MySQL NDB Cluster 8.1 Manual
MySQL NDB Cluster 8.0 Manual
NDB Cluster Internals Manual
This section discusses the ClusterJ API and the object model used to represent the data handled by the application.
Application Programming Interface.
The ClusterJ API depends on 4 main interfaces:
Session, SessionFactory,
Transaction, and
QueryBuilder.
Session interface.
All access to NDB Cluster data is done in the context of a
session. The
Session
interface represents a user's or application's
individual connection to an NDB Cluster. It contains methods for
the following operations:
Finding persistent instances by primary key
Creating, updating, and deleting persistent instances
Getting a query builder (see com.mysql.clusterj.query.QueryBuilder)
Getting the current transaction (see com.mysql.clusterj.Transaction).
SessionFactory interface.
Sessions are obtained from a
SessionFactory,
of which there is typically a single instance for each NDB
Cluster that you want to access from the Java VM.
SessionFactory stores configuration
information about the cluster, such as the hostname and port
number of the NDB Cluster management server. It also stores
parameters regarding how to connect to the cluster, including
connection delays and timeouts. For more information about
SessionFactory and its use in a ClusterJ application, see
Getting the SessionFactory and getting a Session.
Transaction interface.
Transactions are not managed by the Session
interface; like other modern application frameworks, ClusterJ
separates transaction management from other persistence methods.
Transaction demarcation might be done automatically by a
container or in a web server servlet filter. Removing
transaction completion methods from Session
facilitates this separation of concerns.
The
Transaction
interface supports the standard begin, commit, and rollback
behaviors required by a transactional database. In addition, it
enables the user to mark a transaction as being rollback-only,
which makes it possible for a component that is not responsible
for completing a transaction to indicate that—due to an
application or database error—the transaction must not be
permitted to complete normally.
QueryBuilder interface.
The
QueryBuilder
interface makes it possible to construct criteria queries
dynamically, using domain object model properties as query
modeling elements. Comparisons between parameters and database
column values can be specified, including equal, greater and
less than, between, and in operations. These comparisons can be
combined using methods corresponding to the Boolean operators
AND, OR, and NOT. Comparison of values to
NULL is also supported.
Data model. ClusterJ provides access to data in NDB Cluster using domain objects, similar in many ways to the way that JPA models data.
In ClusterJ, the domain object mapping has the following characteristics:
-
All tables map to persistent interfaces. For every
NDBtable in the cluster, ClusterJ uses one or more interfaces. In many cases, a single interface is used; but for cases where different columns are needed by different parts of the application, multiple interfaces can be mapped to the same table.However, the classes themselves are not persistent.
-
Users map a subset of columns to persistent properties in interfaces. Thus, all properties map to columns; however, not all columns necessarily map to properties.
All ClusterJ property names default to column names. The interface provides getter and setter methods for each property, with predictable corresponding method names.
Annotations on interfaces define mappings.
The user view of the application environment and domain objects is illustrated in the following diagram, which shows the logical relationships among the modeling elements of the ClusterJ interfaces:
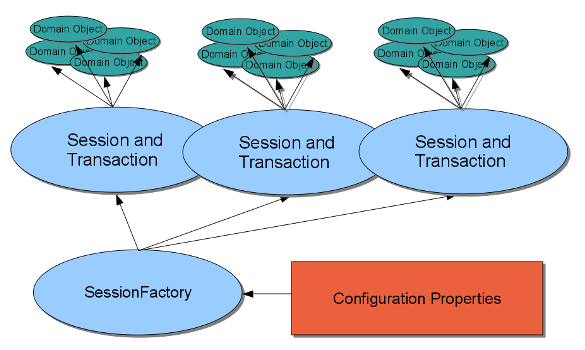
The SessionFactory is configured by a
properties object that might have been loaded from a file or
constructed dynamically by the application using some other means
(see Section 4.2.2.1, “Executing ClusterJ Applications and Sessions”).
The application obtains Session instances from
the SessionFactory, with at most one thread
working with a Session at a time. A thread can
manage multiple Session instances if there is
some application requirement for multiple connections to the
database.
Each session has its own collection of domain objects, each of which represents the data from one row in the database. The domain objects can represent data in any of the following states:
New; not yet stored in the database
Retrieved from the database; available to the application
Updated; to be stored back in the database
To be deleted from the database