As announced in the previous blog post, MySQL InnoDB Cluster just got a very much requested feature which makes a complete, out-of-the-box, easy-to-use and versatile HA solution – Automatic Node Provisioning.
InnoDB cluster users can now rely on it for every single step of cluster deployment and management. From instance configuration to provisioning, to cluster set up and its monitoring. By using the MySQL Shell and its AdminAPI, every step becomes easily accessible within the same place with a complete set of powerful yet simple commands.
The screencast shown previously demonstrates how effortless and appealing it is now to remotely provision a MySQL server, even with a substantial amount of data and no binlogs available to recover the joiner up to the latest point in time.
But what motivated us to build this feature? Why is it such a great enhancement over what we had until now and hows does the AdminAPI make things easier? Let’s find out!
Node provisioning
MySQL InnoDB Cluster relies on Group Replication to provide the mechanism to replicate data within clusters with built-in failover. A cluster consisting of a group of instances implements virtually synchronous replication, with built-in conflict detection/handling and consistency guarantees.
As you are probably aware by now, in order to achieve High Availability and provide fault tolerance up to one failure, an InnoDB cluster must have at least three members. Also, since Group Replication implements a group membership service, groups are elastic in the sense they can grow or shrink according to the user needs.
The Shell and its AdminAPI provide you with the most straightforward and easy way to manage a cluster topology to add or removes instances from it. However, to successfully accept a new member in a cluster, Group Replication requires that all are synchronized, i.e. the joining member has processed the same set of transactions as the other group members, which happens during the distributed recovery phase.
Distributed recovery
Group Replication implements a mechanism that allows a server to get missing transactions from a cluster so it can successfully join it. This mechanism is called distributed recovery and in MySQL 8.0.16 and earlier was solely based on a regular asynchronous replication channel between the joining instance and a cluster member, behaving as a donor. Needless to say that the classic asynchronous replication relies on binary logs and in order to synchronize the server up to a specific point in time, the process makes use of the MySQL Global Transaction Identifiers (GTIDs).
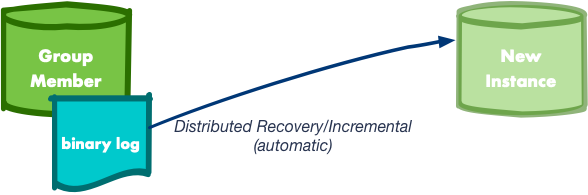
Sounds nice, right? It definitely is! However… What if the server has lost its binary logs? Or even, what if the cluster was created on a server which had plenty of data but the binary logs and GTID support were disabled? In such scenarios, the asynchronous replication channel won’t suffice… On top of that, the amount of data to send across and thus to consume on the receiver has a direct impact on the recovery time. Therefore, using binary logs to recover may take a considerable amount of time.
Manual Node provisioning
When distributed recovery using asynchronous replication was not possible, the instances had to be manually provisioned. That could be achieved by performing a backup of a cluster member and applying it on the joining instance. Logical backups can be done for small amounts of data, using, for example, mysqldump, but for large amounts of data, physical backups are required. MySQL Enterprise Backup, being the de facto tool for backups, is also an excellent resource commonly used to stage instances for InnoDB cluster usage.
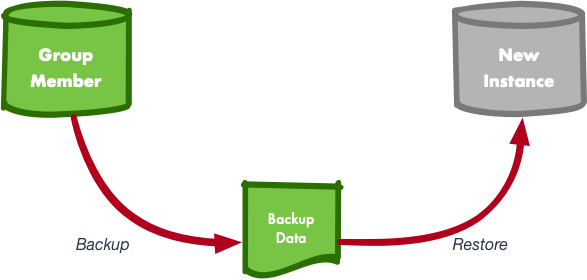
Nonetheless, the impact on usability is certainly huge, plus the time and knowledge required to perform such operations are quite impacting.
MySQL Clone Plugin: The missing link
With the introduction of built-in Clone support in MySQL, we could finally overcome such limitations and move towards the complete out-of-the-box HA solution.
The Clone Plugin, in general terms, allows taking physical snapshots of databases and transfer them over the network to finally provision servers. Thus it is a seamless and automated solution for doing a complete state transfer during the distributed recovery if needed, without having to resort to external tools.
Note: Clone completely overwrites the state of
the receiver with a physical snapshot of the donor.
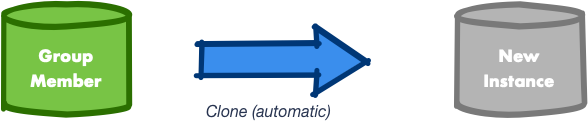
This is integrated and automated in the distributed recovery process of Group Replication and the MySQL Shell, as the control panel of InnoDB cluster, wraps it up in the AdminAPI to provide transparent handling, management, and monitoring through MySQL Shell.
MySQL Shell – Further raising the bar on usability
The AdminAPI has been extended to provide a smooth and pleasant experience whilst doing node provisioning. On top of that, several checks and prompts were added to guide the users through the most convenient and ideal path to accomplish their needs. Finally, monitoring of the whole provisioning process has been added too.
Which type of recovery shall be used?
Distributed recovery can now use two different mechanisms of data transfer to accomplish full recovery of instances:
- Incremental recovery (based on asynchronous replication channels)
- Clone-based recovery
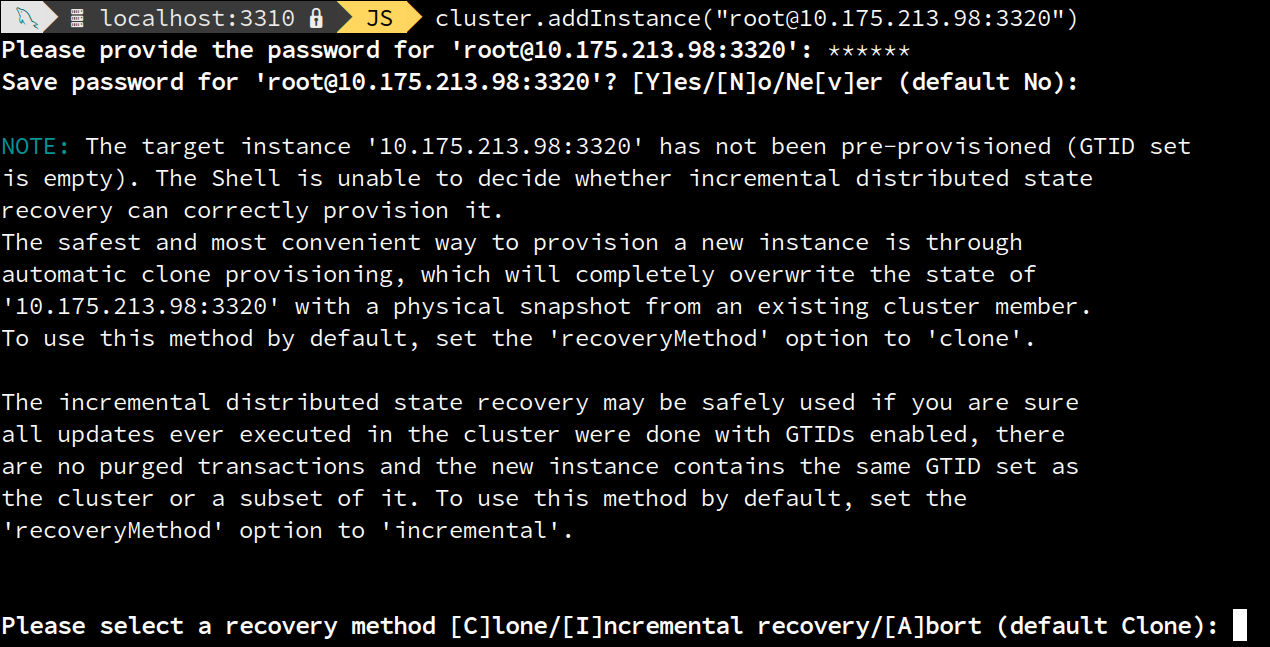
But which one shall be used and when? To answer those questions, the AdminAPI features now a built-in mechanism to detect which recovery mechanism is appropriate, considering the running cluster and the joining instance, and guiding the user through it.
The following state diagram illustrates the possible paths the AdminAPI can follow to determine the right approach regarding node provisioning.

In order to fully understand each step, we shall describe a few concepts:
Is incremental recovery possible?
By now, you should have a much clearer picture of how incremental recovery works and its limitations. To answer this question, we simply have to check if at least one of the cluster members can act as a donor on a standard asynchronous replication channel and provide the receiver with the same set of transactions it has processed. The donor’s binary logs are replicated allowing the joiner to obtain all missing data.
But… is it appropriate?
That’s when it gets tricky… Even though the donor could provide the data to the receiver, through the binary logs, what if:
- There are purged transactions?
- The joiner does not have an empty GTID set and that one is not equal or a subset of the donor’s GTID set?
- GTID support and binary logs weren’t always enabled?
If 1) and 2) is observed, the joiner instance will fail to be accepted in the cluster. As for 3), the instance would be able to join the cluster, however, its data will not be identical and may diverge further in the future.
For those reasons, the AdminAPI implements a set of checks to determine if there are any corner cases in place that violate the rules. For such cases, the user is prompted for an action, otherwise, the process is taken smoothly and transparently considering that Group Replication will handle recovery and automatically choose the best approach to recovery.
The checks implemented by the AdminAPI are accomplished by obtaining the GTID-sets of the cluster instances and the joiner and compare them to determine the GTID “state” of the instance:
-
New: empty
GTID_EXECUTED - Identical: GTID-set identical to the donor’s
- Recoverable: GTID-set is missing transactions but can be recovered from the donor
- Irrecoverable: GTID-set is missing purged transactions
- Diverged: GTID-sets have diverged
As you can conclude by now, we consider that incremental recovery is an appropriate data transfer mechanism if the joiner instance is determined to be either: “Identical” or “Recoverable”. For an instance considered “New”, we cannot consider incremental recovery applicable because it’s impossible to determine if the binary logs have been purged, or even if the GTID_PURGED and GTID_EXECUTED variables were reset. It may also be that the server already had data in it before binary logs and GTIDs were enabled.
When using the Shell, there’s no need to manually change any Group Replication configuration as the AdminAPI transparently handles it. However, for those corner cases requiring user action, please note that if group_replication_clone_threshold has been manually changed, then Group Replication might decide to use clone recovery instead.
When is clone supported?
Clone is supported as of today with MySQL 8.0.17 and if not explicitly disabled in the target cluster.
Note: All cluster members version must be 8.0.17 (minimum) to support the clone-based recovery.
The AdminAPI has been extended to automatically enable the clone usage, when available, upon cluster creation and topology changes. All the process is automated and transparently performed without any user intervention: plugin installation, the extension of recovery accounts grants to support clone usage, etc. On top of that, users are now given the option to disable clone usage when creating a cluster or even to disable/enable it on a running cluster.
API Changes
The API changes are minimal, though there are some relevant mentions. Namely, as mentioned before, a new option was added to dba.createCluster() to allow disabling the clone usage for a cluster:
disableClone
As a consequence, <Cluster>.setOption() was extended to allow changing the value of disableClone for a running cluster. Thus it is possible to disable the clone usage at any time or even to enable it in case it wasn’t.
Regarding the recovery mechanism to transfer data used in <Cluster>.addInstance(), by default, the AdminAPI handles it and guides the user accordingly, but there’s also the possibility of explicitly setting which one shall be used. For that reason, the command has been extended with a new option named 'recoveryMethod' that accepts the following values:
- incremental: uses solely an asynchronous replication channel to recover and apply missing transactions copied from another cluster member. Clone will be disabled.
- clone: start with a provisioning step using the built-in MySQL clone support, which completely replaces the state of the target instance with a full snapshot of another cluster member. Requires MySQL 8.0.17 or newer.
-
auto: let Group Replication choose whether or not a full snapshot has to be taken, based on what the target server supports and the
group_replication_clone_thresholdsysvar. This is the default value. A prompt will be shown if not possible to automatically determine a convenient way forward. If the interaction is disabled, the operation will be cancelled instead.
Progress Monitoring
Another dazzling aspect of this work is the monitoring features introduced in the AdminAPI. As it can perfectly be noted in the screencast shown previously, the pace of clone based recovery is now monitorable, by default, with real-time progress information.

This feature, apart from being very eye-appealing, it’s very useful. The progress monitoring happens asynchronously and can be safely interrupted in the Shell by pressing ctrl-c. The recovery process will continue normally even if you exit the shell.
At any moment, such progress information can be consulted with the regular means, that is using <Cluster>.status()
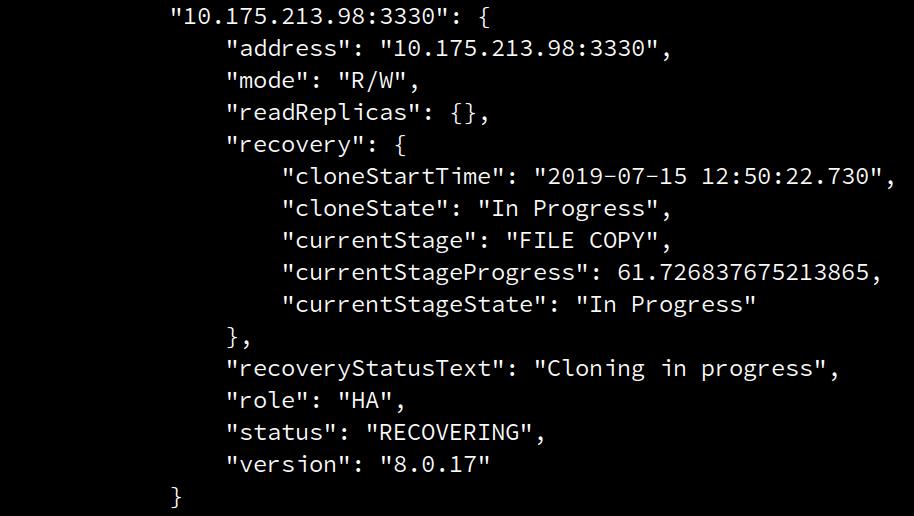
To control the behavior of the monitoring in <Cluster>.addInstance(), a new option was added named 'waitRecovery'. The option can take the following values:
- 0: do not wait and let the recovery process to finish in the background.
- 1: block until the recovery process to finishes.
- 2: block until the recovery process finishes and show progress information.
- 3: block until the recovery process finishes and show progress using progress bars.
Summary
The MySQL Clone Plugin pushed InnoDB cluster to a whole new level of usability. Automatic node provisioning was considered by many the missing feature to cover a set of common use-cases and real scenarios.
With Group Replication’s integration of Clone into the distributed recovery process, and MySQL Shell integration of it into the AdminAPI, InnoDB cluster features now built-in support for full instance provisioning.
The Shell, as the control panel of InnoDB cluster, fulfilled the goal of providing the most pleasant and easy-to-use experience of setting up and managing a cluster. It can decide automatically which provisioning method is appropriate, though it doesn’t discard the fact that in many cases using clone is simpler so users can easily choose it in the AdminAPI.
The documentation of MySQL Shell can be found in https://dev.mysql.com/doc/mysql-shell/8.0/en/ and the official documentation of InnoDB cluster can be found in the MySQL InnoDB Cluster User Guide.
Stay tuned for the upcoming blog post describing in detail how Group Replication integrates MySQL Clone on the distributed recovery process!
Enjoy, and Thank you for using MySQL!