The MySQL Development Team is happy to announce a new 8.0 Maintenance Release of MySQL Shell AdminAPI – 8.0.23!
In addition to several bug fixes and minor changes, some significant enhancements regarding monitoring/troubleshooting and performance were included.
MySQL Shell AdminAPI
Cluster diagnostics
Checking how a Cluster is running and, whenever the cluster is not 100% healthy, perform troubleshooting tasks is certainly one of the main tasks of a DBA. The AdminAPI makes this operation very easy by centralizing the monitoring information in:
<Cluster>.status([options])
In this release, we’ve extended the status() command to provide more information relevant to diagnosing errors.
Let’s dive into those additions with some examples. “A picture is worth a thousand words!”
A cluster member is expelled from the Cluster
Previous to 8.0.23, whenever a Cluster member was expelled from the Cluster it would simply be displayed as a (MISSING) member. However, there are numerous reasons that can cause a member to go (MISSING) such as Group Replication being stopped, the member has crashed, or some replication error caused it.
Using the extended option of Cluster.status() could be valuable in the sense that at least it would provide the instance member Role as reported by Group Replication. However, it did not provide any extra information regarding the cause of the issue.
For those reasons, we have included in the default output of Cluster.status():
- The
memberStatewhenever the corresponding instance state is notONLINE. This information comes directly fromperformance_schema.replication_group_members. - A new
instanceErrorsfield for each instance, displaying diagnostic information that can be detected for that instance that is notONLINE
The following example shows the output of the command for a scenario on which Group Replication was manually stopped on an instance:
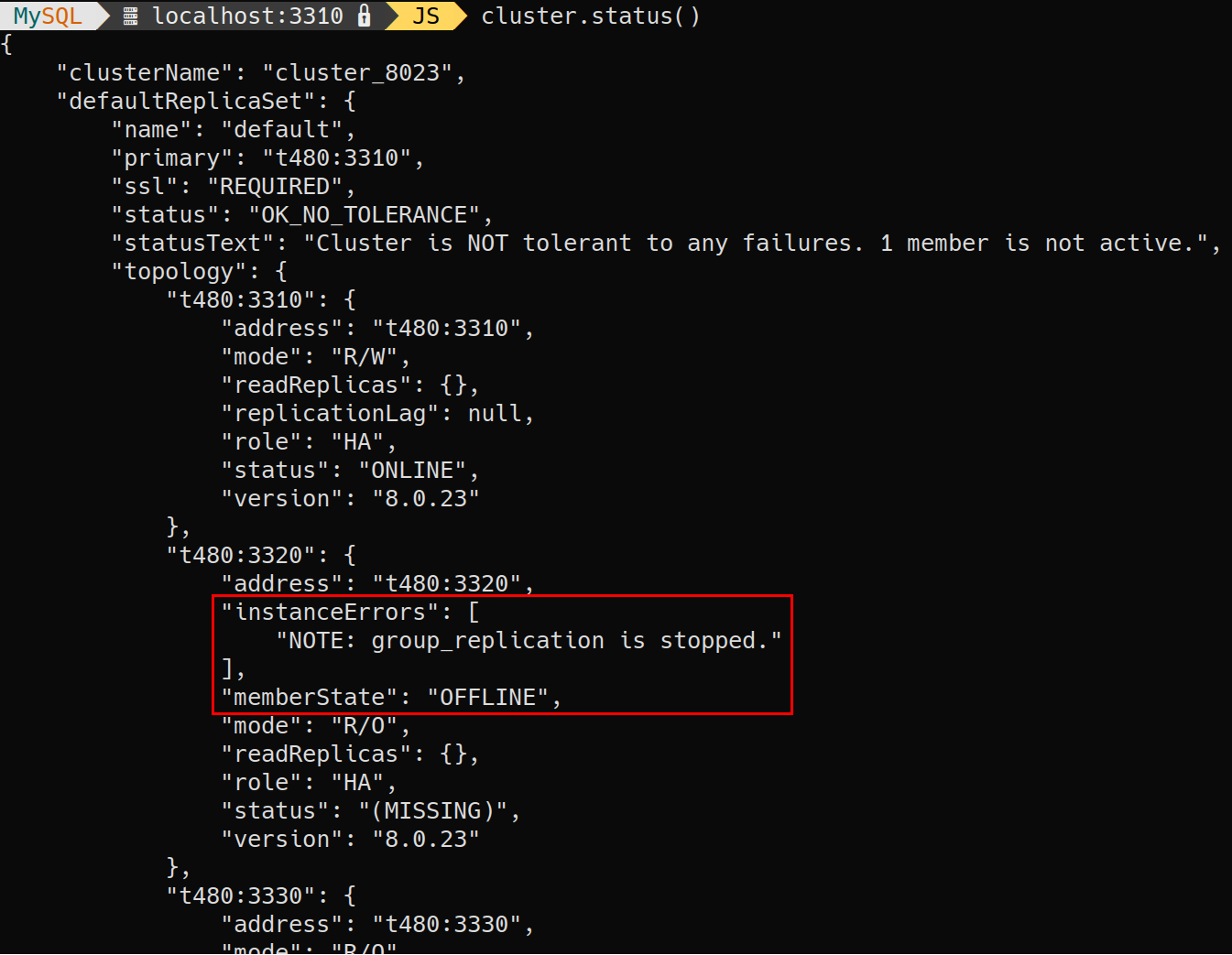
Note: The information depends on whether the instance is reachable or not.
Split-brain
Split-brain can be detected whenever an instance is not part of the majority group but it reports itself as being ONLINE and is reachable:
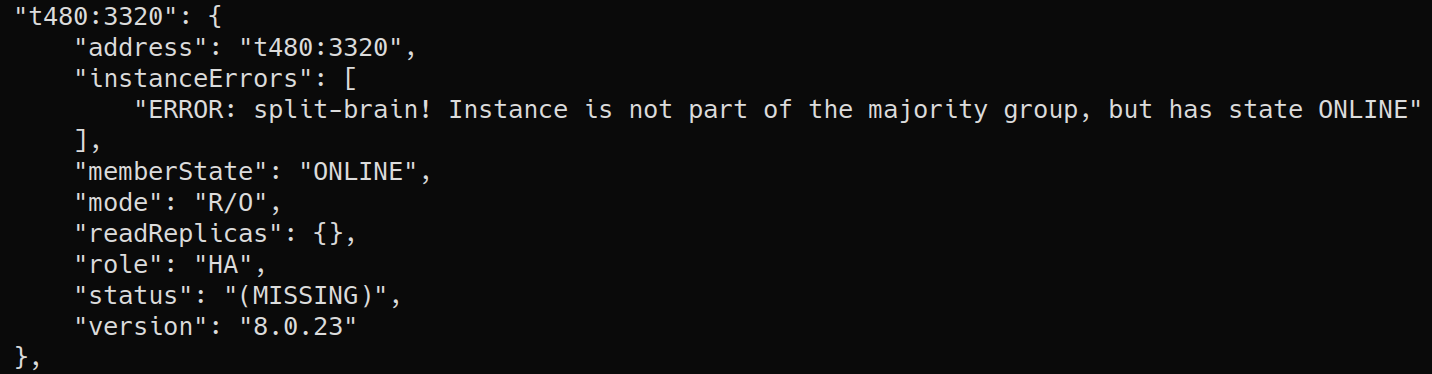
Applier error
If a replication error happens, the member could be stuck on RECOVERING for quite a while until it eventually fails and goes (MISSING). The only way to diagnose what really happened was to check the error log.
This is certainly not user friendly, so we have also included checks to verify whether the cause of a member to go into ERRORstate:
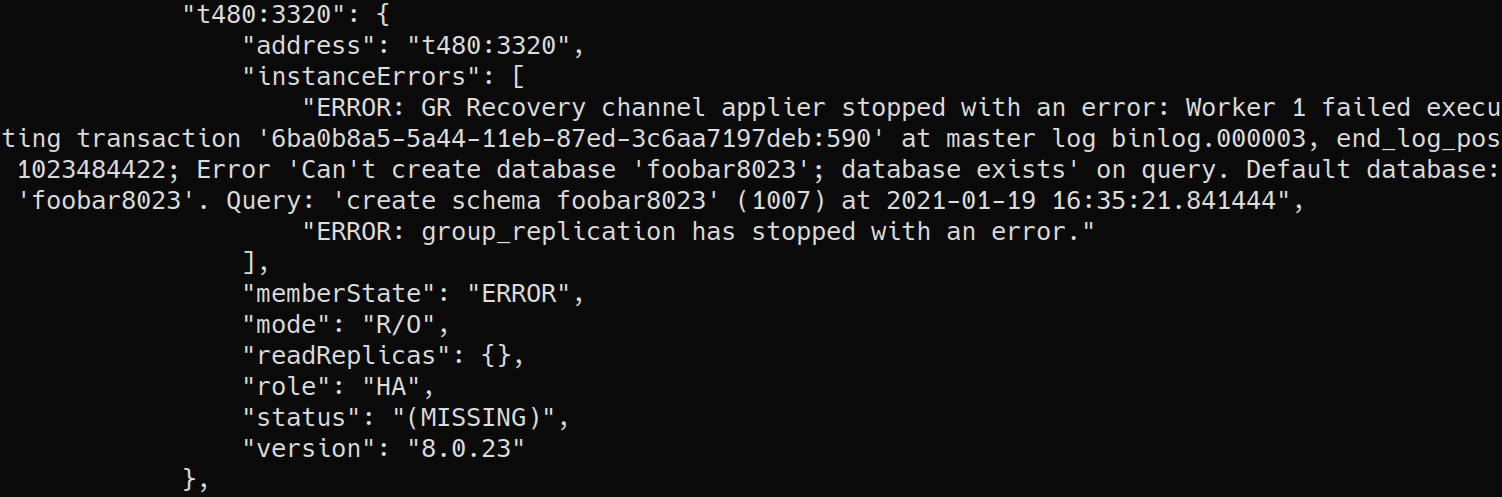
Other Diagnostics
Some particular scenarios such as restoring a Cluster member from a backup may imply a change on the server_uuid even though the member is running on the same host:port so it could rejoin the cluster automatically. However, since the server_uuid is used as a unique identifier of an instance, the AdminAPI would not understand that the instance was rejoined and would mark it as (MISSING).
Similarly, an instance that belongs to the Group Replication group but it does not to the metadata is now identified and reported in Cluster.status()

Summarizing the diagnostics
The following issues are detected and identified in the new field instanceErrors:
- SECONDARY member with
super_read_onlydisabled - Recovery channel error
- Applier channel error
- Member part of the Group Replication group but not of the metadata
- Reachable OFFLINE member (GR plugin stopped)
- Split-brain
- Member
server_uuiddoes not match what is recorded in the metadata
Replication info
Similar to what’s available in ReplicaSet.status(), we have included information about the replication recovery channel whenever a member is performing incremental recovery, in a new recovery field.
Note: This information is only available if the extended has a value > 0

Multithreaded replication appliers
MySQL InnoDB Cluster and InnoDB ReplicaSet rely on different replication mechanisms, namely, Group Replication and Asynchronous Replication. However, even though the two replication protocols are different in terms of data dissemination, both rely on an asynchronous mechanism to process and apply the binlog changes. The time interval from the moment a transaction is committed on a primary until it is committed on a secondary member is usually called the replication lag.
That said, either technology can suffer from replication lag; one of the most discussed and dreadful matters that MySQL DBAs have to face in production environments.
Fortunately, many improvements in this area have been made since MySQL 5.7. For example, with MySQL 8, a new mechanism to track independent transactions was introduced, based on the WRITESET of each transaction. By evaluating which transactions do *not* have interdependencies and can be executed in parallel on the binary log applier, this mechanism greatly improves the throughput of the applier.
Although those improvements are available for some time, tweaking the settings is necessary to overcome the replication lag problem and, up to this release, the replication applier used a single-threaded applier by default.
Considering that many common workloads have a large number of small transactions happening concurrently and that most modern servers have high processing capabilities, parallelization in replication definitely makes a difference!
For those reasons, InnoDB Cluster and InnoDB ReplicaSet now support and enable by default parallel replication appliers.
Required settings
InnoDB Cluster and ReplicaSet require that the MySQL servers have some settings in place to be able to operate. To enable parallel replication appliers by default, we have extended the settings to include the following:
-
transaction_write_set_extraction=XXHASH64(Already a requirement for InnoDB Cluster but not for InnoDB ReplicaSet) slave_parallel_type=LOGICAL_CLOCKbinlog_transaction_dependency_tracking=WRITESETslave_preserve_commit_order=ON
Nothing changes regarding how to check and configure your instances to be ready for InnoDB Cluster/ReplicaSet usage, the commands were simply extended to also check and enable automatically the settings listed above:
- Check the requirements with:
dba.checkInstanceConfiguration() - Configure the instance to be ready with:
dba.configureInstance() / dba.configureReplicaSetInstance()
Below, an example of configuring an instance to be ready for InnoDB Cluster usage with dba.configureInstance():

Applier Worker Threads
Multithreaded replication relies on several threads executing tasks. That number of threads can be configured and tweaked according to one’s use-case. We have decided that 4 is a reasonable number that suits typical deployments and workloads so we made that the default.
It’s possible to change this default number whenever you configure an instance for InnoDB Cluster/ReplicaSet usage. A new option named applierWorkerThreads was added to dba.configureInstance() / dba.configureReplicaSetInstance().
For example:
|
1
2
|
mysql-js> dba.configureInstance("clusteradmin@t480:3330", {applierWorkerThreads: 2, restart: true}) |
And, as with any other settings, you can consult the settings in place for your Cluster/ReplicaSet by using the
.options() command.
Tweaking the number of applier worker threads
Should you need to tweak the number of threads for your running Cluster/ReplicaSet and you can rely on dba.configureInstance() / dba.configureReplicaSetInstance() to do so. Similarly as when configuring the instances to be ready, you can change the current value of the threads number:
For example:
|
1
2
|
mysql-js> dba.configureInstance("clusteradmin@t480:3320", {applierWorkerThreads: 16}) |
Note: Be aware that even though you can change the settings for online members it doesn’t have immediate effect, it requires a rejoin (stop and start GR) of the instance.
Cluster/ReplicaSet upgrades are affected?
When you upgrade a Cluster or a ReplicaSet that has been running a version of MySQL server and MySQL Shell earlier than 8.0.23, multithreaded replication may not be enabled on the instances since those settings weren’t requirements.
MySQL Shell detects that when running the .status() command and guides you accordingly to do the changes and take advantage of this feature.

Notable Bugs fixed
BUG#26649039 – SHELL FAILS TO IDENTIFY REJOINING MEMBER WITH A NEW UUID
If a Cluster member is taken out of the Cluster and afterward restored from a backup using, for example, MEB, then whenever the instance rejoins the cluster either automatically or via Cluster.rejoinInstance()it was marked as being a (MISSING)member of the Cluster.
This happened because the AdminAPI uses the server_uuidas the unique identifier of an instance, and since the server_uuidmay change after the backup is restored, the AdminAPI would not understand that the instance is the same one.
This has been fixed together with the new Cluster.status() diagnostics described above, i.e. a new check has been added when an instance is rejoined so when the instance is not found on the metadata through the UUID, it’s searched using its host and port, if found, the metadata will be updated based on the options used for the rejoin operation.
BUG#31757737 – INNODB CLUSTER OPERATIONS SHOULD AUTO-CONNECT TO PRIMARY
InnoDB Cluster operations such as Cluster.addInstance()or Cluster.rejoinInstance()would fail if the shell’s active session was established to a Secondary member of the Cluster. However, considering that Shell is capable of knowing which member is the Primary and that all cluster members must have the same cluster-admin credentials, the commands should not fail and should automatically use the primary’s connection.
That’s exactly how this bug was solved. Now, regardless of which member of the instance you have established a connection to obtain the cluster’s object, operations will be executed on the right member accordingly.
BUG#27882663 – CLUSTER.STATUS() DOES NOT SHOW ACTIVE GR MEMBERS NOT IN METADATA
The Cluster.status()operation didn’t show information about members part of the cluster which did not belong to the metadata. That information would only be seen when using Cluster.rescan(). However, not showing all members in the Group Replication group even if not present in the metadata hides the unexpected/undesired participation of the instances in the cluster (not managed by InnoDB Cluster).
This has been fixed together with the improvements in Cluster.status()by listing members that are participating in the Cluster even though are not registered in the Metadata and by indicating to the user the steps to include them in the Metadata.
BUG#32112864 – REBOOTCLUSTERFROMCOMPLETEOUTAGE() DOES NOT EXCLUDE INSTANCES IF IN OPTION “REMOVEINSTANCES” LIST
dba.rebootClusterFromCompleteOutage() requires an active session on
MySQL Shell to:
- Obtain the cluster members as registered in the Metadata.
- Determine which of the cluster members has the GTID superset.
- If the active session is not to the member with the GTID
superset the command aborts and indicates to the user which is
the instance with the GTID superset.
However, the GTID superset check is done using all instances (registered
in the Cluster’s metadata) reachable by Shell.
If an instance has a diverging GTID-set and the user wants to explicitly
remove it from the cluster, the operation would be blocked since the
Shell cannot determine which instance has the GTID superset. Depending
on the point-of-view, different instances can be considered as the most
up-to-date.
Also, it should be possible for users to reboot a cluster by picking a
particular instance even though it’s not the one most up-to-date, as
long as they indicate the other instances are not meant to be rejoined
by using the command’s options/prompts.
This patch fixed that by ensuring that if the user explicitly sets the
removeInstances variable or answers “NO” to the prompt regarding
instances rejoin, those instances must be excluded from the GTID
superset validation.
BUG#31428813 – DBA.UPGRADEMETADATA() FAILS WITH ERROR: UNKNOWN COLUMN ‘MYSQL.ROUTER’ IN ‘FIELD LIST’
Upgrading the Metadata schema with dba.upgradeMetadata() failed if
ANSI_QUOTES were used in the sql_mode.
This was caused by a specific query to insert data into the routers
table of the metadata schema which was using double quotes to quote a
string. When the sql_mode is set to use ANSI_QUOTES, MySQL treats " as
an identifier quote character and not as a string quote character
resulting in an error whilst running that query.
This patch fixed that by ensuring that the upgrade metadata command
prepares the session to be used by the AdminAPI, which, amongst other
sanity checks it ensures the sql_mode used by that session uses the
default values to avoid user-set incompatible settings
BUG#32152133 – REPLACE CHANGE MASTER/START SLAVE TERMINOLOGY WITH CHANGE SOURCE/START REPLICA
As in the MySQL Server, deprecated terminology in replication related features was updated, while keeping backward compatibility wherever necessary.
This one specially handled the following deprecations on MySQL Replication commands:
CHANGE MASTER TOSTART SLAVE UNTIL MASTER_LOG_POS, MASTER_LOG_FILE
In favor of the new:
CHANGE REPLICATION SOURCE TOSTART REPLICA UNTIL SOURCE_LOG_POS, SOURCE_LOG_FILE
And their parameters:
MASTER_HOSTMASTER_PORTMASTER_*
In favor of:
SOURCE_HOSTSOURCE_PORTSOURCE_*
You can read about the general change at the MySQL Terminology Updates blog post.
Try it now and send us your feedback
MySQL Shell 8.0.23 GA is available for download from the following links:
- MySQL Community Downloads website: https://dev.mysql.com/downloads/shell/
- MySQL Shell is also available on GitHub: https://github.com/mysql/mysql-shell
And as always, we are eager to listen to the community feedback! So please let us know your thoughts here in the comments, via a bug report, or a support ticket.
You can also reach us at #shell and #mysql_innodb_cluster in Slack: https://mysqlcommunity.slack.com/
The documentation of MySQL Shell can be found in https://dev.mysql.com/doc/mysql-shell/8.0/en/ and the official documentation of InnoDB Cluster and InnoDB ReplicaSet can be found in the AdminAPI User Guide.
The full list of changes and bug fixes can be found in the 8.0.23 Shell Release Notes.
Enjoy, and Thank you for using MySQL!