In this blog post we will present a first look at the performance of Group Replication (GR), now that the RC is out. The goal is to provide some insight on the throughput, latency and scalability one can expect in a modern computing infrastructure, using GR in single- and multi-master configurations, but mostly focused on single-master.
→ If you’re in a hurry, here’s the summary: the performance of GR is great!
1. The basics of how it works
GR introduces the ability to make MySQL servers collaborate and provide a true multi-master architecture where clients can write to the database through any of the members of a GR group. The master-slave model of traditional replication is now replaced with a peer-to-peer model in which all servers are masters of their clients workloads.
Servers in a distributed database system must unequivocally agree on which database changes are to be performed and which are to be refused, independently of the server a client connects to or the moment in which he does it. When a transaction is ready to commit, the changes are sent by the client-facing member to all other members in a totally ordered broadcast message using a group communication system based on Paxos. After the changes are received and certified by the members, and if no incompatibilities arise, the changes are committed on the client-facing member and asynchronously applied on the remaining members.
For more information regarding what is going on behind the scenes, from a performance point of view, please check this post: /tuning-mysql-group-replication-for-fun-and-profit/
2. Throughput and scalability
The following charts present the throughput achieved by Sysbench RW and Update Indexed using GR with several group sizes, comparing it to a standalone MySQL server (with the binary log active). This will allows us to show GR’s behaviour on a well known workload but, as any synthetic benchmark, it is no proper replacement for testing with the actual workloads and infrastructure that will be used in each actual deployment.
We measured both the peak throughput – the best that the clients can get from the client-facing servers (with flow-control disabled) – and the sustained throughput – the best the system as a whole can withstand in the long run without having some of the members lagging behind the others. For these first charts we use the best throughput achieved in any thread combination.
Sysbench Read-Write throughput
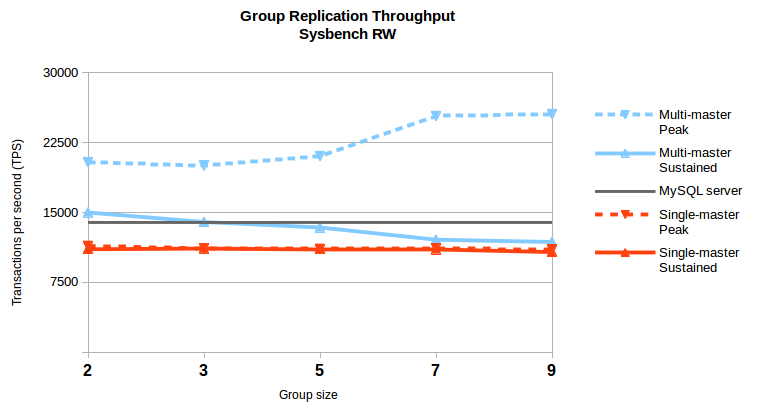
This chart shows several points that make us quite proud:
-
When all write requests are directed to a single member (single-master) GR achieves around 80% of the throughput of a standalone MySQL server, dropping only slightly (3%) when going from groups of 2 members up to 9 members (that’s the largest group supported for now);
-
When write requests are distributed between multiple members (multi-master), the sustained throughput can even be slightly larger than that of a standalone MySQL server and event with 9 server groups we can still get 85% of that;
-
Also we can get peak throughputs that almost double the capacity of a standalone server when using multi-master, if we disable flow-control and allow transactions to buffer and apply later;
-
Finally, on Sysbench RW the MTS applier on the members allows them to keep-up with the master (in single-master mode) even at the maximum throughput it can deliver.
Sysbench Update Index throughput
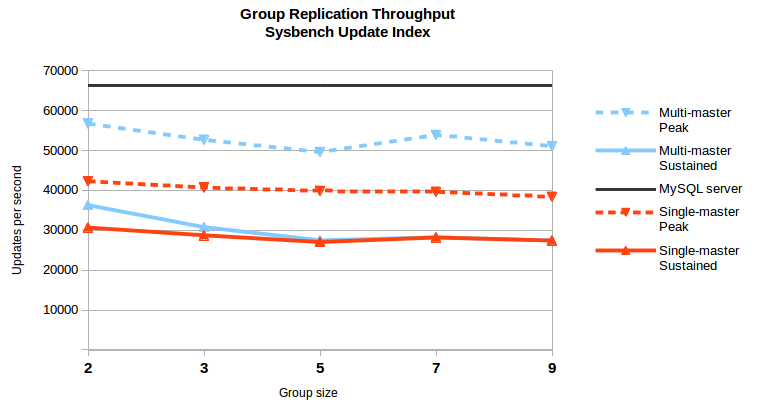
The Sysbench Update Index benchmark shows what happens with GR in workloads with very small transactions (more demanding for replication, with a single update per transaction in this case). With smaller transactions the number of operations that GR must handle is higher and the overhead on GR itself becomes proportionally larger.
Even in this scenario GR performs at very competitive levels. In particular, the scalability on the network is still great, and going from 2 to 9 members brings a very small degradation in both single-master and multi-master scenarios. Nevertheless, there is work to do to bring the sustained throughput closer to the peak and both closer to the standalone server.
The next sections expand on these numbers for the single-master case. A posterior blog post we will focus on the performance of multi-master configurations, including the balance/fairness between members, impact of conflicting workloads, etc.
3. Throughput by client (single-master)
Group Replication takes over a transaction once it is ready to commit and it only returns to the client once the certification is done, which happens after a majority of the members in the group agrees on an common sequence of transactions. This means that Group Replication is expected to increase the transaction latency and to reduce the number of transactions executed per second for the same thread count until the server starts reaching its full capacity. Once the number of clients is high enough to keep the server busy the added latency may be hidden entirely, but then scheduling many threads introduces its own overhead that limits that effect.
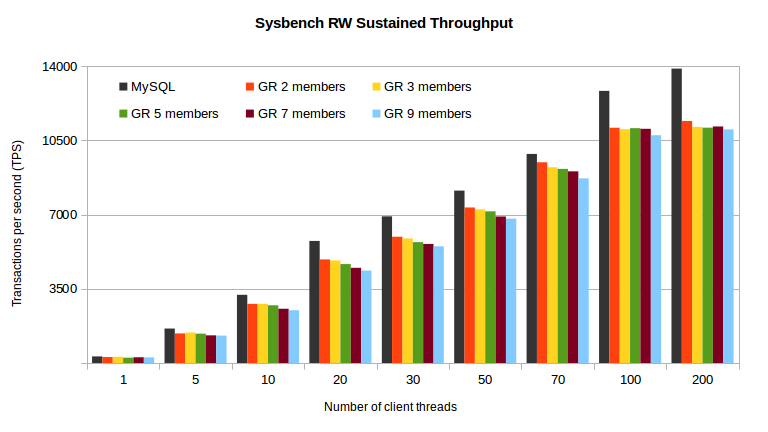
On the chart above one can see that at the same number of client threads there is a small gap between the number of transactions per second that GR and a standalone server can deliver. That gap is on average [12%-19%] between 2 – 9 members, but with 70 client threads the TPS gap between GR and the standalone server is very small (4%-11%). At their maximum throughput the difference between GR and a standalone server goes to 18%-21%, again from 2 to 9 member groups.
So, we are very please to see that GR is able to achieve around 80% of the standalone server performance on single-master configurations, even using the largest groups supported.
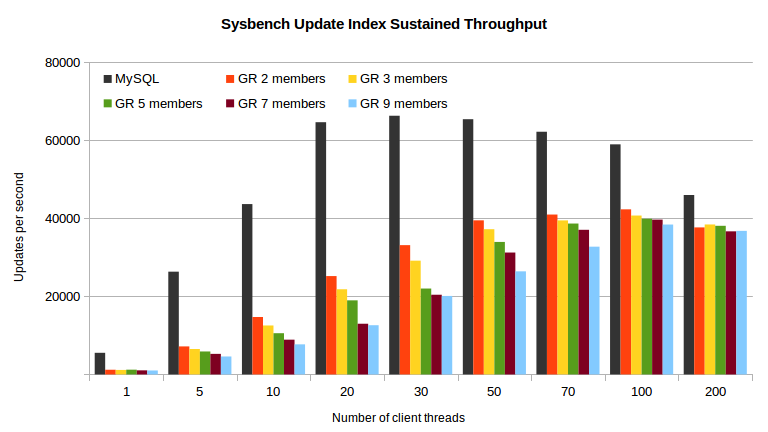
Even on very small transactions we are still able to achieve around 60% of the throughput of a standalone server. The latency gets hidden as we increase the number of clients, as on Sysbench RW, but the number transactions that need to go through certification and applied is much larger and becomes a limit in itself.
4. Transaction latency (single-master)
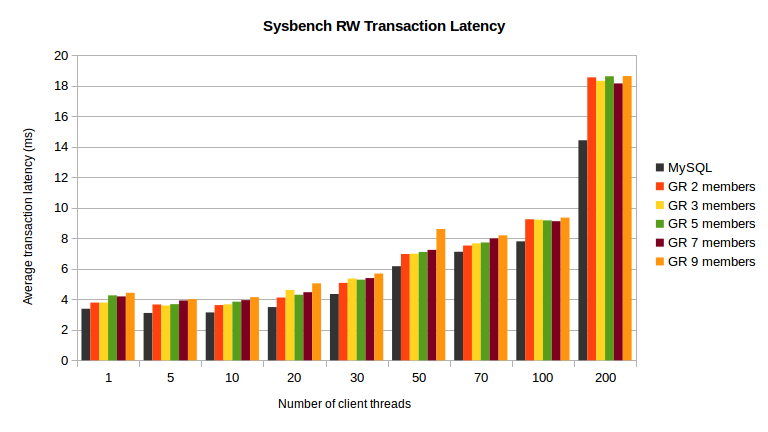
As mentioned above, the transaction latency was expected to grow with GR, but the chart above shows that in the tested system the Sysbench RW transaction latency increase is rather contained (16% to 30%, from 2 to 9 members).
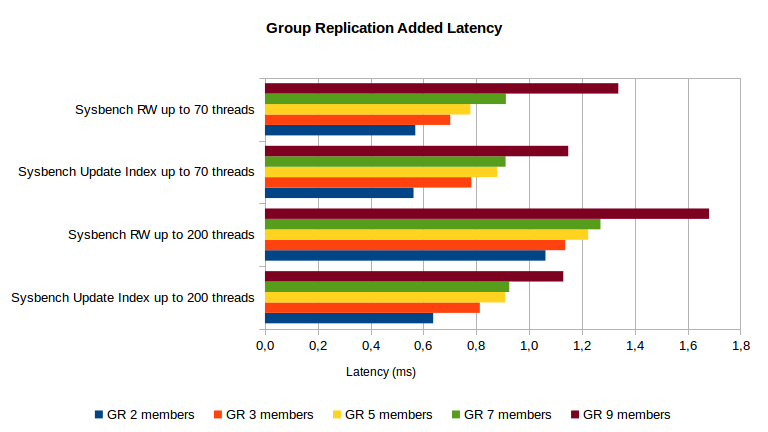
That latency increase depends mostly on the network, so the added latency changes only slightly between the Sysbench RW and the Sysbench Update Index, even if the payload sent is several times larger in Sysbench RW. The chart above shows that for this kind of workloads the latency increase is between 0.6ms to 1.2ms from 2 to 7 members, going up to 1.7ms with 9 members.
5. Benchmarking setup
In order to show GR throughput without interference from the durability settings we used sync_binlog=0 and innodb_flush_log_at_trx_commit=2 during the tests. In multi-master we used group_replication_gtid_assignment_block_size=1000000 and the results presented are from the highest from using 2 or all members of the group as writers of non-conflicting workloads.
The tests were executed using Sysbench 0.5 in a database with 10 million rows (the database fits in the buffer pool) and the median result of 5 runs is used.
The benchmark were deployed in an infrastructure constituted by 9 physical servers (Oracle Enterprise Linux 7, 20-core, dual Intel Xeon E5-2660-v3, with database and binary log placed on enterprise SSDs), with another server acting as a client (36-core, dual Intel Xeon E5-2699-v3), all interconnected by a 10Gbps Ethernet network.
6. Summary
We have spent quite a bit of effort optimizing the performance of Group Replication and this post presents a brief overview of the result now that the RC is being released.
Other performance-related posts will follow soon to focus specifically on the multi-threaded applier, on the group communication system itself and on multi-master scenarios.
Stay tuned!