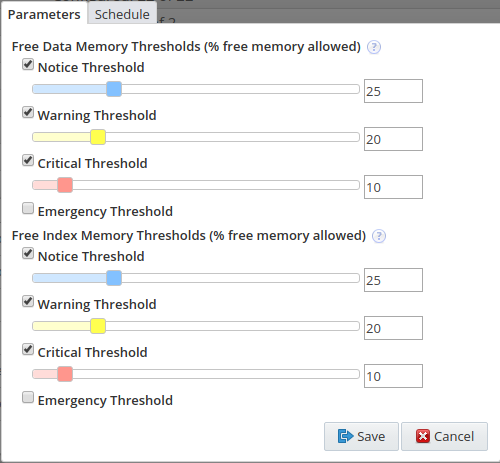
Table 21.2 NDB Cluster Memory Usage Advisor Controls
| Name | Description |
|---|---|
Free Data Memory Thresholds (% free memory allowed) |
Events are generated if the percentage of free data memory in a cluster data node drops below the thresholds defined here. Database inserts start to fail as all of the memory is consumed. |
Free Index Memory Thresholds (% free memory allowed) |
Events are generated if the percentage of free index memory in a cluster data node drops below the thresholds defined here. Database inserts start to fail as all of the memory is consumed. |
This advisor is also responsible for populating the NDB Data Node - Data Memory graphs.
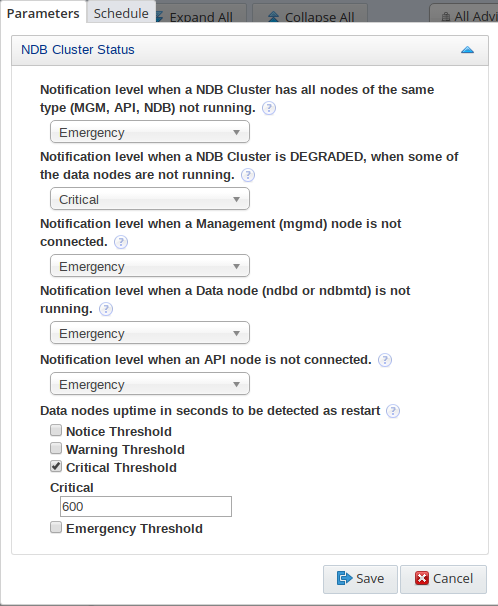
Table 21.3 NDB Cluster Status Advisor Controls
| Name | Description |
|---|---|
Notification level when a NDB Cluster has all nodes of the same type (MGM, API, NDB) not running. |
Checks the node sets and generates an event if the nodes
are not in |
Notification level when a NDB Cluster is DEGRADED, when some of the data nodes are not running. |
Checks the data-node group sets and generates events for
nodes that are not in |
Notification level when a Management (mgmd) node is not connected. |
Checks the node and process status and generates events
if the node is not in |
Notification level when a Data node (ndbd or ndbmtd) is not running. |
Checks the node and process status and generates events
if either the node is not in
|
Notification level when an API node is not connected |
Checks the node status and generates events if the node is not in CONNECTED status |
Data nodes uptime in seconds to be detected as restart |
To perform useful work, the cluster data nodes must be up-and-running continuously. It is normal for a production system to run continuously for weeks, months, or longer. If a data node has been restarted recently, it may be the result of planned maintenance, but it may also be due to an unplanned event that should be investigated. This advisor generates events if a data node is detected that has been running for a short amount of time. |
This advisor also populates the NDB Data Nodes graph.