The MySQL Development Team is very happy to announce the second 8.0 Maintenance Release of InnoDB Cluster!
In addition to bug fixes, 8.0.13 brings some new exciting features:
- Defining the next primary instance “in line”
- Defining the behavior of a server whenever it drops out of the cluster
- Improved command line integration for DevOps type usage
Here are the highlights of this release!
MySQL Shell
For this release, we have focused on extending the AdminAPI to support and make use of new Group Replication features, but also to improve the Shell itself in regards to DevOps usage. On top of that, many bug fixes were addressed.
Define the next primary instance “in line”
A default cluster setup runs in single-primary mode, i.e. the cluster has a single-primary server that accepts read and write queries (R/W). All the remaining members accept only read queries (R/O).
Upon a failure of the primary member, an automatic primary election mechanism takes place and chooses a new primary. This mechanism decides which of the members shall become the new primary by picking the one with the lowest value of server UUID.
Up to now, it was impossible to control the outcome of the primary election algorithm in single-primary mode. However, that’s a very desired functionality in production environments… Many scenarios would benefit or even require, the ability to choose which shall be the next elected primary.
For example, a DBA should be able to decide beforehand which shall be the primary whenever a planned maintenance operation on the current primary happens. Also, if a cluster is deployed in different data centers, the DBAs should be able to ensure that a specific set of servers have precedence over other in the election process thus ensuring that primaries are always in a particular data center. Last but not least, it’s common that primaries benefit from being run in machines with higher capacities thereby it is an asset to ensure which members shall be elected as primaries in the event of failures.
Summarizing, there are two important user stories regarding the primary election:
- As a DBA, I want to be able to define which member of a cluster shall be elected as next primary.
- As a DBA, I want to be able to define the order of priorities for the election of new primaries of a cluster, based on a numeric value.
In 8.0.13, we have introduced an option that allows influencing the primary election by providing a member weight value for each cluster member. The member with the highest weight value is elected as the new primary.
In order to support this feature, the following AdminAPI commands have been extended with a new option memberWeight that allows setting the weight value for the target instance:
dba.createCluster()<Cluster.>addInstance()
 …
… …
…

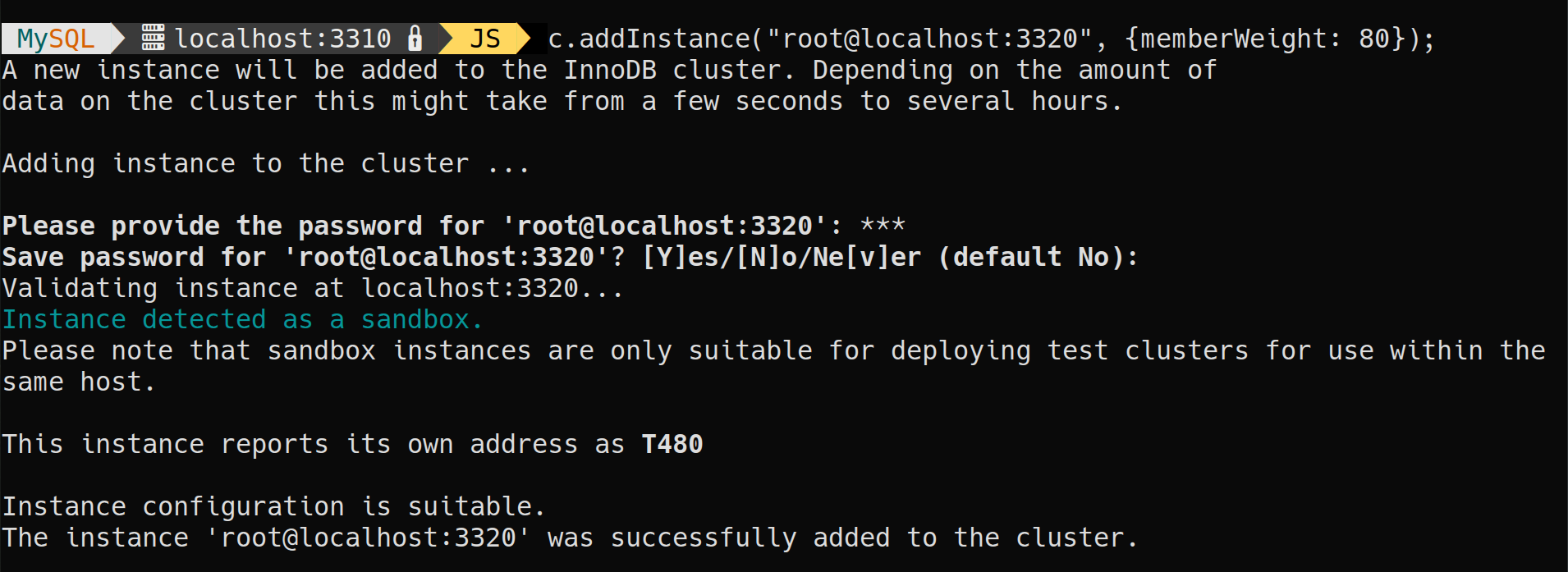
Note: When the primary election takes place, if multiple servers have the same
memberWeightvalue, the servers are then prioritized based on their server UUID in lexicographical order (the lowest) and by picking the first one.
Define the behavior of a server whenever it drops out of the cluster
The default behavior when a server leaves a cluster unintentionally, i.e. not manually removed by the user (DBA), is to switch itself automatically to super-read-only mode.
The reason for such behavior relies on the premise that an instance that left a cluster shall not receive any updates, thus safeness is improved.
However, even though updates to servers that left a cluster are blocked, reads are not, thereby the chance of stale-reads increases. Also, if an instance gets stuck on a minority partition, it will still be readable, thus allowing stale reads as well.
To minimize the possibility of stale reads, Group Replication has introduced an option to allow defining what should be the behavior when an instance leaves a cluster unintentionally. Apart from the behavior on which the instance sets itself to super-read-only, a new one was added that makes the instance to automatically shut itself down on that event.
Summarizing, the user stories for this new feature are:
- As a DBA, I want to be able to define if an instance should automatically set itself to super-read-only when it involuntarily leaves a cluster.
- As a DBA, I want to be able to define if an instance should automatically shutdown when it involuntarily leaves a cluster.
In order to support this feature, the following AdminAPI commands have been extended with a new option exitStateAction that allows defining the behavior of a server whenever it drops the cluster unintentionally:
dba.createCluster()<Cluster.>addInstance()
 …
…  …
… 
Improved command line integration for DevOps type usage
MySQL Shell is an interactive JavaScript, Python, and SQL command-line client supporting development and administration for the MySQL Server and InnoDB clusters. The Shell provides a natural interface for all ‘development and operations’ (DevOps) tasks related to MySQL, by supporting scripting with development and administration APIs.
However, apart from being a command-line client, the Shell is also a console interface.
Until now, the support for using the shell as a console interface was quite limited since its usage was confined to the batch script execution via cmdline with the --execute(-e) option.
For example, to create a cluster via cmdline, the DBA would call the shell as follows:
$ mysqlsh myAdmin@localhost:3306 -e "dba.createCluster('testCluster', {memberWeight: 65, exitStateAction: 'READ_ONLY'});"
This is neither acceptable nor a norm of general usage of a console interface. Plus, complex quoting patterns will certainly become troublesome.
In 8.0.13, we have introduced a general purpose command line handling mechanism which can be used to invoke built-in shell commands, with arbitrary parameters, in a syntax that requires minimal extra typing, quoting and escaping.
Creating a cluster via cmdline, can now be done as follows:
$ mysqlsh myAdmin@localhost:3306 -- dba create-cluster testCluster --member-weight=65 --exit-state-action=READ_ONLY
Stay tuned for a new blog post coming soon covering all the details of the API Command Line Integration for DevOps!
MySQL Router
Source code moved to mysql-server repo
A lot of work went into moving the source-code of MySQL Router into the MySQL Server’s source-tree
As a result of this change:
- package names are more aligned,
- MySQL Router is always released in sync with MySQL Server,
- code between both products can be shared more easily going forward
Note: Code previously found in https://github.com/mysql/mysql-router
is now located in https://github.com/mysql/mysql-server/tree/8.0/router.
Packaging changes
To align package names with MySQL Server, the community package name prefix changed from “mysql-router-” to “mysql-router-community-“. This change also allows upgrading from MySQL Router 2.1 to 8.0.
Additionally, a “mysql-router” meta package was added that redirects “mysql-router” to “mysql-router-community”.
Important Bugs fixed
The log level was changed from INFO to DEBUG for the InnoDB cluster Metadata server and replicaset connections. Because since 8.0.12 MySQL Router’s ttl configuration option defaults to 0.1, these each generate 10 log entries per second. (Bug #28424243)
See the Release Notes for a complete list of all bugs fixed in this release.
Summary
This is the second Maintenance Release of MySQL InnoDB Cluster, but our continuous work to improve the ease-of-use, power and flexibility of InnoDB cluster won’t stop!
InnoDB cluster will not only continue to make MySQL easier for all users but also give full advanced control and capabilities to power users.
As always, we are eager to listen to the community feedback! So please let us know your thoughts here in the comments, via a bug report, or a support ticket.
You can also reach us at #shell and #router in Slack: https://mysqlcommunity.slack.com/
The official documentation can be found in the MySQL InnoDB Cluster User Guide.
The full list of changes and bug fixes can be found in the 8.0.13 Shell and Router Release Notes
Enjoy, and Thank you for using MySQL!