This second part about the new MySQL Shell Dump & Load utilities aims to demonstrate the performance while also comparing it with various other logical dump and load tools available: mysqldump, mysqlpump & mydumper.
To make the numbers more meaningful, I used several real world production datasets that are available online: stackoverflow.com, en.wikipedia.org, ontime flight data and a combination of all of the 3.
This is part 2 of the blog post series about MySQL Shell Dump & Load:
- MySQL Shell Dump & Load part 1: Demo!
- MySQL Shell Dump & Load part 3: Load Dump
- MySQL Shell Dump & Load part 4: Dump Instance & Schemas
Database Environment
The tests are performed on a high-end server, with plenty of CPU, RAM & Storage performance. Both the dump/load tools and the server were located on the same host.
- Oracle Linux 7.8
- OCI Bare Metal instance BM.Standard.B1.44
- 44x Intel Xeon E5-2699 v4. Base frequency 2.2 GHz, max turbo frequency 3.6 GHz & HyperThreading enabled (88 total visible cores)
- 512 GB RAM
- 25 Gbps network (also used by block storage)
- 3.2 TB Storage: 8 block volumes, RAID-0 Striped MD, each 400GB
- MySQL Community Server 8.0.21
- InnoDB Redo log is disabled (which also disables doublewrite):
|
1 |
ALTER INSTANCE DISABLE INNODB REDO_LOG; |
- MySQL Configuration (other settings are just the default):
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
[mysqld] innodb_dedicated_server=on innodb_numa_interleave=on innodb_adaptive_hash_index=0 innodb_change_buffering=none local_infile=1 skip_log_bin innodb_buffer_pool_instances=16 innodb_read_io_threads=16 innodb_write_io_threads=16 innodb_io_capacity=40000 innodb_io_capacity_max=60000 innodb_max_dirty_pages_pct=10 |
Dump & Load Tool — usage
Each tool has to be used differently for dump and load, as explained below.
mysqldump
- As
mysqldumpdoes not have built-in compression, the dump output was piped tozstd. - With
mysqldump, both dump and load is single-threaded.
Dump:
|
1
2
3
|
$ mysqldump --single-transaction \ --databases <db> \ | zstd -z <file> |
Load:
|
1
2
|
$ zstd -d --stdout <file> \ | mysql |
mysqlpump
-
mysqlpumphas built-in compression, bothzlibandlz4, withlz4being the fastest choice by far,zlibwas very slow. -
mysqlpumpcan dump data in multiple threads, but is limited at a table level. If there is a very large table, it will only be dumped by 1 thread. - Unfortunately
mysqlpumpgenerates a single SQL file, similar tomysqldump, and loading data is single-threaded.
Dump:
|
1
2
3
4
|
$ mysqlpump --default-parallelism=88 \ --compress-output lz4 \ --databases <db> \ > <file> |
Load:
|
1 |
$ lz4cat <file> | mysql |
mydumper
-
mydumperis capable of dumping data in parallel, and when using the--rowsoption can also dump a single table in parallel.myloaderis also provided to load the data in parallel. - Tables are split in chunks of about 250.000 rows, zlib compression is also enabled.
Dump:
|
1
2
3
4
5
6
|
$ mydumper --rows 250000 \ -c \ --trx-consistency-only \ -t 88 \ -B <db> \ -o <directory> |
Load:
|
1
2
|
$ myloader -t 88 \ -d <directory> |
MySQL Shell Dump/Load
- Data was dumped in chunks of ~256 MB
Dump:
|
1
2
3
4
|
mysqlsh-js> util.dumpSchemas(["<db>"], "<directory>", {threads: 88, bytesPerChunk: "256M"}) |
Load:
|
1
2
|
mysqlsh-js> util.loadDump("<directory>", {threads: 88}) |
Datasets
Each dataset is available for download.
Ontime
Airline On-Time Statistics, from 1987 until April 2020.
- Available on transtats.bts.gov
- One single MySQL table, a single primary key, no secondary keys
- Uncompressed TSV size: 64 GB
- 194,699,018 rows
Stackoverflow.com
stackoverflow.com data
- Available on archive.org
- Uncompressed TSV size: 216 GB
- 502,676,396 rows
EN Wikipedia
EN Wikipedia backup, from 20200620
- Downloaded enwiki backup
- uncompressed TSV size: 130 GB
- 1,673,892,597 rows
- frequent use of
binarydatatype
All
All above datasets combined
- Dataset did not fit in memory
- uncompressed TSV Size: 410 GB
- 2,371,268,011 rows
Benchmark Results
Time to show some results…
Dump
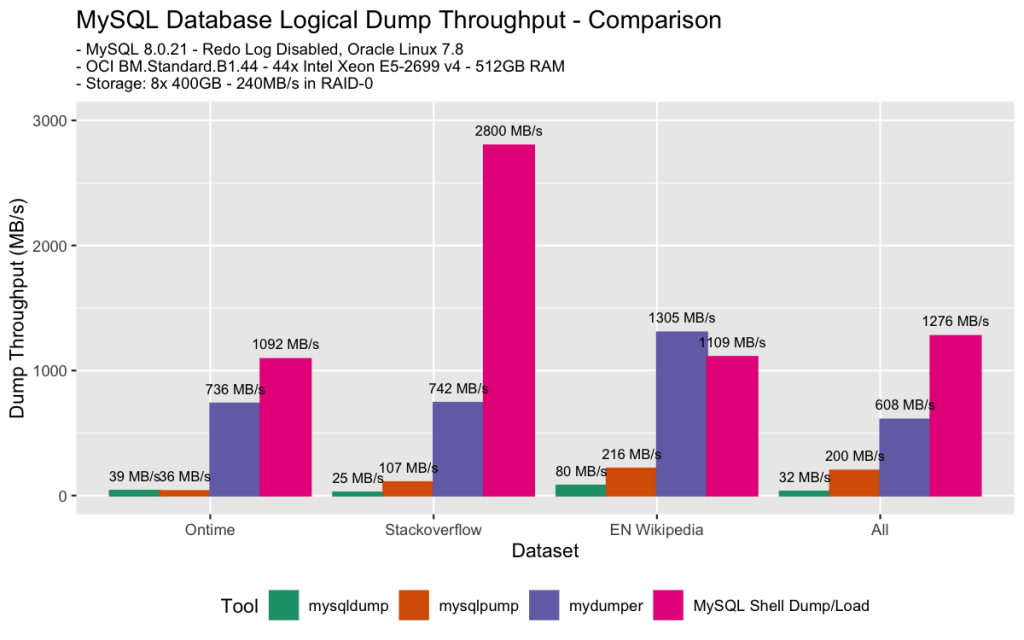
- as expected, both
mysqldumpandmysqlpumplack or are limited in parallelizing the dump process. - for
mysqlpump, there are just not enough large tables in all datasets to be able to improve dump throughput. - using
mydumperand MySQL Shell is a big difference compared to the others - MySQL Shell is the fastest in all but 1 case, sometimes much faster (stackoverflow)
- one possible reason that
mydumperis mostly slower is that it useszlibcompression which is much slower thanzstd -
mydumperwas faster in dumping wikipedia than MySQL Shell, which might be because the wikipedia dataset contains many binary columns which MySQL Shell converts to base64 format;mydumperdoes not. MySQL Shell 8.0.22 will contain further improvements.
- one possible reason that
Load
Next to disabling the InnoDB redo log, MySQL Server 8.0.21 includes improvements to the lock manager which benefit the write scalability of InnoDB by replacing the lock system mutex (lock_sys->mutex). This improves write performance, especially in environments with distant NUMA nodes (e.g. AMD Epyc Naples).
Warning: disabling the InnoDB redo log is intended only for loading data into a new MySQL instance. Do not disable redo logging on a production system, an unexpected server stoppage while redo logging is disabled can/will cause data loss and instance corruption.
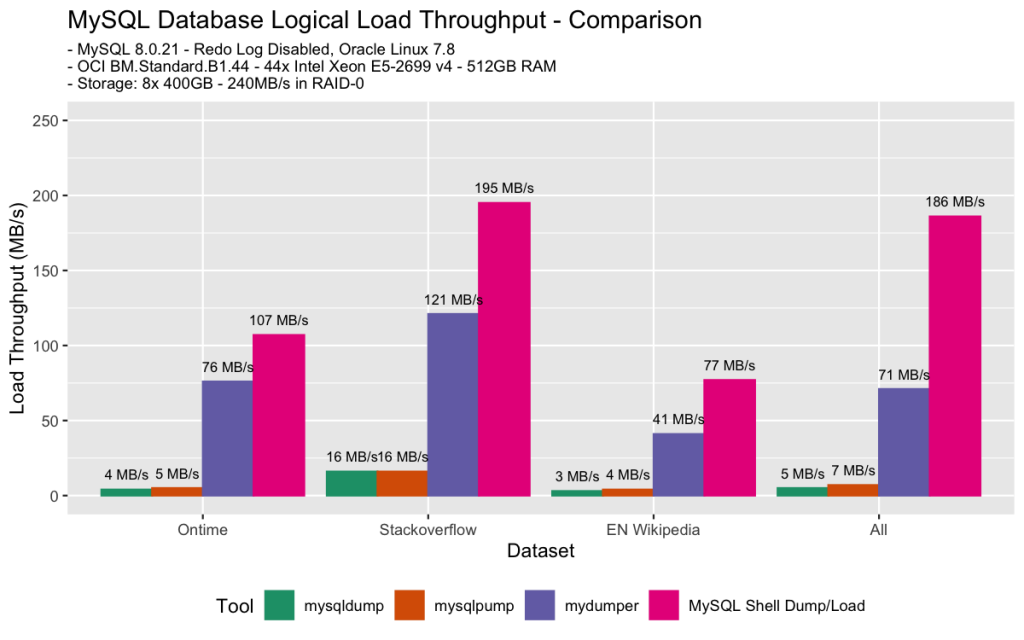
- both
mysqldumpandmysqlpumpgenerate a single.sqlfile so loading data is single threaded, thus they are much slower - MySQL Shell is faster than
myloaderin all cases, and this is due to its scheduling algorithm which is explained in part 3 of this blog post series.
Secondary indexes impact write throughput
The more secondary indexes present, the slower the write throughput is expected to be, which is the case with the stackoverflow and wikipedia datasets.
MySQL Shell has the ability to create secondary indexes after the data is loaded (with the deferTableIndexes option), but adding indexes after the fact makes the whole process slower in all these datasets, so it is often not the best choice. mysqlpump does this by default, but the performance gain is negligible compared to the results we get with myloader and MySQL Shell.
Partitioning can help with large tables
So why is loading the ontime table slower than the other datasets?
The reason is that the ontime dataset consists of a single table. The bottleneck is in InnoDB on a per table level (index locking & page locks). When we partition the ontime table, in this case by 128 KEY() partitions, the write throughput increases significantly, especially when using MySQL Shell:

As MySQL Shell tracks progress of the load, it is possible to add partitions by first loading only the DDL, make the changes, and then loading the rest of the dump:
|
1
2
3
4
5
6
|
mysqlsh-js> util.loadDump("<directory>", {threads: 88 loadData: false}) mysqlsh-js> \sql ALTER TABLE ontime.ontime PARTITION BY KEY() PARTITIONS 128; mysqlsh-js> util.loadDump("<directory>", {threads: 88}) |
MySQL Shell Dump & Load: Fast!
As shown in these benchmarks, MySQL Shell is able to dump data fast, up to almost 3GB/s and load data at speeds above 200MB/s (when the InnoDB redo log is disabled). The next blog posts will cover how Shell achieves this dump and load performance.