On July 20th, 2021, we’ve celebrated the release of MySQL NDB Cluster 8.0.26. MySQL NDB Cluster (or NDB for short) is part of the MySQL family of open-source products providing an in-memory, distributed, shared-nothing, high-availability storage engine usable on its own or with MySQL servers as front-ends. For the complete changeset see release notes. Download it here.
Choosing a database can be an overwhelming task, requiring to consider performance (throughput and latency), high availability, data volume, scalability, ease of use/operations, etc. These considerations are affected by where the database runs — whether that is in a cloud provider such as Oracle Cloud Infrastructure offering a broad range of infrastructure from small Virtual Machines (VM) to large Bare Metal (BM) instances, and High-Performance Computing (HPC) servers or one’s own on-premises hardware.
When aiming at the very best performance, databases can be complex beasts requiring understanding and experimenting with hundreds of different tuning parameters. This task can be made even more complex by going one level deeper, into the operating system, tweaking kernel settings to best match the database requirements. Finally, tuning a database is done for a specific workload and the same tuning settings might result in sub-optimal performance when running different workloads — yet another complication. All of this can be a lot of fun and very painful at the same time.
Can we achieve a high-performance and highly-available cluster in a easy way?
Having access to a brand new high-end Dell EMC PowerEdge R7525 server, dual-socket AMD EPYC 7742 with 2 TB RAM, and four 3TB NVMe SSD we set ourselves to explore how to do an easy setup for a high-performance, highly-available cluster in a single box with the newly released MySQL NDB Cluster 8.0.26.
Jumping ahead and answering the question — yes —using sysbench OLTP point select benchmark, we can easily achieve a constant throughput of over 1.5M primary key lookups per second with a two data-node cluster, each data-node configured with 32 CPU, using a total of 16 MySQL servers and 1024 clients (sysbench threads).
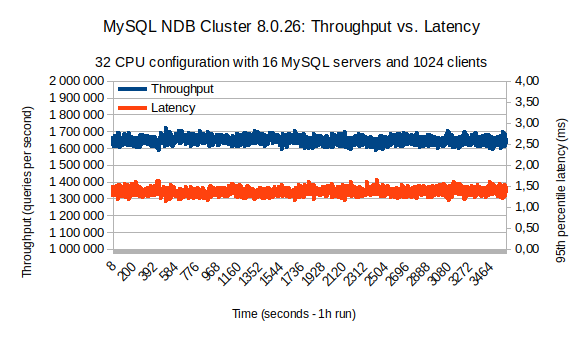
The chart above shows the results of a 1h long run. Looking at the blue line, we can see a constant throughput in the range of 1.6–1.7 million queries per second (primary-key lookups). Max recorded throughput is at 1,716,700 primary key lookups per second. Also important is the 95th percentile latency, the red line, which is in the range of 1.1–1.6 milliseconds and has an average of 1.35 milliseconds.
So how easy is it to configure MySQL NDB Cluster for these results? It was pretty straightforward! In the following sections, we will describe in detail the hardware, NDB configuration, benchmark setup, and the analyses of intermediate results that lead to those performance numbers.
Hardware setup
All our tests run on a single Dell EMC PowerEdge R7525 server configured with:
- Dual 2nd generation AMD EPYC 7742 (Rome) 64-Core processor, 128 threads, 7nm design, max clock speed of 3900 MHz, and 256 MB cache
- 32 x 64 GB DDR4 dimms (SK Hynix), 3200 MT/s speed, total of 2 TB RAM
- 4 x 3.2TB NVMe drives (Dell Express Flash PM1725b)
Similar specification servers are available by choosing the BM.Standard.E3.128 shape currently offered in Oracle Cloud Infrastructure (OCI). For the list of available shapes and their specifications see here.
The server was installed with Oracle Linux Server 8.3 using Kernel version 5.4.17 (2021.7.4).
Benchmarking setup
All our benchmarks were run with sysbench 1.1.0 version available from https://github.com/akopytov/sysbench. No changes to the benchmark code were done for transparency and reproducibility purposes. We choose to use sysbench as it is well-known and simple to use benchmark used to evaluate database performance under different load scenarios.
Our dataset uses 8 tables and 10M rows per table using around 60GB of memory. This configuration is the most common starting point for many benchmarks done in the MySQL team (for both InnoDB and NDB Cluster storage engines). The data is large enough to not just run on CPU cache only but not large enough to involve too much IO activity (e.g. long-duration node restarts or dataset initialization).
We used OLTP point-select workload consisting of primary-key lookup queries returning a constant string value. This workload tests the full database stack (MySQL servers and NDB storage engine) for overall code efficiency and the best possible query execution latency. Key generation is done using the default uniform distribution algorithm. Sysbench is run in the same machine as the database, connecting to MySQL servers via Unix sockets.
MySQL NDB Cluster setup
A minimal recommended high-availability scenario requires 4 hosts: 2 hosts running data nodes and 2 hosts running management nodes and MySQL servers or applications (see FAQ). In this scenario, any of the hosts can be unavailable without impact on the service. Using a single-box setup software-level redundancy can be supported by running two data nodes and multiple MySQL servers or applications. In this scenario, we can perform online operations such as online upgrades without service impact.
To take advantage of a server like the one we’re using, we can equally split machine resources for each data node and set of MySQL servers.
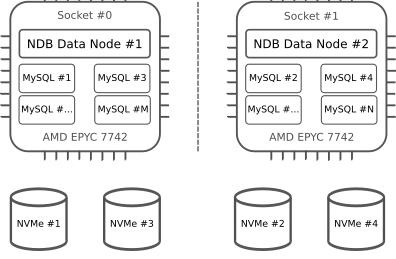
In this setup, we use a single NUMA node per socket (physical CPU). The server supports configuring up to 4 NUMA nodes per socket (a total of 8 NUMA nodes — see AMD Tuning Guide for more info). For each NUMA node, we run a single data node and a balanced number of MySQL servers accessing half of the available memory. Note that, despite MySQL NDB is an in-memory database, disk-checkpointing is enabled by default (and a recommended setting). In our setup, all NVMe disks are available from a single NUMA node only (ideally we would have half of the disks per NUMA node).
Having defined the cluster topology, using two data nodes and several MySQL servers, the next step is to define how many CPU resources to allocate to NDB and MySQL server processes. We have found that a 25/75 CPU allocation provides a good starting point.
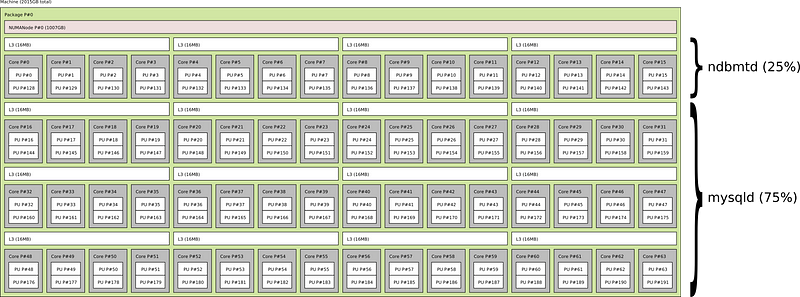
MySQL NDB Cluster has been designed to be very efficient and it’s natural that it requires fewer resources than MySQL server. The actual division of resources will depend on the workloads. In cases where queries can be pushed to the data nodes, it will make sense to reserve more CPU for NDB. In cases where SQL-level aggregations or functions are performed, then more CPU is necessary for MySQL server.
With the above resource allocation, for each socket (physical CPU) we’ll reserve 16 cores (32 threads) for NDB data node (ndbmtd) process and 48 cores (96 threads) for MySQL server (mysqld) processes.
The main NDB Cluster configuration is:
[ndbd default]
NoOfReplicas = 2
DataMemory = 128G
# Auto configures NDB to use 16 cores/32 threads per data node
AutomaticThreadConfig = 1
NumCPUs = 32
NoOfFragmentLogParts = 8
# Prevents disk-swapping
LockPagesInMainMemory = 1
# Enables Shared-Memory Transporters (20% performance gain)
UseShm=1
# Allocates sufficient REDO log to cope with sysbench prepare step
RedoBuffer=256M
FragmentLogFileSize=1G
NoOfFragmentLogFiles=256The key elements of this configuration are:
- NoOfReplicas: defines the number of fragment replicas for each table stored in the cluster. With two data nodes, it means that each will contain all the data (ensuring redundancy in case any of the data nodes is down).
- DataMemory: the amount of memory used to store in-memory data. We have set it to 128G in our benchmark but we could increase it up to 768G given that we have 1TB of RAM available per data node (still leaving a big margin for the operating system).
- AutomaticThreadConfig: when enabled allows the data node to define which NDB-specific threads to run.
- NumCPUs: restricts the number of logical CPUs to use. We have set it to 32 which means that we’re expecting NDB to take advantage of the 16 cores / 32 threads available.
- NoOfFragmentLogParts: optional configuration, sets the number of parallel REDO logs per node. We have set it to 8 because there will be 8 LDM threads when using NumCPUs=32. This enables each LDM thread to access REDO log fragments without using mutexes — leading to slightly better performance.
- LockPagesInMainMemory: prevent swapping to disk, ensuring best performance. We have set to 1 in which we lock the memory after allocating memory for the process.
- UseShm: enables shared memory connection between data nodes and MySQL servers. This is a must when co-locating MySQL servers with data nodes as it provides a 20% performance improvement.
The other configuration options are required only to run sysbench prepare command used to fill data in the database. They have no impact when running OLTP point select workload but might have in other workloads.
The management-node and data-node specific options are:
[ndb_mgmd]
NodeId = 1
HostName = localhost
DataDir = /nvme/1/ndb_mgmd.1
[ndbd]
NodeId = 2
HostName = localhost
DataDir = /nvme/1/ndbd.1
[ndbd]
NodeId = 3
HostName = localhost
DataDir = /nvme/2/ndbd.2These options define one management node and two data nodes. For each, we set unique identifiers (NodeId), the hosts from where they will be running (HostName), set to localhost, and finally, the path where to store required files (DataDir).
The final configuration required for NDB processes is to add API nodes required allowing MySQL servers and NDB tools to connect to the cluster. An excerpt of those configurations are:
[mysqld]
NodeId = 11
HostName = localhost
...
[api]
NodeId = 245
...For a complete list of data node configuration parameters see here.
Finally, the MySQL server configuration is as follows:
[mysqld]
ndbcluster
ndb-connectstring=localhost
max_connections=8200
# Below three options are for testing purposes only
user=root
default_authentication_plugin=mysql_native_password
mysqlx=0
[mysqld.1]
ndb-nodeid=11
port=3306
socket=/tmp/mysql.1.sock
basedir=/nvme/3/mysqld.1
datadir=/nvme/3/mysqld.1/data
[mysqld.2]
ndb-nodeid=12
port=3307
socket=/tmp/mysql.2.sock
basedir=/nvme/4/mysqld.2
datadir=/nvme/4/mysqld.2/data
...There are three important settings specified under [mysqld] that are needed by all MySQL. Those are:
- ndbcluster: enables NDB Cluster storage engine;
- ndb-connectstring: explicitly sets the address and port of all management nodes used to connect to NDB Cluster. In our case, where the management node is run locally, this setting is optional;
- max_connections: optional, required when running benchmarks with a large number of clients;
For each MySQL server we need to define individual configuration at least for port, socket, basedir, and datadir.
The complete configuration files and instructions are available from https://github.com/tiagomlalves/epyc7742-ndbcluster-setup
Running MySQL NDB Cluster, MySQL server, and sysbench
To run MySQL NDB Cluster and MySQL Server we assume all packages are installed in the system and available in the path. We assume that sysbench has been compiled and installed in the system.
We use numactl to set process affinity to specific CPUs / NUMA nodes according to the above-defined setup, where we reserve 25% of CPU capacity for NDB data nodes and the remainder 75% CPU capacity for other processes.
To run the management node:
$ numactl -C 60-63,188-191,124-127,252-255 \
ndb_mgmd \
--ndb-nodeid=1 \
--configdir="/nvme/1/ndb_mgmd.1" \
-f mgmt_config.iniNote that the management node (ndb_mgmd) consumes very little resources and can be run from any logical cpu. The above numactl settings allow ndb_mgmd to run from any CPU in any NUMA node except for those reserved for data nodes.
To run data nodes:
$ numactl -C 0-15,128-143 \
ndbmtd --ndb-nodeid=2$ numactl -C 64-79,192-207 \
ndbmtd --ndb-nodeid=3The first data node, having nodeid 2, is run in the first 16 cores of the first NUMA node (NUMA #0), and hence affinity is set to CPUs 0–15 and 128–143.
The second data node, having nodeid 3, is run in the first 16 cores of the second NUMA node (NUMA #1) and hence affinity is set to CPUs 64–79 and 192–207.
To run MySQL servers:
$ numactl -C 16-63,144-191 \
mysqld \
--defaults-file=my.cnf \
--defaults-group-suffix=.1$ numactl -C 80-127,208-255 \
mysqld \
--defaults-file=my.cnf \
--defaults-group-suffix=.2Multiple MySQL servers are run per NUMA node. We decided to run all odd -numbered MySQL servers in NUMA #0 (CPUs 16–63 and 144–191) and even -numbered MySQL servers in NUMA #1 (CPUs 80–127 and 208–255). Multiple MySQL servers in the same NUMA node will share all CPUs except those reserved for the data nodes. It’s possible to have each MySQL server process running in a dedicated set of CPUs preventing shared CPU resources between processes. This approach requires careful validation as discussed later.
To run sysbench:
$ THREADS=1024 ; \
MYSQL_SOCKET=/tmp/mysql.1.sock,/tmp/mysql.2.sock,... ; \
numactl -C 16-63,144-191,80-127,208-255 \
sysbench \
--db-driver=mysql \
--mysql-storage-engine=ndbcluster \
--mysql-socket="${MYSQL_SOCKET}" \
--mysql-user=root \
--tables=8 \
--table-size=10000000 \
--threads="${THREADS}" \
--time=300 \
--warmup-time=120 \
--report-interval=1 \
oltp_point_select runWe run Sysbench in the same machine as MySQL NDB Cluster and MySQL servers using Unix sockets. In typical scenarios, however, applications and database are run from different hence requiring using the TCP/IP network stack instead. In such scenarios it’s expected an inferior performance than what we report here.
All our runs have a duration of 300 seconds (5 minutes) with a warm-up period of 120 seconds (2 minutes). In practice, we have seen that with 2 minute warm-up duration, it suffices to run the benchmark for 1–2 minutes. We have validated running the benchmark for over 1h periods and there was not significant variation in the mean throughput recorded.
Scaling up a single MySQL server
Our first step when benchmarking MySQL NDB Cluster was to start with a single MySQL server. This gives us a base understanding of the specific workload we’re testing helping us to know how to allocate resources and fine tune further parameters.
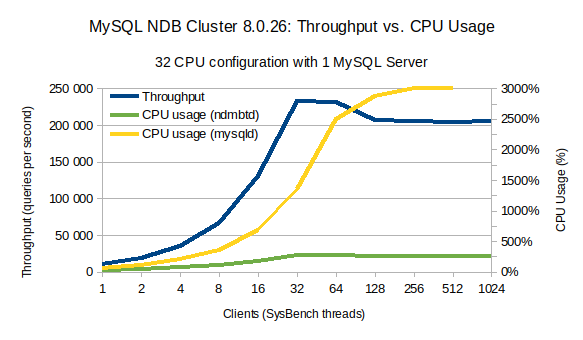
In the chart above we show the throughput (measured in queries per second), depicted in blue, and the CPU utilization of NDB data nodes (ndbmtd), depicted in green, and MySQL server (mysqld), depicted in yellow. Throughput scale is shown in the left y-axis. CPU utilization is shown in the right y-axis. On the x-axis, we show the number of clients (sysbench threads) used for each run.
This chart shows that when increasing from 1 up to 32 clients, throughput and mysqld CPU utilization increase accordingly. In the same range, ndbmtd CPU utilization increases only slightly.
At 32 clients, we reach the maximum throughput of ~230K queries per second. MySQL server (mysqld) CPU utilization is about ~1400% meaning that a total of 14 logical cpus are being used.
From 32 to 64 clients, we see mysqld CPU utilization almost doubling to (2500% — 25 logical cpus) causing a slight throughput degradation. From 64 clients to 128 we see further degradation of throughput and the CPU utilization curve for mysqld flattens meaning that the MySQL server is saturated. At this stage, mysqld is using ~3000% of CPU (30 logical CPUs) out of the 96 logical CPUs available (48 cores / 96 threads). From 128 clients onward, there’s no further increase in throughput or CPU utilization.
This chart means that the optimal throughput conditions using a single MySQL server for OLTP point select workload happens at 32 clients and around 64 clients we reached the maximum of MySQL server.
We know that the bottleneck is in the MySQL server and not in NDB Cluster because NDB utilization is fairly low. This can be seen using the ndb_top tool:
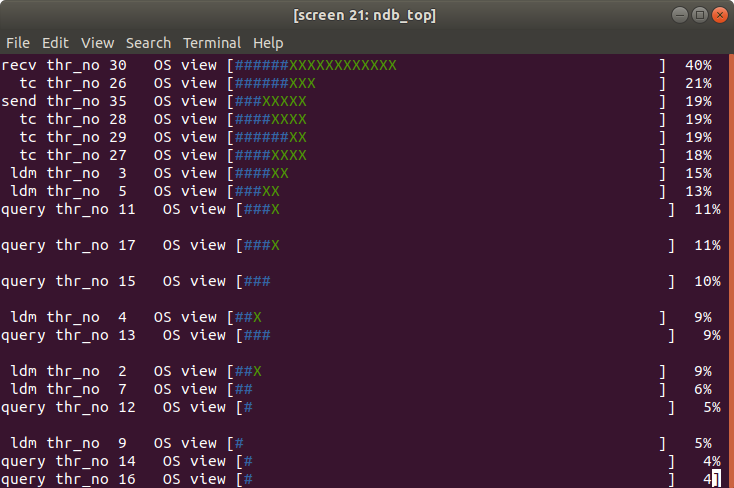
The above screenshot shows the CPU utilization of the different NDB threads (ldm, query, tc, send, recv, and main). For more info on the NDB internals see here. From our configuration, we know that we have 3 recv threads but we have only one at 40% and the remainder idle. We also see that most other threads have a low utilization < 80%. This confirms that the bottleneck is in the MySQL server side and not in NDB.
To address the MySQL bottleneck, we can simply scale up the number of MySQL servers. As shown above, the optimal conditions for throughput happen when using 32 clients for which 14 logical CPUs are used by MySQL server. Considering that we have 48 cores / 98 threads per socket, we can have ~98/14 = 7 MySQL servers per socket. Rounding up this gives us around 8 MySQL servers per socket.
Scaling up multiple MySQL servers
When a single MySQL server becomes saturated we can continue to scale by adding more MySQL servers. Previously we estimated that we could use up to 8 MySQL servers per socket, or 16 MySQL servers in total.
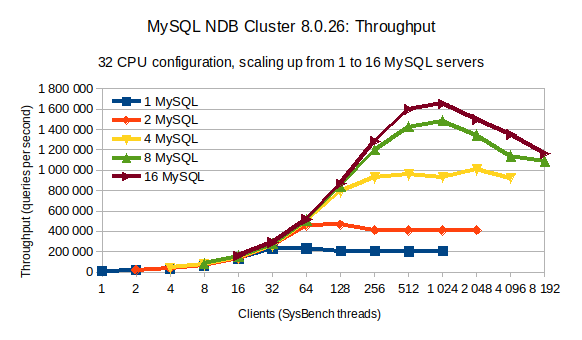
The above chart shows a series of tests done with an increasing number of clients (sysbench threads) for 1 to 16 MySQL servers. In this chart, we record the average queries per second over a 300 second period. The chart shows that after 32 clients, we need to double the number of MySQL servers to sustain an increasing throughput with more clients (sysbench threads). This is what we expected. Also note that, when going from 8 to 16 MySQL servers, we are no longer capable to double the throughput.
Maximum throughput is reached with 16 MySQL servers using 1024 clients (sysbench threads). When adding extra clients the throughput starts to degrade meaning the system is becoming saturated.
Also interesting is to look at the latency when running an increasing number of clients for a different number of MySQL servers.
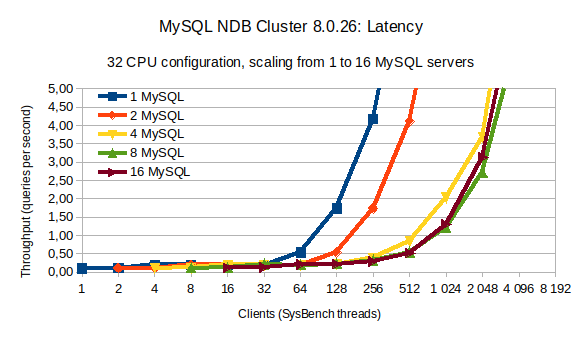
When using a single MySQL server, the 95th percentile latency is below 0.5ms up to 32 clients (sysbench threads) and then exponentially grows when more clients are used. Doubling the number of MySQL servers allows doubling the number of clients (sysbench threads) keeping the same low latency below 0.5ms. However, when using 8 or more MySQL servers, we can no longer keep latencies below 0.5ms using 512 clients or more — meaning the system starts to be saturated. Note as well that there’s no significant difference in latency between using a total of 8 or 16 MySQL servers (16 being a bit worse from 2048 clients or higher).
The above charts show the average throughput and 95th percentile latency for a full run. These aggregated values provide little information about the throughput and latency stability during the run. This shown below:
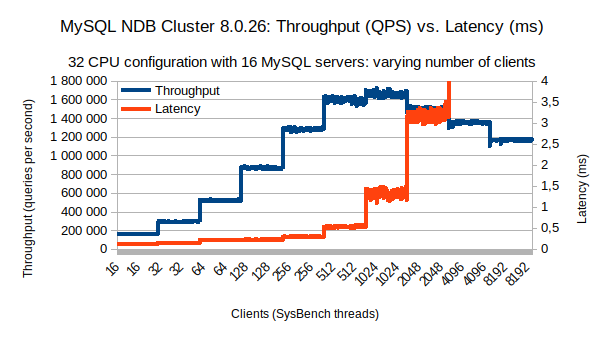
The above chart shows the average throughput (in blue) and 95th percentile latency (in red) sampled every second using 16 MySQL servers for an increasing number of clients (sysbench threads). For both throughput and latency, except when we’re reaching system saturation, both are pretty stable. In the case of throughput, we can observe a steady throughput even when latency goes above 0.5ms which is expected from an in-memory database.
Going above 1.7M QPS
Using this Cluster configuration and workload it is possible to go above 1.7M queries per second. It’s also possible to further reduce the variation in measurements by fine-tuning operating system settings. However, this is no longer an easy task requiring experimenting with other configuration parameters, falling outside the scope of this blog.
Regardless, to give you a hint about possible next steps, we can start by looking at the output of ndb_top:
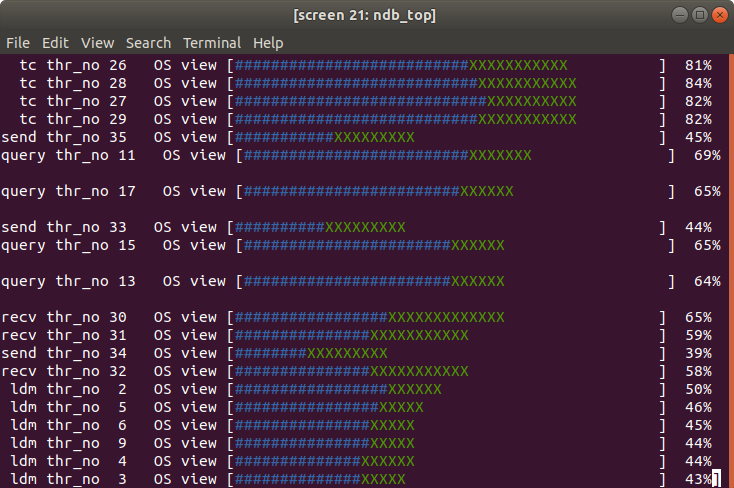
This confirms that now the bottleneck of the overall system is the NDB cluster. More precisely, the tc threads are at 80% CPU utilization having reached saturation. Despite that, the other threads are still far away from being saturated which leaves space for further optimization.
When enabling AutomaticThreadConfig and configuring NumCPUs=32, NDB will make use of 8 ldm, 8 query, 4 tc, 3 send, 3 recv, and 1 main threads. From the above, we see that the tc threads are saturated but the ldm+query threads are still not being fully utilized. To further try to improve query execution we could manually set the number of threads to use, reducing the number of ldm+query threads and adding a few more tc threads. But that, we’ll leave it for another blog post!
Conclusion
MySQL NDB Cluster has been developed with the goal of enabling horizontal scaling. However, with the continuous improvement of high-end hardware, it’s important to have a simple way to scale up a database. This blog provides an introductory walk-through on how to scale up MySQL NDB Cluster 8.0.26 in an easy way reporting over 1.7M primary key lookups per second.
MySQL NDB Cluster is an open-source distributed in-memory database. It combines linear scalability with high availability, providing in-memory real-time access with transactional consistency across partitioned and distributed datasets. It was developed to support scenarios requiring high-availability (99.999% or more) and predictable query time.
Source code and binaries are available from: https://www.mysql.com/products/cluster