HeatWave Release Notes
MySQL HeatWave AutoML works with labeled and unlabeled data to train and score machine learning models.
Labeled data is data that has values associated with it. It has feature columns and a target column (the label), as illustrated in the following diagram:
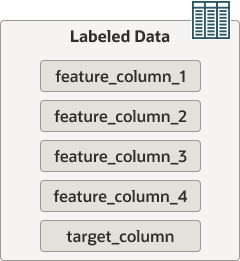
Feature columns contain the input variables used to train the machine learning model. The target column contains ground truth values or, in other words, the correct answers. This dataset can be considered the training dataset.
A labeled dataset with ground truth values is also used to score a model (compute its accuracy and reliability). This dataset should have the same columns as the training dataset but with a different set of data. This dataset can be considered the validation dataset.
A table of data for bank customers can be a labeled dataset.
The feature columns in the table have data related to job,
marital status, education, and city of residence. The target
column has the approval status of a loan application,
Yes or No. You can use
some of the data in this table to train a classification
machine learning model. You can also use the data in the
table that wasn't used for training to score the trained
machine learning model.
Unlabeled data has feature columns but no target column (no answers), as illustrated below:
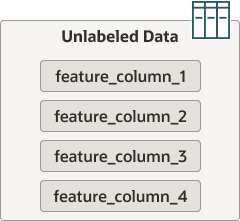
If you are training a machine learning model that does not require labeled data, such as models for topic modeling or anomaly detection, you use unlabeled data. MySQL HeatWave AutoML also uses unlabeled data to generate predictions and explanations. It must have exactly the same feature columns as the training dataset but no target column. This type of dataset can be considered the test dataset. Test data starts as labeled data, but the label is not considered when the machine learning model generates predictions and explanations. This allows you to compare the generated predictions and explanations with the real values in the dataset before you start using “unseen data”.
The “unseen data” that you eventually use with your model to make predictions is also unlabeled data. Like the test dataset, unseen data must have exactly the same feature columns as the training dataset but no target column.
A table of data for credit card transactions can be an unlabeled dataset. The feature columns in the table have data related to the amount of the purchase and the location of the purchase. Because there is no column identifying any transactions as anomalous or normal, it is unlabeled data. MySQL HeatWave AutoML can train an anomaly detection model on the unlabeled data to try and find unusual patterns in the data. A different set of labeled data identifying anomalies in credit cards transactions can be used to score the trained model.
To start using AutoML with sample datasets, see Machine Learning Use Cases. Alternatively, navigate to the MySQL HeatWave AutoML examples and performance benchmarks GitHub repository at https://github.com/oracle-samples/heatwave-ml.
Learn how to Prepare Training and Testing Datasets.
Learn how to Train a Model.