In this blog series, I’m describing how InnoDB locks data (tables and rows) in order to provide illusion to clients that their queries are executed one after another, and how this was improved in recent releases.
So far we saw that access right currently granted and waiting to be granted are represented as record locks and table locks objects in memory, which we can inspect via performance_schema.data_locks. Also we have learned that they form “queues”, conceptually one for each resource. We’ve left out technical detail: the queue itself is a data structure, which will be accessed from many (perhaps thousands) threads in parallel – how can we ensure the integrity of the queue and fast parallel operation? It looks like, ironically, the Lock System itself needs some form of latching inside of it.
This post is about the change most important for the performance of Lock System, “WL#10314: InnoDB: Lock-sys optimization: sharded lock_sys mutex”, which arrived in 8.0.21 several years after a proof of concept was proposed and implemented by Paweł Olchawa. The idea seems relatively simple to explain: let the threads which operate on lock queues for different resources operate in parallel instead of latching the whole Lock System. For example if a transaction needs to enqueue a waiting lock for a row in one table, this operation could be done in parallel to another transaction releasing a lock on a different resource. Note that this is a low-level change w.r.t. high-frequency “latching” not the high-level long-term “locking” – what we care here is data integrity of the queue itself, and how to coordinate operations on the queue object such as “enqueue”, “dequeue” and “iterate” – each such operation is very short in practice, but historically required latching the whole Lock System, so no other thread could touch any queue until we’ve finished. So, this article is one level of abstraction lower than what we were dealing with in previous articles: the lock you want to enqueue may wait several seconds before being granted, but the mere operation of enqueuing it, this tiny, very short operation of allocating the lock object, and appending it to the list, is what we are concerned about now.
One of the reasons it took so long to bring Paweł’s idea to reality should hopefully be clear now after reading previous articles in the series: the Lock System is a very complicated beast, and there were at least two places which tried to do something globally on the whole wait-graph as opposed to locally within one queue: deadlock detection and CATS both performed a DFS. The changes described in previous articles moved these costly operations to a separate thread and made sure they do not have to latch the whole Lock System while they operate. All the other operations in our code base involved one or two lock queues.
Instead of having one latch per lock queue, we use a slightly different approach: we have fixed number of “shards” into which the lock queues are “sharded” and each shard has it’s own latch. (The technical reason it is implemented like that is because “lock queue” does not really exist in InnoDB code explicitly <GASP!>. The concept is a useful lie, that I’ve used to explain what Lock System tries to achieve, and you may find comments in our code talking about it as it was real. But the actual implementation is that locks reside in a hash table, with one doubly-linked list of lock structures per bucket where the hash is computed based on <space_id,page_no> of the resource. This means that “lock queues” for many different resources which happen to be hashed to the same bucket are mixed together into a single list. This makes it impractical and unhelpful to associate anything with a “lock queue”. Instead, we could try to associate something with a “hash table bucket”, which is almost what we do – we just add an additional modulo 512 step to make number of “shards” fixed and independent from the number of hash table buckets which you can configure at run time. There are 3 hash tables: for record locks, for predicate locks and table locks – the last one uses locked table’s id for hashing, and got it’s own separate 512 shards for latching)
I’ve already talked a lot about operations involving one queue, but not much about situations where we have to move locks across two queues. This happens when a page is reorganized due to B-tree splits or merges, or when a record is deleted (and subsequently: purged) so that “the point on the axis” vanishes and thus locks have to be “inherited” to the resulting gap (symmetrical problems occur when a new point splits a gap). We’ve already seen how requesting access to two resources can easily lead to deadlocks if you do not plan ahead to request them in some agreed upon order. Therefore, InnoDB makes sure to always latch the shards in ascending order.
Even though we’ve eliminated almost all places which required non-local access to Lock System, there are still a few which need to “stop the world”. As mentioned in article about deadlocks detection, if a deadlock really occurs, then we have to temporarily latch the whole Lock System to make sure there’s no race condition with transactions manually rolled back, etc. There are other such places, mainly in reporting: to give the user a consistent description of the situation we have to stop the world. (We might eliminate them in future, too – perhaps there are other practically useful views of the situation which are not globally consistent. For example: we could make sure that content of each individual lock queue is presented as internally-consistent, but allow snapshots of different queues to be taken at different times).
One way to latch the whole Lock System would be to simply lock all of the shards (in ascending order). In practice acquiring 1024 latches was too slow. (Actually, it was almost acceptable for Release build as stop-the-world doesn’t happen often, but the Debug build often runs self-diagnostic validation functions which required latching whole Lock System, which made running tests unbearably slow. Having two different implementations, one for testing and another for our users defeats the purpose of testing, so we went with slightly more complicated, but uniform, solution).
To make latching everything faster we’ve reused the idea you might recognize from article about table and record locks – we’ve introduced a two level hierarchy. The new global level lets you latch the whole Lock System or to just signal intention of latching a single shard. The global latch can be latched either in exclusive or shared mode. So, if a thread needs to latch whole Lock System it just has to acquire the global latch in exclusive mode. And if a thread plans to latch individual shards only, it first has to acquire the global latch in shared mode. Most of the time there is nobody interested in latching the whole Lock System, so there is no difficulty in acquiring the global latch in shared mode… except for ARM64.
You see, the way our read-write latches are implemented keeps track of how many threads currently share access to it, which among other things means you need to increment and decrement a counter very often in atomic way. On ARM64 atomic read-modify-write operations such as increment (read x from memory; add one; write x back to memory) are compiled down to retry loops, which may need to retry if another thread changed the value in between the read and the write. This means a lot of ping-pong on the memory bus where threads “fight” over access to the cacheline, overwrite each others attempts etc. instead of “simply” collaborating like grown-ups.
The solution here was to use … sharding again. Instead of having one global latch, we have 64 of them. To acquire exclusive rights, a thread latches all of them in exclusive mode. To acquire a shared right, a thread picks one of the 64 instances at random (Yes, we’ve tried using thread local fixed value. Yes, we’ve tried using cpu-id. Seems like random is a way to go) and latches it in shared mode. (And in case you wonder: yes, latching 64 times in exclusive mode is still faster than latching 1024 mutexes).
Another factor which made this all a bit harder than one could initially expect, is that there are places in our code which look at the set of locks from a perpendicular angle: instead of iterating over locks related to given resource, they need to iterate over locks related to given transaction. You can imagine locks arranged in a two-dimensional grid where each row represents a resource and each transaction has its own column. The sharding trick described earlier lets you latch a whole row safely, but what if you want to, say, release all the locks held by a committing transaction?
One approach would be to simply lock the whole Lock System. This was too slow in our tests.
Another approach is associate a latch with each column (transaction) and use it to protect the column. Now, extra care must be taken to make sure that whenever you “modify” something at the intersection of a given row (resource) and column (transaction) you obtain both latches: for the shard and for the transaction. What exactly counts as “modification” is a difficult subject, but surely if we want to entirely remove or introduce a lock object we should let the transaction and corresponding queue know about it. As is common theme by now, latching two things requires some care to avoid deadlocks. Therefore InnoDB uses a rule that queue-related latches (“rows”) should be taken before transaction latches (“columns”). In principle, the rule could be opposite. Either way there is a serious problem to overcome, which is one of the following two
- how can I efficiently iterate over all locks of my transaction, if I have to latch the shards containing the locks first, but I don’t know yet in which shards locks of my transaction are because I can’t access list of my transactions locks until I latch it?
- how can I efficiently grant a lock to a transaction if sorting all waiters requires me to latch the shard first, but the granting the lock requires latching the transaction picked as the winner?
Both seem like chicken-and-egg problems, and you always have at least one of these problems no matter which rule you pick: “rows” before “columns” makes the first one difficult, “columns” before “rows” makes the second harder.
Currently InnoDB favours the approach in which “rows” are latched before “columns”, which means the problem to tackle is “how to iterate over all locks of the transaction to release all of them?”. At the hand-waving level, the idea is to first latch the “column” and perform a read-only scan over transaction locks, where for each lock we note down the shard it belongs to, temporarily release the transaction’s latch, latch the shard, and reacquire transaction’s latch. After double-checking that the lock object hasn’t changed, and the list hasn’t changed, we can safely proceed holding both the “column” and “row” latches to process the lock.
The most common operation on the lock performed here is to release it. To release the lock using CATS algorithm we will sort the lock’s queue (which is safe, as we’ve already latched it’s shard) and grant locks to one or more transactions (which requires temporarily latching their transaction’s “columns”, which doesn’t violate the rule that “columns” should be latched after “rows”).
Once the lock is processed, we release the shard’s latch, and move to next lock on transaction’s list.
A curious reader might notice a potential for low-level deadlock when one transaction commits and the lock is being granted to another: the thread already holds latch on first transaction’s “column” when requesting latch for another. Our favourite remedy for this so far was to ensure some agreed upon ordering and argue that such latches are always taken according to this order. Yet this doesn’t give much hope in our scenario: why expect that transaction being granted the lock has address, id, or whatever “larger” than ours? What order could we use here?
The shortest, lazy, answer is: the serialization order. After all, the whole grand purpose of Lock System as a whole was to provide an order in which one transaction has to wait for another, duh. This is not a very convincing proof: not only it seems to assume the thesis, it also ignores the fact that transactions can use lower isolation levels, create deadlock cycles (which are essentially cycles in the serialization order), and be rolled back. But, it points into right direction: even though it might be difficult to describe one gold order among all transactions across time, we can use the fact that currently the first transaction is not waiting and the other is waiting to prove that a cycle is impossible as all edges go from active transactions to waiting transactions and there are no edges in the opposite direction. (The reader interested in a more rigorous proof, can refer to the proof presented in the source code comment, which deals with demons of concurrent programming such as: What does it even mean to use word “currently”?? Or: Which definition of “waiting” do you mean?? Or favourite of mine: From which thread’s perspective on the memory state??)
Claims about performance gains should be backed with charts, so let me share some of them. One of the original problems we wanted to solve was a scalability issue on 2-Socket servers, where synchronization on the single global lock_sys->mutex was so expensive to coordinate across sockets that it become such a bottleneck that you could get more transactions per second by simply disabling CPUs on one of the sockets. Thus one of the most important benchmarks for this work was to improve performance on sysbench OLTP-RW workload on a database with 8 tables, 10M records each, with queries affecting rows chosen randomly either by Pareto distribution (left column) or uniformly (right column), coming from either 128 clients (top row), or 1024 clients (bottom row) on a huge 2 Socket machine with very fast drive and lots of RAM so we can focus on CPU issues.
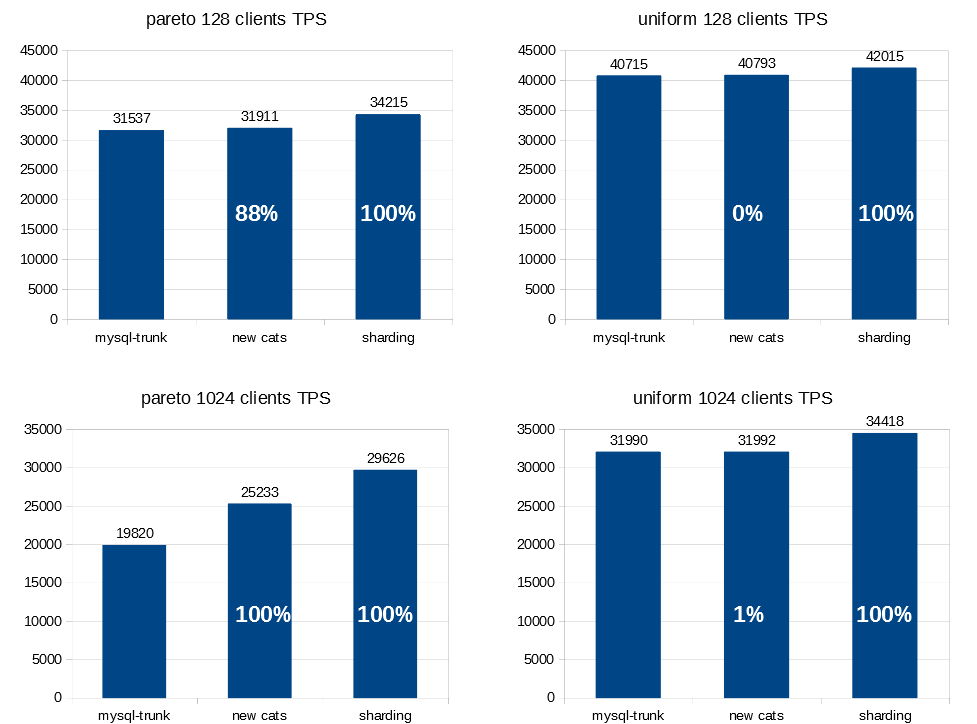
You can see Transactions Per Seconds (height of bars), increased when we’ve introduced new CATS implementation, and then again, when we’ve introduced sharding of lock_sys->mutex on top of it. The white percentages on the bars are Bayesian estimates of the confidence that given change in source code introduced improvement in TPS of at least 1% (in case you don’t trust your own eyes – we run 5min expermients with 1min warmup tens of times for each combination).
And here is a more fine-grained chart for Pareto distribution taken with the powerful dim_STAT tool which shows the impact of the changes (left=unmodified baseline trunk, center=new CATS algorithm, right=Lock Sys sharding on top of new CATS) on the congestion on various mutexes (upper part) and how this translates to TPS as we vary the number of connections exponentially: 1,2,4,8,16,32,64,128,256,512,1024.
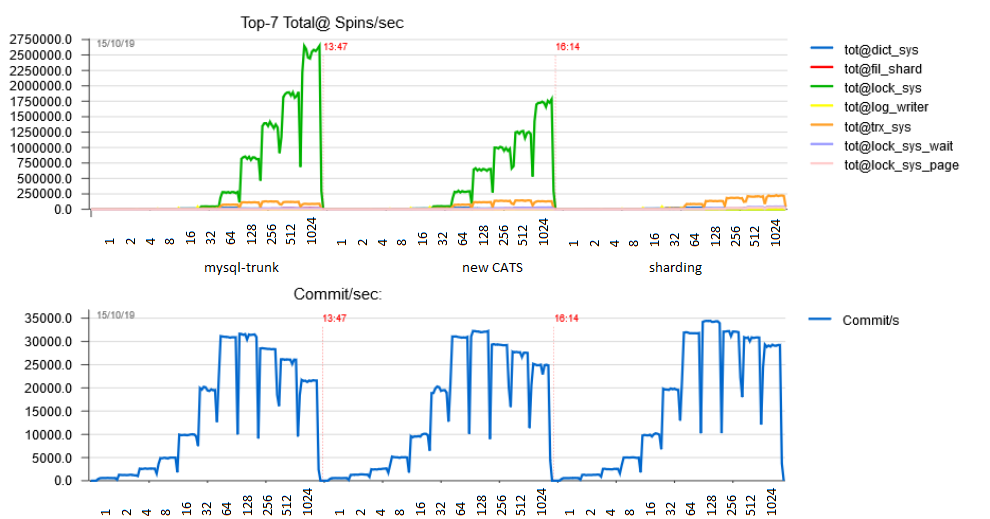
You can see that the new CATS algorithm already lowered congestion on lock_sys->mutex, and the new sharding eliminated the mutex entirely, replacing it with many shards of lock_sys_page mutexes (total congestion of which is not easily seen on the chart) and many shards of lock_sys_table mutexes, which didn’t even make it to the Top-7. Also you can see that TPS drops above 128 connections, and how eliminating lock_sys->mutex made the drop less dramatic, leaving us with the Final Boss to fight: trx_sys->mutex. And let me assure you that this battle is sure to be won, too. Be patient 🙂
Thank you for using MySQL!