A previous blog post exposed the main factors affecting Group Replication performance, which was followed by another that showed the scalability of both single-master and multi-master throughput. In this post we return with more “inside information” that may be useful for optimizing the performance of Group Replication deployments.
1. End-to-end throughput in Group Replication
Group Replication’s basic guarantee is that a transaction will commit only after the majority of the members in a group have received it and agreed on the relative order between all transactions that were sent concurrently. After that, it uses a best-effort approach that intrinsically makes no assumptions regarding when transactions will be applied or even touch storage on the group members.
The above approach works well if the total number of writes to the group does not exceed the write capacity of any member in the group. But if some of the members have less write throughput than total capacity needed to handle all the writes, those members will start lagging behind of the others.
1.1. Proper infrastructure sizing
It probably goes without saying, but we’ll stress it anyway: in a distributed system such as GR having proper sizing of the components is very important and the throughput of a single component is not representative of the output of the replication topology as a whole. In fact, sometimes improving the throughput of some servers can even be counter-productive: if the remaining servers cannot keep up with the workload the bottlenecks just move away from the client-facing server to the rest of infrastructure at possibly higher costs.
With that out of the way, to avoid slave lag – in GR all members are slaves of the other members’ workload – one must consider the throughput demanded from each component and the fact that slave lag is composed of two parts: the time it takes for a transaction to cross the replication pipeline (going from the client-facing server to the other members) and the time it spends waiting, somewhere in that pipeline, for previous transactions to be applied.
So the main goal sizing such a system is assuring that the slave lag is not significantly larger than what is strictly necessary for the transactions to cross the replication pipeline, and, particularly, that it does not grow over time.
1.2. Peak and sustained throughput
When the client-facing members in the replication system do, in fact, experience a workload that exceeds what the remaining members in the network topology can handle there are two choices:
-
the users let the servers accept the extra workload because it is known that it will eventually return to manageable levels before exhausting the buffering resources;
-
the user enables the flow-control mechanism so that, if needed, the servers delay the clients to keep the workload within bounds that are acceptable for all servers in the group.
A big drawback of letting the queues grow is that stale data is served by those that have pending updates to be installed. Also the system becomes less efficient because of the buffering, and in multi-master scenarios where conflicting workloads are sent to multiple members having a queue with many transactions waiting to apply will increase the likelihood of transactions being rejected. It is nevertheless well supported just like in asynchronous replication.
The advantage of one, or the other, will end up depending on how stable or bursty the workloads are, on how long the burst periods last and on what are the fault tolerance requirements. To reflect this duality, we focus both the peak throughput – the throughput of the client-facing server unimpaired by slower members having to keep-up with it – and the sustained throughput – the rate the whole group can withstand without having members lag behind. Using both metrics allows a better view of the system capabilities and the effect of optimizations targeted at improving one or the other.
2. Multi-master implications
2.1. Dealing with conflicting workloads
Group Replication introduces the ability to accept updates on any member in the group. Any incompatible changes are rolled-back when the certification process detects an overlap by checking which rows are changed by each transaction, while the other changes are committed in the local member or sent to the relay log to apply on the remote members.
Updating very often the same rows from multiple servers will bring with it many roll-backs. In fact, if several servers update the same row consecutively, one server will succeed first and the other members will get the transaction in the relay log. While the transaction is in the relay log of some members waiting to be applied after being checked for conflicts, any transaction that uses the rows in those members will be rolled-back eventually. But the first server is not bound by the same problem, so it may continue to get its transactions through the conflict check, and the other members will continue to receive transactions that are stored in the relay log. So issuing the same transaction repeatedly may not be advantageous or enough to get transactions through. Especially if the first member changes that hot data so frequently leaving others not enough time to update their copy of the data, effectively widening conflict window for them.
Let’s make it a rule: to prevent conflicts in Group Replication the next update to a given row can’t be done before the slowest member applies the current update. Otherwise, the next update should go through the same member where the current update is being done.
2.2. Multi-master write scalability
In some circumstances sending transactions to multiple members may provide higher throughput than sending them to a single server, which provides a small degree of write scalability. While this depends on how conflicting the workloads are, the improvement comes mostly from the following:
-
Using more members provides higher read capacity, which helps when transactions both read and write to the database;
-
Applying transactions in row-based replication consumes less resources than executing the SQL code directly.
The benefit may be smaller when the number of transaction aborts is high, as explained in 1.1, and the write scalability is more significant on peak throughput, the gains in sustained throughput are less pronounced.
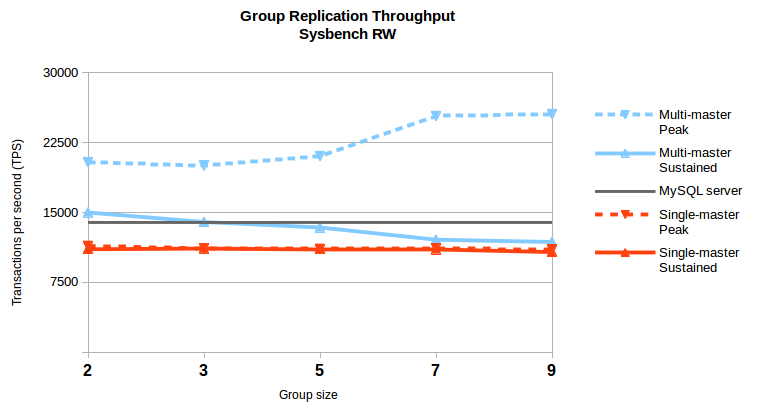
The chart above (repeated from here) presents precisely this conundrum. The dashed lines represent peak throughput, both from single-master and from multi-master configurations, going from groups of 2 to 9 members servers. The value presented is the highest throughput reached (still, the median of runs) in any client count configuration, so in some cases the configuration with highest throughput may be with 100 threads and in another with 70 threads). It shows simultaneously two interesting things:
-
writing to more than one server is beneficial in the tested configuration;
-
the peak throughput grows with the group size in multi-master configurations but the same does no hold for the sustained throughput;
In this case the workloads in each writer uses different tables, but that’s not necessary as long as the number of transaction aborts is not high. So, while there is potential for some write scalability with multi-master, evaluate how effective it is considering the number of expected transactions aborts and the rule in 2.1.
3. Group Replication slave applier implications
Remote transactions are sent to the relay log of each member once a transaction becomes positively certified, and then applied using the infrastructure from asynchronous and semi-synchronous replication. This implies that the slave applier is instrumental to converting the peak into sustained throughput: which mostly implies using effectively the MTS applier with enough threads to handle the received workload.
3.1. Writeset-based transaction dependency tracking
With asynchronous replication the LOGICAL_CLOCK scheduler uses the binary log group commit mechanism to figure out which transactions can be executed in parallel on the slave. Large group commits can lead to high concurrency on the slave, while smaller groups make it much less effective. Unfortunately, both very fast storage and reduced number of clients make commit groups smaller – hence less effective. The storage speed implication can be circumvented with the option binlog-group-commit-sync-delay, but there is no way to circumvent the low-client counts because a group commit cannot include two transactions from the same client. This is an issue mainly in multi-level replication topologies, as we typically have less applier threads than user threads and that means that less parallelism reaches the lower-level slaves.
Group Replication takes a very different approach for marking which transactions can be applied in parallel in the slave, one that does not depend on the group commit mechanism. It takes into account the writesets used to certify transactions in each member and builds dependencies according to the order of certification and the database rows the transactions change. If two transactions share rows in their writesets, they cannot run in parallel in the slave, so last one to use the rows becomes dependent on the previous ones.
Writeset-based dependency tracking allows a significantly higher degree of parallelism, particularly on low-concurrency workloads. In fact, it becomes possible to apply transactions with more threads than those used when they were applied in the master, even on single-threaded workloads. In some situations where a member would start lagging behind the mutl-threaded applier is now able to compensate with higher parallelism once the workload starts to clump. This “secret weapon” allows the multi-threaded applier to achieve high throughput even when the asynchronous replication applier would not be very effective, in a mechanism that makes slave-lag much less of an issue. Note, however, that if the number of clients becomes large enough the performance becomes close to what is already possible with MTS in asynchronous replication.
Writeset-based dependency tracking can also bring reordering of transactions from the same session, which implies that two transactions from the same session can appear to have been committed in the slaves in reversed order. At the cost of a small performance penalty we opted to make the use of the slave-preserver-commit-order option mandatory to keep session history consistent on the slaves, and in fact the full master history.
The chart that follows shows the potential of the writeset-based approach.
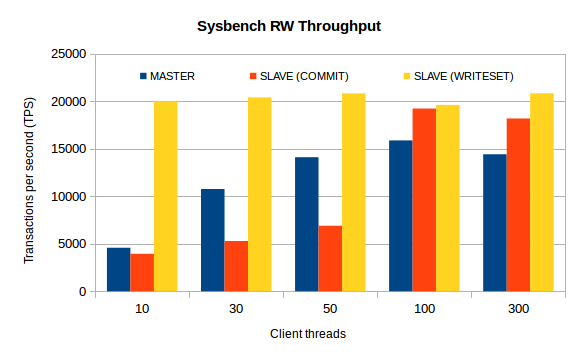
Illustration 2: Comparison of master and slave throughput on Sysbench RW, using both commit order and writeset dependency tracking
Main observations:
-
with commit-order the slave throughput increases as the number of server threads increases, but at low client count the slaves cannot keep-up with the master;
-
with writeset-based dependencies the applier throughput is almost constant as the number of server threads increases and it is always above what is achieved when using commit-order-based dependencies.
3.2 Applier threads effect on peak and sustained throughput
As mentioned before, the sustained throughput depends on all components of the system, and very particularly the number and effectiveness of the slave applier threads. To provide some insight as to its consequences, the following chart shows the peak and sustained throughput when using a combinations of writer members and MTS applier threads (the system configuration is the one described here).
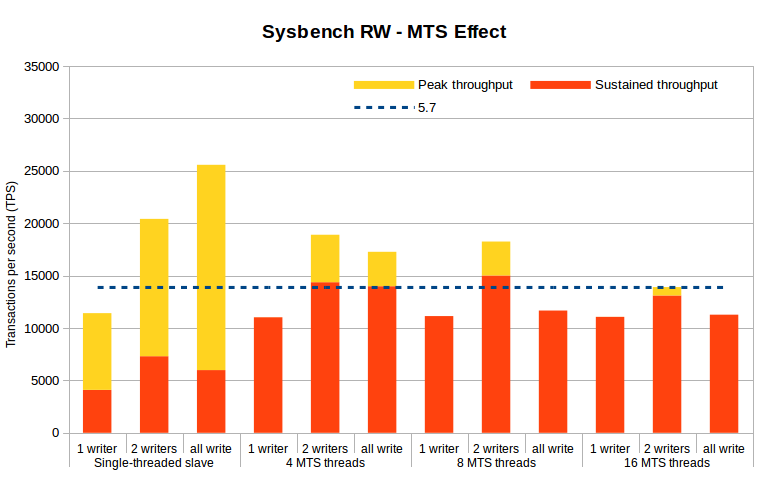
In this chart we test writing from one server, from two servers and from all servers in a group, going from the same 2 to 9 group members, taking the highest throughput of any thread combination. We highlight the following observations:
-
The highest peak throughput is achieved when all members write to the group but only one applier thread is used in each member; this is explained because the servers are spending less resources on the applier and leaving more capacity to buffer and apply local transactions;
-
with a single-master configuration, 4 threads are enough to keep up with the master, although there is enough capacity left in the system that can be used by a second master;
-
The largest number of masters does not convert to the highest throughput, in the configurations tested the peak in sustained throughput was achieved with two masters.
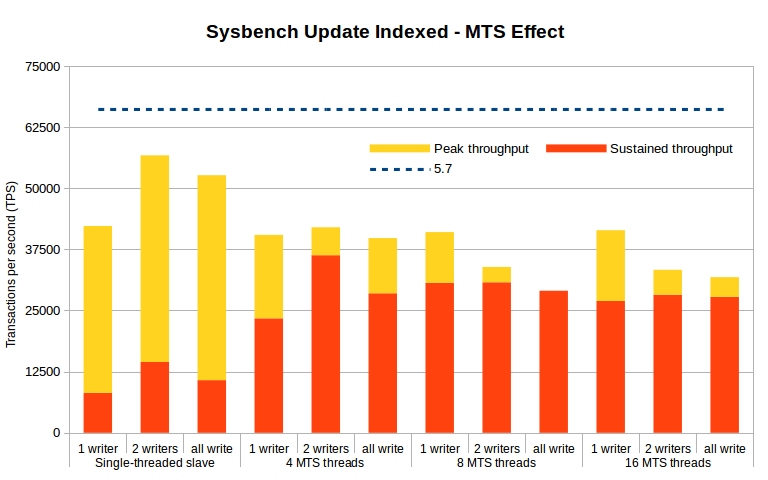
The following chart shows similar pattern, now resulting from the Sysbench Update Index benchmark.
4. Performing flow-control in Group Replication
Group Replication introduced flow control to avoid excessive buffering and to maintain group members reasonably close to each other. For several reasons, it’s more efficient to keep buffering low but, as mentioned before, it is not a requirement that members are kept in sync for replication to work: once a slave becomes delayed it will just increase the number of pending transactions in the relay log.
The flow control mechanism enters the scene to bound how much back-log group members can accumulate, in terms of transactions to certify and to apply. Once those bounds are exceeded, and while they remain exceeded, the flow-control system limits the throughput of writer members to adjust to the capacity of the slowest members of the group. By imposing conservative bounds it tries to make sure all members are able to keep-up and can return safely to within the bounds defined by the user.
The flow-control system works asynchronously, the capacity to use per period is calculated in each member, in each period, using the statistics that are regularly sent to the group by its members. The coordination is purposely kept coarse-grained, in order to reduce the number of messages in flight and to keep the system running as smoothly as possible, but it also means that small thresholds are not effective.
Flow control takes into account two work queues: the certification queue and the binary log applier queue, so a user may choose 1) doing flow control at the certifier or at the applier level, or both and 2) what is the trigger size on each queue. The following variables are used:
|
1 |
flow-control-mode=QUOTA* | DISABLED |
|
1 |
flow-control-certifier-threshold=25000* | 0..n |
|
1 |
flow-control-applier-threshold=25000* | 0..n |
The implementation depends on two basic mechanisms: 1) monitoring the servers to gather statistics on throughput and queue sizes of all group members to make educated guesses on what is the maximum write pressure each member can withstand and 2) throttling the servers to avoid writing beyond its fair-share of the capacity available in each step.
Further information about the inner workings of flow control is available here.
5. Wrap-up
This post tries to provide more details on things that may affect Group Replication performance. Next we will focus specifically on the multi-master behaviour.
Stay tuned!