MySQL 8.4 Release Notes
- 25.2.1 NDB Cluster Core Concepts
- 25.2.2 NDB Cluster Nodes, Node Groups, Fragment Replicas, and Partitions
- 25.2.3 NDB Cluster Hardware, Software, and Networking Requirements
- 25.2.4 What is New in MySQL NDB Cluster 8.4
- 25.2.5 Options, Variables, and Parameters Added, Deprecated or Removed in NDB 8.4
- 25.2.6 MySQL Server Using InnoDB Compared with NDB Cluster
- 25.2.7 Known Limitations of NDB Cluster
NDB Cluster is a technology that enables clustering of in-memory databases in a shared-nothing system. The shared-nothing architecture enables the system to work with very inexpensive hardware, and with a minimum of specific requirements for hardware or software.
NDB Cluster is designed not to have any single point of failure. In a shared-nothing system, each component is expected to have its own memory and disk, and the use of shared storage mechanisms such as network shares, network file systems, and SANs is not recommended or supported.
NDB Cluster integrates the standard MySQL server with an in-memory
clustered storage engine called NDB
(which stands for “Network
DataBase”). In our
documentation, the term NDB refers to
the part of the setup that is specific to the storage engine,
whereas “MySQL NDB Cluster” refers to the combination
of one or more MySQL servers with the
NDB storage engine.
An NDB Cluster consists of a set of computers, known as hosts, each running one or more processes. These processes, known as nodes, may include MySQL servers (for access to NDB data), data nodes (for storage of the data), one or more management servers, and possibly other specialized data access programs. The relationship of these components in an NDB Cluster is shown here:
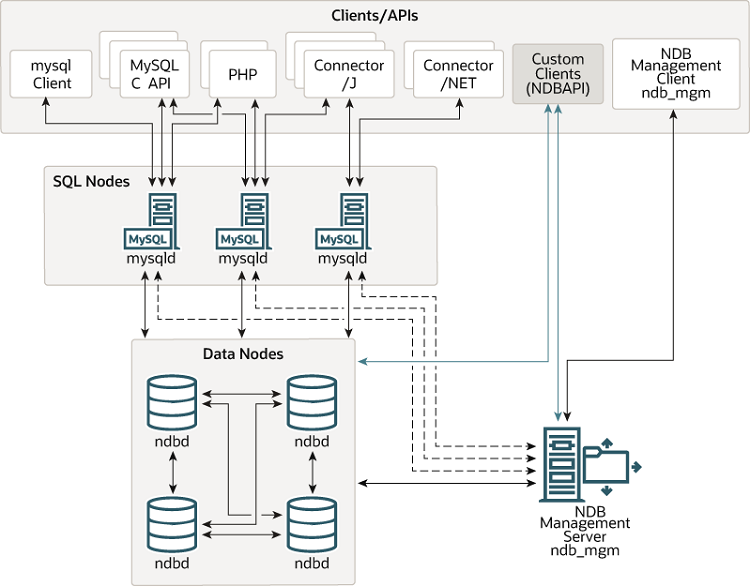
All these programs work together to form an NDB Cluster (see
Section 25.5, “NDB Cluster Programs”. When data is stored by the
NDB storage engine, the tables (and
table data) are stored in the data nodes. Such tables are directly
accessible from all other MySQL servers (SQL nodes) in the cluster.
Thus, in a payroll application storing data in a cluster, if one
application updates the salary of an employee, all other MySQL
servers that query this data can see this change immediately.
An NDB Cluster 8.4 SQL node uses the
mysqld server daemon, which is the same as the
mysqld supplied with MySQL Server
8.4 distributions. You should keep in mind that
an instance of mysqld, regardless of
version, that is not connected to an NDB Cluster cannot use the
NDB storage engine and cannot access
any NDB Cluster data.
The data stored in the data nodes for NDB Cluster can be mirrored; the cluster can handle failures of individual data nodes with no other impact than that a small number of transactions are aborted due to losing the transaction state. Because transactional applications are expected to handle transaction failure, this should not be a source of problems.
Individual nodes can be stopped and restarted, and can then rejoin the system (cluster). Rolling restarts (in which all nodes are restarted in turn) are used in making configuration changes and software upgrades (see Section 25.6.5, “Performing a Rolling Restart of an NDB Cluster”). Rolling restarts are also used as part of the process of adding new data nodes online (see Section 25.6.7, “Adding NDB Cluster Data Nodes Online”). For more information about data nodes, how they are organized in an NDB Cluster, and how they handle and store NDB Cluster data, see Section 25.2.2, “NDB Cluster Nodes, Node Groups, Fragment Replicas, and Partitions”.
Backing up and restoring NDB Cluster databases can be done using the
NDB-native functionality found in the NDB Cluster
management client and the ndb_restore program
included in the NDB Cluster distribution. For more information, see
Section 25.6.8, “Online Backup of NDB Cluster”, and
Section 25.5.23, “ndb_restore — Restore an NDB Cluster Backup”. You can also
use the standard MySQL functionality provided for this purpose in
mysqldump and the MySQL server. See
Section 6.5.4, “mysqldump — A Database Backup Program”, for more information.
NDB Cluster nodes can employ different transport mechanisms for inter-node communications; TCP/IP over standard 100 Mbps or faster Ethernet hardware is used in most real-world deployments.