The MySQL Development Team is happy to announce a new 8.0 Maintenance Release of MySQL Shell AdminAPI – 8.0.20!
Following the previous exciting release, on which InnoDB ReplicaSet was introduced, we focused on improving the management of ReplicaSets but also, most importantly, InnoDB cluster.
As usual, we would like to summarize what’s new so you get familiarized and eager to update MySQL Shell to the new version!
MySQL Shell AdminAPI
This release focused on management improvements for the AdminAPI, namely:
- Simplification and enhancement of the admin accounts handling: New commands to setup MySQL InnoDB cluster, ReplicaSet, and Router admin accounts.
- Integration of MySQL Shell with InnoDB ReplicaSet: Likewise for InnoDB Cluster, the Shell itself got extensions to provide ease-of-use when managing ReplicaSets.
- Making ReplicaSet operations mutually exclusive: Ensure that ReplicaSet operations are locked to avoid different operations to perform changes on the same ReplicaSet.
And as always, quality has been greatly improved with many bugs fixed!
Admin Accounts Management
The deployment of an InnoDB cluster, or ReplicaSet, involves setting up administration accounts. Those are required to:
- Administer the cluster/replicaset, through Shell’s AdminAPI.
- Bootstrap MySQL Router in a cluster/replicaset.
- Allow MySQL Router to operate in a cluster/replicaset.
Even though the DBA is free to use the root account for such operations, the recommended action is to create accounts with the bare-minimum set of privileges to operate an InnoDB cluster or ReplicaSet.
For that purpose, the AdminAPI provides users with a very easy method to accomplish that:
- Using
dba.configureInstance()with theclusterAdminoption.
As an example, a typical setup of an InnoDB cluster would consist of the following sequence of steps:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
mysql-js> // Configure the instances for IDC usage + create admin account mysql-js> dba.configureInstance("root@instance1:3306", {clusterAdmin: "myAdmin"}); mysql-js> dba.configureInstance("root@instance2:3306", {clusterAdmin: "myAdmin"}); mysql-js> dba.configureInstance("root@instance3:3306", {clusterAdmin: "myAdmin"}); mysql-js> mysql-js> // Connect using the newly created admin account and create the cluster mysql-js> \c myAdmin@instance1:3306 mysql-js> var cluster = dba.createCluster("myCluster"); mysql-js> mysql-js> // Add the instances to the cluster mysql-js> cluster.addInstance("myAdmin@instance2:3306"); mysql-js> cluster.addInstance("myAdmin@instance3:3306"); mysql-js> mysql-js> // Exit mysqlsh and bootstrap the Router mysql-js> \quit Bye! |
|
1
2
|
$ mysqlrouter --bootstrap myAdmin@instance1:3306 ... |
IMPORTANT: The clusterAdmin username and password must be the same on all instances that belong to a cluster. For that reason, every time a new instance is added to the cluster, the DBA must ensure that the account exists on the target instance.
Remember: For each bootstrap done, a new internal router account is created.
Frequent obstacles
Considering the above, the following scenarios became common in any production HA environment:
- Creating multiple
clusterAdminaccounts, or using different passwords for the same account, leading to failures when configuring the cluster. - The Exponential growth of Router admin accounts, considering that several Router instances have to be deployed – An undesirable and possible security risk.
Having that in mind, and also the recurring concern of providing the most simple but powerful AdminAPI, we have simplified the whole accounts management.
New approach
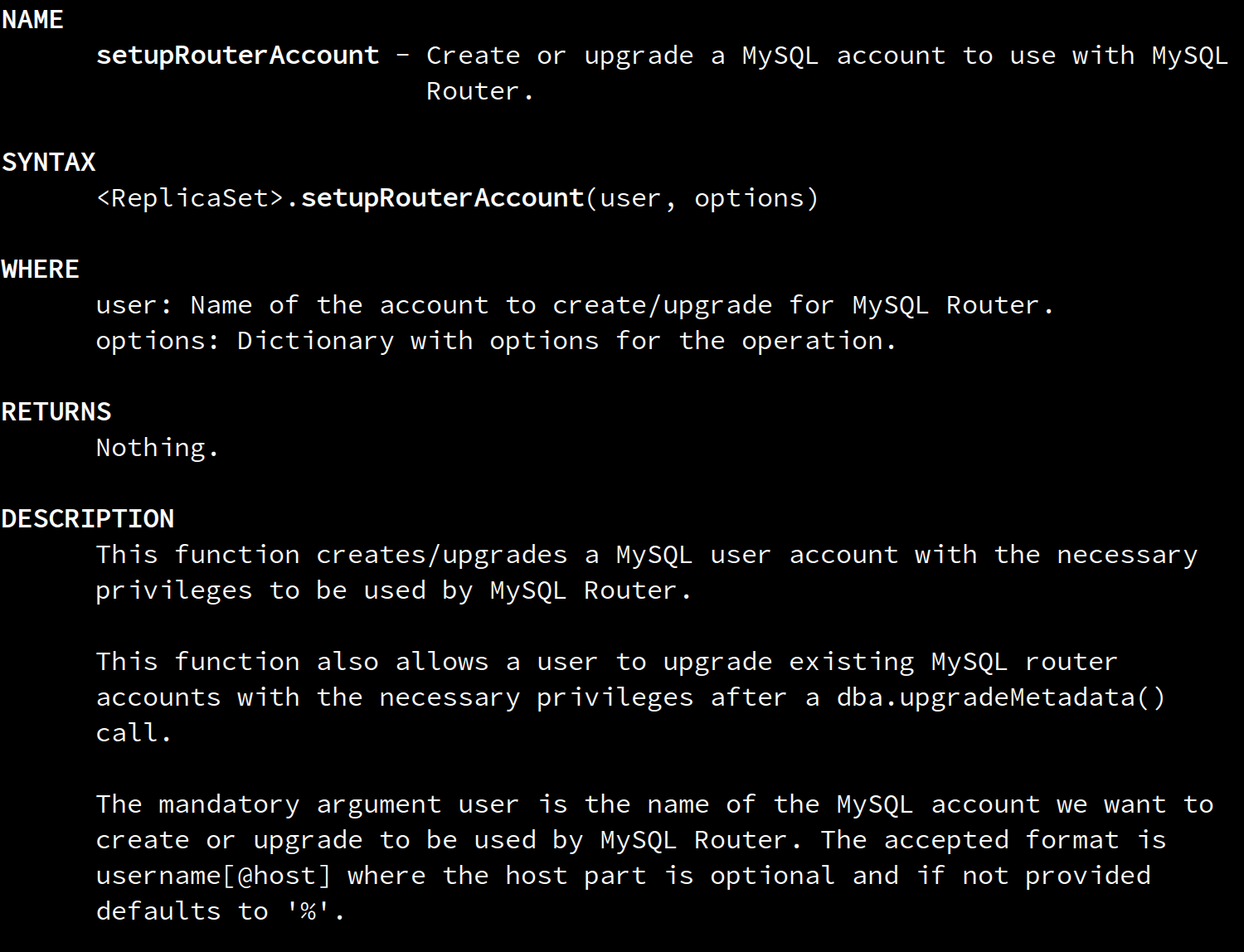
In this release, you’ll be able to use the following new commands:
<Cluster>.setupRouterAccount(user, [options])<Replicaset>.setupRouterAccount(user, [options])
… to set up a centralized Router admin account, per cluster/replicaset, avoiding the growing number of accounts, and any necessary actions to clean-up unused accounts.
And, the following new commands:
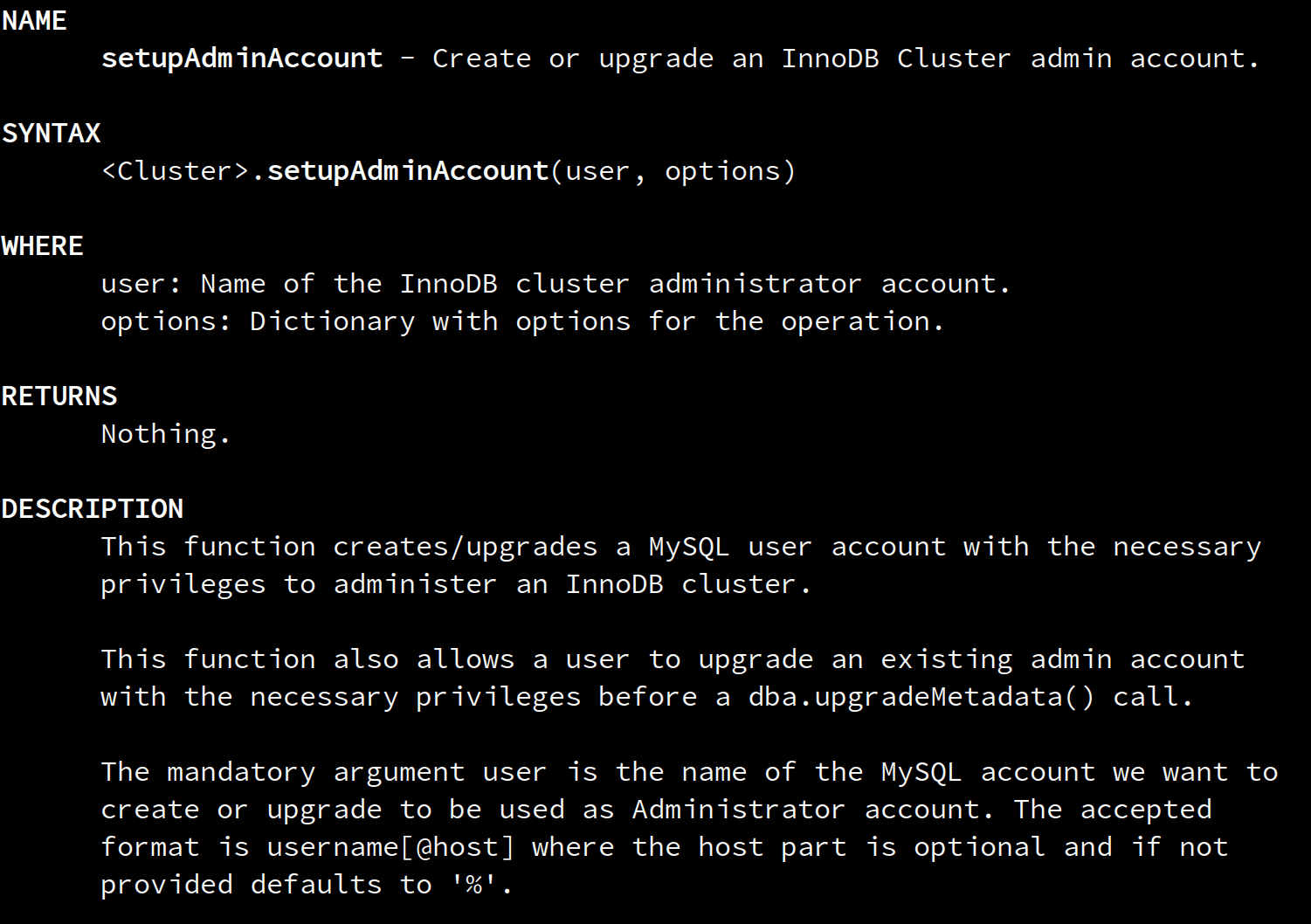
<Cluster>.setupAdminAccount(user, [options])<Replicaset>.setupAdminAccount(user, [options])
… to set up a centralized cluster/replicaset admin account, avoiding the need of creating clusterAdmin accounts on every cluster member, with the same credentials.
Reformulating the typical sequence of steps to set up an InnoDB cluster into the following:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
mysql-js> // Configure the instances for IDC usage mysql-js> dba.configureInstance("root@instance1:3306") mysql-js> dba.configureInstance("root@instance2:3306") mysql-js> dba.configureInstance("root@instance3:3306") mysql-js> mysql-js> // Connect to the target instance and create the cluster mysql-js> \c root@instance1:3306 mysql-js> var cluster = dba.createCluster("myCluster") mysql-js> cluster.addInstance("root@instance2:3306"); mysql-js> cluster.addInstance("root@instance3:3306"); mysql-js> mysql-js> // Create a cluster admin account mysql-js> cluster.setupAdminAccount("clusterAdmin") mysql-js> mysql-js> // Connect using the newly created cluster admin account and do the cluter management/setup mysql-js> \c clusterAdmin@instance1:3306 mysql-js> var cluster = dba.getCluster() mysql-js> mysql-js> // Create a Router admin account mysql-js> cluster.setupRouterAccount("routerAccount"); mysql-js> mysql-js> // Exit mysqlsh and bootstrap the Router using the newly created Router admin account mysql-js> \quit Bye! |
|
1
2
|
$ mysqlrouter --bootstrap clusterAdmin@instance1:3306 --account=routerAccount ... |
New Metadata handling privileges
With the new metadata schema and upgrade feature introduced in 8.0.19, the current set of privileges given to the clusterAdmin accounts created using dba.configureInstance() became insufficient.
In order to allow users to upgrade their current clusters to the latest metadata schema, using the same clusterAdmin accounts, the new commands can also be used to update the accounts to include all the required privileges. That’s accomplished by making use of the update option:
|
1
2
3
4
5
|
mysql-js> // Update the clusterAdmin accounts privileges mysql-js> cluster.setupAdminAccount("myAdmin@instance1", {update: true}); ... mysql-js> cluster.setupAdminAccount("myAdmin@instance2", {update: true}); ... |
MySQL Shell integration with ReplicaSet
Operating an InnoDB ReplicaSet requires a <ReplicaSet> object. So, likewise in InnoDB Cluster, the AdminAPI provides the dba.getReplicaSet() command that returns a handle to the ReplicaSet. However, for InnoDB cluster it is possible to start MySQL Shell with the cluster object already instantiated and populated by making use of the command-line parameter:
--cluster
This feature has now been ported to InnoDB ReplicaSet too! It’s now possible to start MySQL Shell and use the following command-line parameter to get a populated ReplicaSet object:
--replicaSet
Example:
|
1
2
|
$ mysqlsh --replicaset clusterAdmin@instance1:3306 |
NOTE: In order to successfully use the option, the Shell must be provided with an URI to a ReplicaSet member
As part of this port, we have also extended the following commands to support ReplicaSet:
-
--redirect-primary: Connect to the primary of the ReplicaSet; -
--redirect-secondary: Connect to a secondary of the ReplicaSet;
This is yet another step forward usability!
Safer InnoDB ReplicaSet management
The AdminAPI, as the control panel of InnoDB ReplicaSets, provides the most pleasant and easy-to-use solution for the users. However, it also has the responsibility of providing a safe environment for such management tasks.
Even though it should not be very common that several Shell instances are concurrently operating on the same ReplicaSet, it was possible and allowed. Such situations could lead to inconsistencies in both the Metadata and the replication machinery, resulting in unexpected or broken setups. For that reason, we have improved ReplicaSet operations to ensure that, when applicable, operations are mutually exclusive.
Let’s illustrate a catastrophic scenario, the DBAs John and Jane are both working on a the same ReplicaSet and at virtually the same time they do:
Peter:
|
1
2
|
mysql-js> // Primary switchover mysql-js> replicaset.setPrimaryInstance("instance2"); |
Triggering the next actions:
- The Metadata is updated and a topology change (view_id) is registered
- The “old” primary becomes read-only
Mary:
|
1
2
|
mysql-js> // Add a new instance to the ReplicaSet mysql-js> replicaset.addInstance("instance4"); |
Causing a failure due to one of the following:
- The Metadata update to include the new instance happens fails because the primary became R/O
- The topology change view_id in the metadata conflicts because it already exists one with the same ID.
And ultimately leading to an unexpected/unknown result.
But this is just an example of what can go wrong…
With this release, this is no longer a problem because ReplicaSet operations became mutually exclusive!
Locks to the rescue
We have implemented a locking mechanism for ReplicaSet operations that ensures no operations that alter the Metadata and/or ReplicaSet topology can be performed at the same time. The locks can be global or at the instance level.
In detail:
-
dba.upgradeMetadata()anddba.createReplicaSet()are globally exclusive operations. No other operations can be executed in the same ReplicaSet or any of its instances meanwhile those are being executed. - <
ReplicaSet>.forcePrimaryInstance()and <ReplicaSet>.setPrimaryInstance()are operations that change the primary so special attention is required. The approach taken ensures that no other operations that change the primary or instance updates can be executed until the first operation completes. - <
ReplicaSet>.addInstance(), <ReplicaSet>.rejoinInstance(), and <ReplicaSet>.removeInstance()are operations that change an instance. A lock at instance level was implemented for those operations, ensuring that an operation can be performed at a time per instance, but allowing multiple operations to happen in different instances at the same time.
Notable Bugs fixed
For the full list of bugs fixed in this release, please consult the changelog. However, there are some that deserve being mentioned.
Clone related bugs
With the integration of the MySQL Clone Plugin into InnoDB Cluster and ReplicaSet, provisioning became as easy-as-pie. This is by far one of the most crucial built-in technologies made available through the AdminAPI, ensuring provisioning is always available with blazing fast speed.
A few bugs were found that got special attention in this release.
BUG#30657911 – <REPLICASET>.ADDINSTANCE() USING CLONE SEGFAULTS WHEN RESTART IS NOT AVAILABLE
Using clone as the provisioning method to add an instance to a ReplicaSet resulted in a crash if the target instance did not support RESTART. This bug has been fixed in this release and the behavior of ReplicaSet.addInstance() was extended to reckon such scenario and whenever the operation timeout is reached the command aborts and reverts the changes.
NOTE: If not possible to upgrade the instance to a version that supports RESTART, the user can manually perform the RESTART and then issue
<ReplicaSet>.addInstance()again, that will use incremental recovery and won’t require a subsequent restart.
BUG#30866632 – TIMEOUT FOR SERVER RESTART AFTER CLONE TOO SHORT
When a clone is performed to provision an instance, a restart is required to complete the process. During that restart, the backlog of transactions is applied to the instance, and depending on the size of that backlog, the process may take more or less time. For servers that apply a very large backlog of transactions, the default timeout of 60 seconds could not be sufficient.
For that reason, a new Shell global option dba.restartWaitTimeout was added to allow users to set a proper value for the restart timeout.
|
1
2
3
4
|
mysql-js> // Check the current options in place mysql-js> shell.options mysql-js> // Change the value of dba.restartWaitTimeout mysql-js> shell.options.set("dba.restartWaitTimeout", 300); |
BUG#30645697 – RECOVERYMETHOD:CLONE WHEN ALL MEMBERS ARE IPV6 WILL ALLOW ERRANT GTIDS
One of the possible use cases for clone is to allow adding an instance with a diverged GTID-set to a cluster. However, MySQL Clone plugin has a limitation in regards to IPv6 usage. Specifically, if all members of a cluster are using IPv6, no donor can be used since Clone does not support using IPv6 addresses for the valid donors list. Thereby, in a scenario on which all members are using IPv6 and clone was selected, clone would fail and fall-back to incremental recovery.
Ultimately, the instance would be added to the cluster using incremental recovery, but due to the diverged GTID-set the instance would not be accepted in the cluster.
This has been improved by implementing a new check to disallow the usage of clone as the recovery method when all cluster members are using IPv6 addresses.
InnoDB Cluster related bugs
InnoDB Cluster, as the main MySQL HA solution got the spotlight on with several bug fixes:
BUG#30739252 – RACE CONDITION IN FORCEQUORUM
In some particular situations on which <Cluster>.forceQuorumUsingPartitionOf() was used to unblock a cluster that lost its quorum, an undefined and unexpected behavior happened causing inconsistencies in the cluster. Those situations were only seen when autoRejoinTries had a value higher than zero.
This was caused by a bug on the AdminAPI that missed to stop Group Replication on any reachable instances that were not part of the visible membership of the target instance. This has been fixed by ensuring Group Replication is stopped in those instances.
BUG#30661129 – DBA.UPGRADEMETADATA() AND DBA.REBOOTCLUSTERFROMCOMPLETEOUTAGE() BLOCK EACH OTHER
The previous 8.0.19 release introduced InnoDB ReplicaSet and a new version of the Metadata Schema. To allowing rolling upgrades, a command to upgrade the metadata was also added.
If a cluster that was created using a Shell version lower than 8.0.19 goes completely offline and an upgrade of the Shell is performed, rebooting the cluster from a complete outage and upgrading the metadata schema are both required. However, due to this bug that was impossible and the user would face a “chicken-egg” problem since the commands would block each other from executing.
This has been fixed in this release, by changing the preconditions of the following commands to allow their operation even if the metadata schema requires an upgrade:
dba.rebootClusterFromCompleteOutage()<Cluster>.forceQuorumUsingPartitionOf()
BUG#30501628 – REMOVEINSTANCE, SETPRIMARY ETC SHOULD WORK WITH ANY FORM OF ADDRESS
<Cluster>.removeInstance() performed some validations to ensure the instance being removed is actually part of the cluster’s metadata. But in some particular scenarios, that was not enough causing failures.
For that reason, <Cluster>.removeInstance() was improved to allow removing an instance from a cluster on which report_host does not match what’s registered in the Metadata but the address (IP) given in the command does.
BUG#30625424 – REMOVEINSTANCE() FORCE:TRUE SAYS INSTANCE REMOVED, BUT NOT REALLY
Similarly to the previous bug, it was not possible to remove an OFFLINE but reachable instance from a cluster when a different address than the one registered in the Metadata was used. That has been fixed in this release, allowing the removal of such instances using the force option.
BUG#29922719 and BUG#30878446 – REPLICATION COORDINATES LEFT BEHIND AFTER REMOVEINSTANCE
After the successful removal of an instance from a cluster, the replication channels that were used by Group Replication still existed allowing the information to replication coordinates and others. This was fixed in this release by ensuring the following channels are reset after Cluster.removeInstance() or Cluster.dissolve():
- group_replication_applier
- group_replication_recovery
InnoDB ReplicaSet related bugs.
And finally, InnoDB ReplicaSet also got an important bug fixed:
BUG#30735124 – INNODB REPLICASET: ADMINAPI TAKES WRONG MEMBER AS HAVING LATEST VIEW/PRIMARY
In a very particular situation, it could occur that the AdminAPI would pick an invalidated member as the latest primary of a ReplicaSet leading to errors in the subsequent operations. The root cause of this issue was the process of getting the primary of the InnoDB ReplicaSet that was incorrectly reconnecting to an invalidated member if it was the last instance in the InnoDB ReplicaSet. That has been fixed and the AdminAPI always ensures the right primary is selected.
Try it now and send us your feedback
MySQL Shell 8.0.20 GA is available for download from the following links:
- MySQL Community Downloads website: https://dev.mysql.com/downloads/shell/
- MySQL Shell is also available on GitHub: https://github.com/mysql/mysql-shell
And as always, we are eager to listen to the community feedback! So please let us know your thoughts here in the comments, via a bug report, or a support ticket.
You can also reach us at #shell and #mysql_innodb_cluster in Slack: https://mysqlcommunity.slack.com/
The documentation of MySQL Shell can be found in https://dev.mysql.com/doc/mysql-shell/8.0/en/ and the official documentation of InnoDB cluster and InnoDB ReplicaSet can be found in the User Guide.
The full list of changes and bug fixes can be found in the 8.0.20 Shell Release Notes.
Enjoy, and Thank you for using MySQL!