In this blog series, I’d like to introduce you gently to the topic on which I was working last 2 years, which is improving how InnoDB locks data (tables and rows) in order to provide illusion to clients that their queries are executed one after another, while in reality there is a lot of concurrency.
I hope to start from a simplified view of the situation and challenges, and gradually introduce more and more real-world elements, in the hope that this way of presentation will make it easier to understand in the end.
Thus, please forgive me, if you find something not-entirely true in the beggining of the series – I invite you to the discuss the details in comments, or read the later parts of the series.
Summary of this post. In this post I’ll introduce following concepts, feel free to skip to the next post, if you are familiar with them already:
- databases, tables, rows (like files on a shared drive, spreadsheets inside a file, and rows inside a spreadsheet)
- serializability of transactions (ability to explain states observed over time with a convincing story about relative order of parallel operations)
- Amdahl’s law (limits of how much parallelism can help in presence of tasks which must be done one at a time)
- timeouts (for misbehaving lock owners, and to resolve deadlocks)
- reader-writer lock (shared/exclusive access rights)
- starvation (permanent inflow of readers starving a writer waiting for its turn)
- queueing (FIFO, or priority)
- read views (read-only snapshots which allow stale reads concurrent to new writes)
- wall clock time, out of band communication and their possible inconsistency with serialization order
- read, write, read-write transactions (why SELECT FOR SHARE gives different result than a regular SELECT)
- access right elevation (requesting Write access right already holding Read rights)
- deadlocks caused by escalation
- granularity of a lock (access right to everything vs. only the resources needed)
- deadlocks caused by granularity, and ways to overcome them by lock ordering
- live-locks
The way I answer “what do you do?” to my mother, is this:
Do you remember Excel? You know, columns, and rows, perhaps in multiple tabs. And then you might have multiple files. You probably do not appreciate it consciously, but it is a nice feature, that whatever you put inside a cell stays there if you save. Perhaps sometimes you need to add a new row, or remove it expecting that to simply work, even if there were some formulas, like SUM(A1:A100) involving these rows, right?
And have you ever had to collaborate on a single spreadsheet with another person? How did you go about not overwriting each others work? Did you have some SharePoint server which allowed only one person at the time to edit the file? Or mailed the file back and forth with new changes? Maybe you had a maskot which was passed around the office as a visible symbol of write-access rights?
And then came Google Spreadsheets, and somehow multiple people can now cooperate on a single spreadsheet. You can even press “Undo” to undo your changes but not theirs.
And when you have a cursor already in cell E13, and someone at the same time inserts a row above it, the system somehow knows that your value should go to E14.
Now, imagine there are 1000 people, constantly adding, removing, modifying cells in the multiple tabs of multiple files, expecting that it will “just work”, and that their SUM(A1:A100) formulas will update flawlessly all the time.
So, this is the situation I face: there are thousands of client machines, which perform INSERTs, DELETEs, UPDATEs, SELECTs, or some longer sequences of such operations known as transactions, and the programmers who wrote them often imagine the server which handles these transactions as a blackbox, which simply applies them one after another, “one person at the time”. The reality however is that that would be way too slow, so the server tries to do as much of these changes in parallel as long as it can pretend to the clients that it did them in a sequence. That is, the server needs to be able, if someone would interrogate, to come up with a convincing story about the timeline which is consistent with the observed states of the database, as if it handled clients one after another, even though in reality it interleaved, or executed some parts of their queries simultaneously. Why? Because programmers assumed so, to make their life easier. This is actually a really important value proposition of a database to the developer community, one that let the LAMP (Linux+Apache+MySQL+PHP) stack to hide most of the complexity of parallelism from the (PHP) developers, giving them a single source of truth. Or “truth”.
But how could the server pull it off? How to create a convincing lie? And how to lie faster without being caught?
As a first, really bad idea, it could just grant access rights to all of the “Excel files” (databases) to one transaction at a time, wait until the transaction finishes, and then grant the rights to another one in the queue. This is indistinguishable from handling one client at the time, because… it is really handling one client at the time – the multiple parallel connections are just waiting most of the time for their turn to get processed. No real speed up, just unfulfilled promise of parallelism.
Moreover this already introduces first real world problem: what if someone opens a file and goes on holiday forgetting to close it?
To handle this, we could introduce timeouts. Decide on some sane policy, like: each transaction should finish in 50 seconds, and if it doesn’t then we consider it has timed out, and roll it back – undo all of its work, and release the locks. This clean up is necessary, because we don’t want to expose unfinished work to others, and we don’t know how to finish it ourselves. The troublemaker will get notified about the incident once he get back from vacation and will have an opportunity to try again then.
One way to improve speed would be to realize, that some people just want to read, and do not modify the file. Perhaps even most fall into this category, as creating content is more difficult than consuming it, in general. So, we could have two access modes: Read and Write. The Write access must be exclusive, to prevent interference from other writers, and prevent readers from seeing unfinished work in progress. But, the Read access can be shared among many concurrent readers! This shows potential for huge speed up – if the ratio between processing time needed by writers and readers is 1:9, then these 9 can go in parallel, potentially bringing the time down from 1+9 to 1+1 – fivefold!
Remember though, that the server has to be able to present, if hypothetically someone asked, a serial timeline which is consistent with observations of all readers and writers.
This is simple in our case – the database state is only changed by writers, and no two writers can have Write access at the same time, so we can use the order on writers as a starting point to sketch the timeline – just put them on the timeline in the same (well-defined) order in which they got their Write access rights. Then we can put readers’ transactions into the holes in the story – care must be taken to put each reader in between the write they saw, and the write they didn’t saw, which can be done, because we know that no reader had a Read access concurrently with any writer having Write access, so for each pair of a reader and a writer there is a clear answer as two which one was first (Advanced reader might scorn at how easily I try to escape issues of relativity of time in the presence of multiple servers, replication and neutron stars etc. Please, ignore this for now).
Notice that while there is a definitive order among writers, and also readers relative to writers, server has a complete freedom of how to arrange readers among each other within the boundaries marked by writes. There are n factorial possibilities to chose from. That is, server can lie and nobody can notice! Note how improved parallelism comes with improved ability to lie.
This Read/Write approach looks like a cool idea, until you realize a subtle problem: what if the readers keep coming, and coming, and even though they all follow the “max 50 seconds per person!” policy, they do so in such a pattern, that there always is at least one reader with Read access present, and thus no writer can ever get to do any work? We say that the readers “have starved” the writer.
One natural way to solve this is First In First Out queue (FIFO). We introduce a new rule: if a new reader comes, it is not enough for it to see nobody with granted Write access to start reading. It should first check if there is someone already waiting in front of it in the queue, and if so, then gently enqueue itself at the end and wait for its turn. So, if there is already a writer waiting for already existing readers to finish and release their Read access rights, then the new reader has to enqueue behind this writer, instead of joining the crowd “just because it can”. Eventually, (after at most 50 seconds in our simple world) the active readers will finish (or be forced to rollback due to timeout) and the waiting writer will be granted the precious Write lock. Note, that this also avoids a symmetrical (albeit less common in the real world) problem of writers potentially starving the readers. Cool.
Instead of FIFO we could also use a priority queue: some transactions might be known to be more important for some reason, and might jump the queue.
We will revisit this idea later in the series when talking about Congestion Aware Transaciton Scheduling (CATS). In particular one factor to take into account for who should be granted the access rights might be the time they already wait in the system, and this was the basic idea behind previous implementation (VATS) used by InnoDB.
You can be much more creative than just coming up with new rules for ordering the queue! Remember that you can lie! What if, from time to time – say, every minute – you took a backup of all files. When a reader comes, you give them the version from the most recent backup. They don’t have to wait for any active or pending writers, they can start reading the old version of files right away. They couldn’t tell! This is called a “read view”. Each reader has a read view that it uses for the entire transaction. Perhaps many readers share the same read view, perhaps concurrent readers operate on few different read views – this is an implementation detail, as long as we can get away with this distortion of reality.
If someone asked about the timeline, the server could always pretend, that the read “happened before” the first write after that backup was made. Now, this is really cunning – the fictional timeline still has write operations in same places it had, but transactions of readers were unnoticeably moved to different spots in time, corresponding to moments of taking backups. How could they tell? Well, they could only tell if there was some write operation they “know about from a certain source” to “happen before” their read, but during their reading they do not see the effects of that write. Say, I’ve learned from a colleague, Alice, that she for sure put the new numbers to the report, yet I can’t see them!
Or, perhaps it was me, who put them, and I remember doing it, and hitting CTRL+S, damn it!
However, there is no “official” way to “know from certain source” except for doing the write yourself in the same transaction as the read – this is what “transaction” is about. If the read and write are not part of the same “transaction” then the server can always shift the blame to you by saying something along the lines of “Well, maybe she thinks that she put the new numbers, from her point of view, but you know, the spacetime is curved so strangely here, that perhaps you still don’t see the effects, because you are still in her past?“. You reply “But I hear her voice!“. And the server says “Sorry, Dave, but ‘voice’ is not part of SQL protocol, nor part of our Service Level Agreement. I’ve only promised that transactions are serializable in some order, not that that your out-of-the band communication I have no access to also agrees with this order. If you want me to take your communication into account then please let me know about it via XA PROTOCOL next time“.
If we were really evil, we could make backups once a year, or even just once at the very beginning when the database was empty, to save us trouble of having to store and present real data to readers! OK, this is annoying, but these are the rules of serializability alone.
Usually, as seen in this fictional story, people want something more, for example to see their own writes, and at least “some” agreement with the wall clock time when they ask for fresh results, and writes done by others which they somehow can prove “happened before” start of their read.
Most of these wishes can be achieved by making a new backup of files (“snapshot of all the databases”) after each successful (“committed”) transaction, and always handing out the most recent read view to the incoming reader – this way it is guaranteed that the read view contains changes from “transactions known to be committed” by this particular reader.
(Technically, there is still some problem if while reading, I overheard that colleague successfully pushed latest changes to the file, yet this seems to contradict what I see in my read view, and in particular contradicts the illusion that my read should “happen before” his write. But again, the server will simply respond that “rumours you overheard are not its business and if you hear something from future, then perhaps you should not trust your ears, and focus on what you see on screen”). The nice part of this approach is that we don’t even need Read access any more – readers just read whenever they like. Writers on the other hand still need to queue to avoid interference.
This idea with Read/Write access rights worked based on assumption that people can be neatly divided into readers and writers. We silently assumed that writers actually can read as well, which is reasonable assumption. We’ve also assumed, that writers know from the begging of their transaction that they are going to write, and thus need to request Write access early on. In reality, many of us start by reading a document, and only then decide to change something in it. This requires elevation of access right from Read to Write. It’s not very obvious how such elevation should look like when read views use snapshots – should they somehow see the file change to the latest version in front of their eyes when they start to edit it? For now, let’s assume that if transaction performs write operation, then a new window pops up with the latest version – the transaction can continue to read the old read view in the old window, or work on the latest editable version in the new window.
(BTW: This is actually, why REPEATABLE READ isolation level gives different results for SELECT * FROM t; and SELECT * FROM t FOR SHARE; within the same transaction – it has access to two “windows”: first of these two queries uses a read view, and the second one uses the most recent version of rows).
Let’s set read views aside for a moment, and get back to the simple FIFO approach with Read and Write rights, in the quest to figure out how “access right elevation” works.
Say, a transaction already has a Read access right, but now it wants to Write. So, it requests Write access right, which in the algorithm described so far means it has to enqueue and wait for all readers to release their Read access rights. But, it is one of them – it is among those who hold the Read access right! To avoid circularity here, we need to introduce a simple rule: we can ignore ourselves when looking for conflicting access rights.
Let’s carefully analyse if this is a correct thing to do. In particular: can a server with such a new rule, still come up with convincing lie about the ordering of transactions in time?
It seams reasonable to associate such “elevated” transaction with the point on the timeline corresponding to the moment it was granted the Write access right. That would explain why other concurrent readers haven’t seen its actions, and why it haven’t seen effects of writers behind it. So far so good.
However, what exactly happens, if when enqueuing request for Write access, there is already another waiting writer in the queue? Can we jump the queue? Or should we wait behind? If we jump the queue, then it seems consistent with a timeline where our transaction was before the waiting writer. However we’ve introduced a loophole: if lots of people start behaving like us, then the poor writer will wait helplessly looking as people pretend to only need to Read something, and then elevating rights to Write. The good news it should not be starved indefinitely – after all, the new people, even if pretending to only need Read access, will have to queue behind the writer, and thus only the finite number of readers which were already in front of the writer can escalate their access right before its the waiting writer’s turn.
If we do not jump the queue, then we are in a deadlock – we are waiting for the writer, who is waiting for readers to finish, but we are among them. (Current implementation of InnoDB uses this later approach, as code is simpler with it, and the deadlocks are relatively rare, and can be mitigated by requesting Write access early on. However it’s on our road map to try to experiment with the first approach.)
So far, we were guarding access to all databases with a single Read–Write lock.
But we can figure out a more granular scheme! Instead of locking all the databases, perhaps we could exploit the fact that if one transaction only needs access to one database, then it can go in parallel with another one working on a different database. This is the idea analogous to the SharePoint locking the file until you finish editing it, while another person works on another file without waiting. Hopefully, we could find many such opportunities for parallelism, and thus more clients could perform their transactions in parallel!
Could server justify this? Sure, if the two transactions have nothing in common, then it doesn’t really matter which one of them is before which in the timeline. Only someone looking at both files at the same time could figure out something about their relative order, and we haven’t yet specified what exactly happens, if someone needs access to more than one file. Suppose that I need to copy some numbers found in Assortment.odt file (File A for short) to Balance.odt file (File B for short). I would first need to request Read access to file A, and then Write access to file B. Let’s say, that Alice puts the numbers to file A, using Write access, and that Basil reads both files first B than A. To make it easier to follow the story, the names of characters match files they operate on:
- Alice writes to file A,
- Basil reads file B before file A,
- and as I am opening file A before B, let’s pretend my name is Abe 🙂
Will our locking scheme give results consistent with *some* ordering of Alice, Basil, and I (ABe) regardless of how crazy we go about interleaving our operations? If you wonder, what is the potential difficulty, observe that if there was no locking rules at all, it could happen, that Alice swears she’s changed Apples number from 0 to 10 in the Assortment.odt file, I remember that I saw 10 Apples and reported it in Balance.odt file by changing Budget from 0 to 10, yet Basil insists that he saw Budget being 10 and then Apples being 0, suggesting that I am incompetent in reporting more apples then there really were. Let’s hope our locking scheme does not lead to such a tragedy!
Let’s see how the server following our locking protocol could justify various outcomes depending on the order in which locks were granted. As I start by requesting Read access to A, and such access is incompatible with Write access needed by Alice, either I or she got the access first. So, lets split the story here (this, as you will see, gets quite complicated quickly, so feel free to jump over this section as soon as you feel you get the general idea of “analysing all possible histories”) :
- Reality 1:
In this version the story, Alice got the Write access right first, so I had to wait for her to finish, before my Read access was granted. It means, that when I’ve looked into the A file, then I saw her changes, that is 10 Apples, and then I’ve tried to write it to file B, which requires Write access which is incompatible with Read access needed by Basil. So, either I or he went first, and the story splits again.- Reality 1.1:
In this variant, I was first to get the Write access granted, and Basil had to wait. Only once I’ve put Budget=10, and hit Save, and release all my access rights, Basil gets his Read access to file B, sees my Budget=10, and then Read access to file A and sees Alice’s Apples=10, and satisfied gives us all a raise 🙂
The server, if asked, could pretend that the order was: Alice, me, Basil. - Reality 1.2:
In this variant, Basil looked into the B file before me. So, he saw Budget=0. Then he tried to get Read access to A, and given that Alice already finished, and I only needed read access, he can look into it without problem, seeing Apples=10. Basil thinks that I am lazy, but otherwise competent, doesn’t give anyone a raise, but at least doesn’t yell neither. Once he is done, I finish my work, by updating file B.
The server, can pretend that the order was: Alice, BAsil, me.
Notice, that this is a subtle lie: actually my and BAsil’s work was done in parallel, but none of us could tell it.
Except for the lack of the raise 🙁
- Reality 1.1:
- Reality 2:
In this version, Alice was just a minute late, and thus I got to read the old version of the file A with Apples=0. I’ve then requested write access to file B, and the story splits here again w.r.t. to my race with BAsil.- Reality 2.1:
I’ve got write access to file B before BAsil. After opening it, I saw Budget=0 so decided not to change it, except for changing the font color to red, to indicate how sad this is.
After I released the access rights, BAsil’s read request to file B got granted. He sees Budget=0 in red, scratches his head, and decides to look into file A. The story splits here again, because it is not clear if Alice has managed to update the file yet. The Write access right needed by Alice and Read access needed by Basil are mutually exclusive, so one of them had to go first:- Reality 2.1.1:
Basil got Read access right only after Alice has released her Write access right. That is, Alice has made it to put Apples=10 before Basil looked into the file. Then Basil sees Apples=10, which together with previously seen Budget=0, means that I am lazy, but at least I’m not pulling Apples out of thin air.
Server can pretend, that the order was: me, Alice, Basil.
Which might be a small lie, if Alice actually updated file A while Basil was busy with checking Budget in file B, but who cares.
Note that even if I wasn’t playing with background color of Budget=0 cell, the story would NOT be consistent with ordering: Alice, Basil, me, because I am competent and wouldn’t leave Budget=0 seeing Alice’s 10 Apples! - Reality 2.1.2:
Alice was late this day, and Basil got Read rights before Alice got to write. Therefore Basil sees Apples=0, consistent with Budget=0, me being competent, and bad situation in the market.
Then Alice gets the Write access to file A, modifies the Apples to 10, and the day ends.
The server insists that the story goes: me, Basil, Alice.
If I wasn’t playing with background colors, it would also be consistent with Basil, me, Alice, so the server would have more wiggle room.
- Reality 2.1.1:
- Reality 2.2.:
Basil got Read access to file B before I got a Write access to it. So, Basil saw the old Budget=0 value in it. Then Basil tried to Read file A. As this access is incompatible with Alice’s Write request for the same file, one of them had to be the first to claim the access right.- Reality 2.2.1:
Alice Write was before Basil’s Read. This seems interesting case, because we also know that in this whole2.*branch of reality, my Read was before Alice. So just by looking at accesses to file A, we can observe that the order must have been: me, Alice, Basil. This seems to contradict the premise of Reality2.2.*which was that my Write to file B was after Basil’s Read of it. How do we go about this? Can we just declare that 2.2.1 is not a real world scenario, because it doesn’t fit our preferred lie? No, that would be cheating. We have to prove that this scenario is impossible using only the semantics of FIFO queues for access rights and what the actors have observed and we’ve assumed so far.
That is:- (Premise of
2.2.*) Basil got Read access to file B before I got Write access to B.
1Basil.read(B) << ABe.write(B) - (Premise of
2.*) I got Read access to file A before Alice got her Write access to A.
1ABe.read(A) << Alice.write(A) - (Premise of 2.2.1) Alice’s Write was before Basil’s Read in the A file’s queue.
1Alice.write(A) << Basil.read(A) - we additionally know, that Basil was attempting the Read A after Read from B:
1Basil.read(A) << Basil.read(B)
Folding this all together we get:
1ABe.read(A) << Alice.write(A) << Basil.read(A) << Basil.read(B) << ABe.write(B)What’s wrong here? For one thing, it looks like Alice got Write access to resource A even though I had Read access to it, which I could only release after finishing my Write to B. This is the contradiction we needed!
- (Premise of
- Reality 2.2.2:
Alice Write was after Basil’s Read. So, Basil sees the old number of 0 Apples. So, Basil saw zeros in both files. The server can pretend that the order was: Basil, me, Alice.
- Reality 2.2.1:
- Reality 2.1:
That was exhausting.
What I hope you take from the above is several observations.
First, that the server can stitch the final order of transactions from partial orders known for each individual file’s FIFO queue or at least use that as the starting point. Moreover it has to take these partial orders into account, because they are (potentially) observable by clients (at least the parts with Read potentially seeing previous Writes).
Secondly, that simply specifying what each transaction plans to do is not enough to describe all the various ways in which they can interleave with each other under the hood. But in the end, the server can pretend that what happened was equivalent to one of the 3! possible permutations:
1.1 Alice, me, Basil
1.2 Alice, Basil, me
2.1.1. me, Alice, Basil
2.1.2. me, Basil, Alice
2.2.1. Impossible.
2.2.2 Basil, me, Alice
Finally, that proving anything in this area is usually difficult, and I’m not even sure I’ve did it right this time. For example, I find it puzzling that there is no real world situation corresponding to Basil, Alice, me… Apparently I forgot to split case 1.2 into two subcases, based on wether Basil overtook Alice! You see how complicated it is? 🙂
One trick I find useful when trying to impersonate the server and figuring out what timeline it should offer, is to imagine a Tetris-like game, where each column of blocks represents a single resource (here: a file) and a transaction requesting access right for a given file drops a 1×1 block from the top of a corresponding column with a color corresponding to this transaction. If it falls on the ground the access right is granted. If not, then the transaction has to wait in queue behind the owners of the blocks below it (so, a column is like the FIFO queue!):
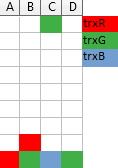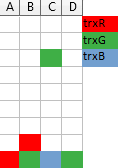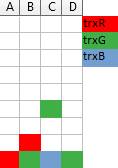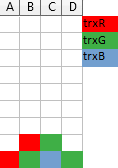
The above illustration shows three transactions: trxR already waits for resource B held by trxG, and trxG is requesting access to resource C, and will have to wait for trxB which is currently in possession of it.
When a transaction finishes, then all of its blocks vanish, and the blocks above it fall down (they move forward in queue), and those that now hit the ground get the access rights granted:

This Tetris analogy only makes sense for exclusive access rights, so for a moment pretend we only deal with Writes.
Now, if you have a recorded gameplay, you can replay it, but with a small change: blocks of finished transactions do not vanish. In the end you will get a static image like this:
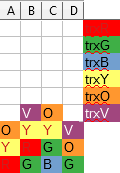
In the illustration above, transactions create colorful layers, where each color represents a single transaction.
When the server is asked to provide an ordering consistent with what has been observed, it can use the (partial) order of the colorful layers: if one transaction has a block above another one, it must be the case that one got granted the access right after the previous one released it and thus had chance to see results of the previous one in reality, so one must be after another in the fictional order, as well. For the example in the picture above, trxV has to be after trxY and after trxO.
And as long as the order offered by the server is consistent with the order of these colorful layers, nobody can catch it on a lie!
But are these layers really partially ordered? Couldn’t there be a cycle?
Yes, unfortunately there could be a cycle! 🙁
Going back to our example, suppose that Basil, wants to Write to the file A, not just read it.
It might happen that I’ve already opened file A for Read, Basil already opened file B for Read, then I am waiting to get write access to file B still opened by Basil, and Basil wants to Write to file A, which I still hold open in Read mode. This is a classic form of deadlock cycle, and in our Tetris world it looks like this:
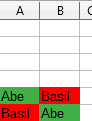
Note that none of the layers is above another.
The snakes have heads on each others’ tails! 🙂
How can we detect such a situation? We’ve already introduced one solution: a timeout. Since none of us can take any action except for waiting, at least one of us will eventually time out.
Then the other will be able to finish.
Note that timeout involves a roll back of all changes which a transaction introduced, which means that the one who continues will not see changes of the other one, which is a good thing. It’s like the blocks completely vanish from the Tetris world history as if they never were there in the first place.
A little worse scenario is that both of us time out, and both of us retry and bang our heads together again. And again. This is called a live-lock, and can hopefully be side-stepped by randomizing the backoff time it takes between reattempts. Or some politeness etiquette like: beauty before age 🙂
One can also avoid deadlocks entirely, by following a simple rule: always open files in alphabetical order. If I and Basil followed this rule, then it could not happen that I have something he needs and vice-versa, because each of us always wants something lexicographically later than already possessed. In the Tetris world it means that each transaction only drops a new block to a column to the right of previously dropped one, so the layers are being built from left to right, and the situation of “one snake has a head on another’s tail and vice-versa” is impossible, as it requires one of them moving in the left direction. BTW. This is the policy used by LOCK TABLES – behind the scenes it sorts the list of tables you gave it, and acquires locks in ascending order. This is also why it requires you to specify all the tables up front, and why it is incompatible with other deadlock prevention mechanisms to some extent.
You’ve probably guessed, that it doesn’t matter if the order is literally alphabetical – it can be any order, as long as it is fixed for your whole application.
But, in reality, structuring your application to always acquire locks in a given order can be non-trivial even if given the flexibility to choose the order yourself. We know it firsthand, because InnoDB’s internal code uses this ordering technique to avoid deadlocks among low-level locks taken by the InnoDB itself, and it’s really hard to maintain this rule across teams, plugins, layers, modules, and parallel branches.
So, deadlocks are part of reality and are here to stay. How do we detect them? This will be a topic of Part 3. But first, we will see how the abstract concepts we’ve talked about here map to InnoDB’s Lock System objects: locks, this will be Part 2.
Thank you for using MySQL!