MySQL Shell 8.0.21 comes with two utilities which can be used to perform logical dumps of all the schemas from an instance (util.dumpInstance()) or selected schemas (util.dumpSchemas()). These tools offer major performance improvements over the mysqldump utility, some of our benchmarks show a throughput up to 3GB/s! Let’s see how this is achieved.
This is part 4 of the blog post series about MySQL Shell Dump & Load:
- MySQL Shell Dump & Load part 1: Demo!
- MySQL Shell Dump & Load part 2: Benchmarks
- MySQL Shell Dump & Load part 3: Load Dump
Parallelization
The dump process uses multiple threads to perform its tasks (the number of threads can be specified using the threads option), allowing for parallel execution of time-consuming operations. Each thread opens its own connection to the target server and can be working on dumping data, dumping DDL or splitting the table data into chunks.
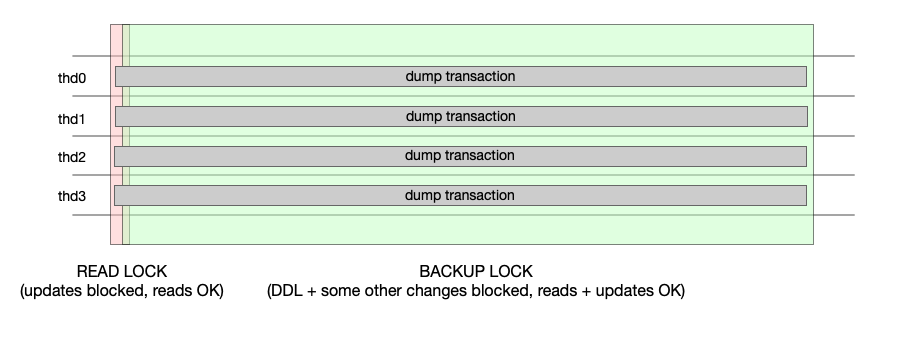
When the consistent option is set to true (which is the default value), the dump is going to be consistent (as long as the dumped tables use the InnoDB engine). When the dump process is started, a global read lock is set by the global Shell session using the FLUSH TABLES WITH READ LOCK statement. Next, all threads establish connections with the server and start transactions using:
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READSTART TRANSACTION WITH CONSISTENT SNAPSHOT
Once all the threads start transactions, the instance is locked for backup and the global read lock is released.
 Chunking
Chunking
It’s usually the case that the size of tables in a schema varies a lot, there are a few very large tables and many smaller ones. Adding more threads will not speed up the dumping process in such a case. In order to overcome this problem, the data in tables can be divided into smaller chunks, each of which will be dumped to a separate file by one of the threads.
Our chunking algorithm strives to find the primary key (or unique index) values that partition the table rows into approximately equal size chunks. It uses EXPLAIN statements to determine the chunk sizes, acquiring row count estimates from the optimizer, as opposed to e.g. SELECT COUNT(*), which would need to scan rows one by one. These estimates are often not very accurate, but it’s significantly faster and good enough for our purposes.
The chunking is turned on by default and will result in files containing roughly 32MB of uncompressed data. These features can be set up using the chunking and bytesPerChunk options respectively, it’s usually a good idea to increase the latter if your data set is very large.
Output format
The mysqldump, mysqlpump and mydumper utilities write the data as a series of INSERT statements, while the new Shell utilities use the default format expected by the LOAD DATA statement. This results in output files that are smaller on average, meaning that they can be produced more quickly. As an additional benefit, loading such files is much faster.
Compression
By default, all data files are compressed using the zstd algorithm, which offers a good balance between compression ratio and encoding performance. The other supported algorithm is gzip. Compression can also be disabled by setting the compression option to none.
Code optimization
The code of the dumper has been heavily benchmarked. In the course of this process we identified and fixed various issues throughout the Shell’s code base, like unnecessary data copies, redundant function calls, superfluous virtual calls. The “hot” function, the one that writes data to the output files, has been carefully analyzed and optimized.
Performance
Here’s a comparison of performance of the two new utilities provided by the Shell and mysqldump, mysqlpump and mydumper:
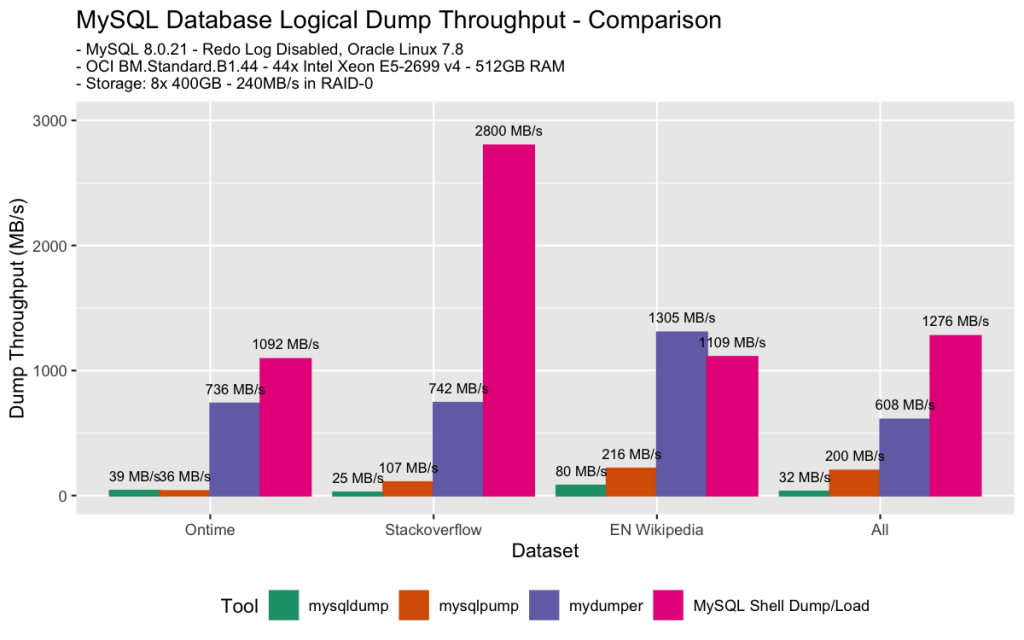
For more benchmark results, please see MySQL Shell Dump & Load part 2: Benchmarks
What’s next?
The util.dumpInstance() and util.dumpSchemas() utilities provide some major performance boost over the existing tools, but there’s still some room for improvement. In particular, our chunking algorithm could certainly be optimized and this is something that we plan to tackle in the future. Stay tuned!