HeatWave Release Notes
Labeled data has feature columns and a target column (the label), as illustrated in the following diagram:
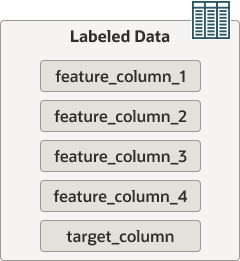
Feature columns contain the input variables used to train the machine learning model. The target column contains ground truth values or, in other words, the correct answers. A labeled dataset with ground truth values is required to train a machine learning model. In the context of this guide, the labeled dataset used to train a machine learning model is referred as the training dataset.
A labeled dataset with ground truth values is also used to score a model (compute its accuracy and reliability). This dataset should have the same columns as the training dataset but with a different set of data. In the context of this guide, the labeled dataset used to score a model is referred as the validation dataset.