MySQL 5.7 Reference Manual
MySQL 5.7 Release Notes
Table of Contents
- 7.1 NDB Cluster Replication: Abbreviations and Symbols
- 7.2 General Requirements for NDB Cluster Replication
- 7.3 Known Issues in NDB Cluster Replication
- 7.4 NDB Cluster Replication Schema and Tables
- 7.5 Preparing the NDB Cluster for Replication
- 7.6 Starting NDB Cluster Replication (Single Replication Channel)
- 7.7 Using Two Replication Channels for NDB Cluster Replication
- 7.8 Implementing Failover with NDB Cluster Replication
- 7.9 NDB Cluster Backups With NDB Cluster Replication
- 7.10 NDB Cluster Replication: Bidirectional and Circular Replication
- 7.11 NDB Cluster Replication Conflict Resolution
NDB Cluster supports asynchronous replication, more usually referred to simply as “replication”. This section explains how to set up and manage a configuration in which one group of computers operating as an NDB Cluster replicates to a second computer or group of computers. We assume some familiarity on the part of the reader with standard MySQL replication as discussed elsewhere in this Manual. (See Replication).
Note
NDB Cluster does not support replication using GTIDs;
semisynchronous replication and group replication are also not
supported by the NDB storage engine.
Normal (non-clustered) replication involves a source server
(formerly called a “master”) and a replica server
(formerly referred to as a “slave”), the source being
so named because operations and data to be replicated originate with
it, and the replica being the recipient of these. In NDB Cluster,
replication is conceptually very similar but can be more complex in
practice, as it may be extended to cover a number of different
configurations including replicating between two complete clusters.
Although an NDB Cluster itself depends on the
NDB storage engine for clustering
functionality, it is not necessary to use
NDB as the storage engine for the
replica's copies of the replicated tables (see
Replication from NDB to other storage engines).
However, for maximum availability, it is possible (and preferable)
to replicate from one NDB Cluster to another, and it is this
scenario that we discuss, as shown in the following figure:
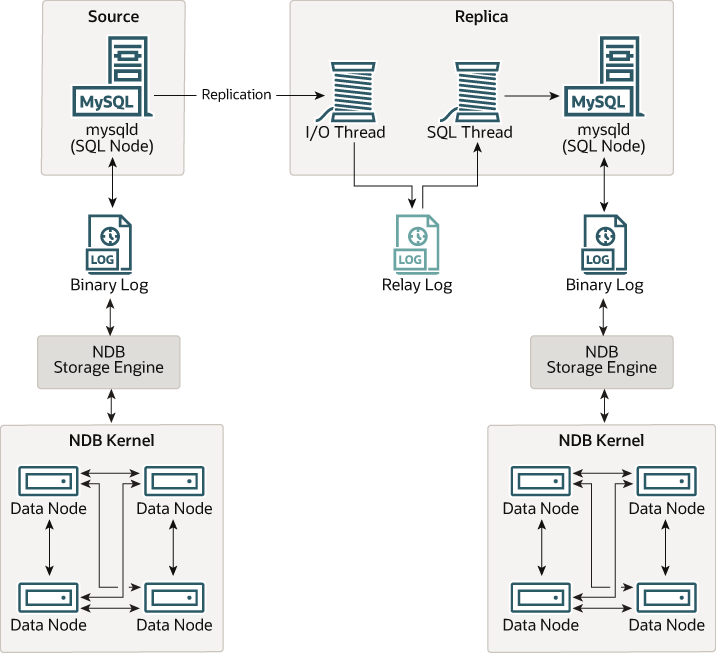
In this scenario, the replication process is one in which successive
states of a source cluster are logged and saved to a replica
cluster. This process is accomplished by a special thread known as
the NDB binary log injector thread, which runs on each MySQL server
and produces a binary log (binlog). This thread
ensures that all changes in the cluster producing the binary
log—and not just those changes that are effected through the
MySQL Server—are inserted into the binary log with the correct
serialization order. We refer to the MySQL source and replica
servers as replication servers or replication nodes, and the data
flow or line of communication between them as a
replication channel.
For information about performing point-in-time recovery with NDB Cluster and NDB Cluster Replication, see Section 7.9.2, “Point-In-Time Recovery Using NDB Cluster Replication”.
NDB API replica status variables.
NDB API counters can provide enhanced monitoring capabilities on
replica clusters. These counters are implemented as NDB statistics
_slave status variables, as seen in the output
of SHOW STATUS, or in the results
of queries against the SESSION_STATUS
or GLOBAL_STATUS table in a
mysql client session connected to a MySQL
Server that is acting as a replica in NDB Cluster Replication. By
comparing the values of these status variables before and after
the execution of statements affecting replicated
NDB tables, you can observe the
corresponding actions taken on the NDB API level by the replica,
which can be useful when monitoring or troubleshooting NDB Cluster
Replication. Section 6.14, “NDB API Statistics Counters and Variables”,
provides additional information.
Replication from NDB to non-NDB tables.
It is possible to replicate NDB
tables from an NDB Cluster acting as the replication source to
tables using other MySQL storage engines such as
InnoDB or
MyISAM on a replica
mysqld. This is subject to a number of
conditions; see
Replication from NDB to other storage engines, and
Replication from NDB to a nontransactional storage engine,
for more information.