In this post we describe MySQL connections, user threads, and scaling. We hope that an increased understanding of how MySQL works will help application developers and system administrators to make good choices and trade-offs. We describe how connections work in a plain community server and we do not cover related topics such as thread pooling, resource groups, or connection multiplexing in this post.
The MySQL Server (mysqld) executes as a single OS process, with multiple threads executing concurrent activities. MySQL does not have its own thread implementation, but relies on the thread implementation of the underlying OS. When a user connects to the database a user thread is created inside mysqld and this user thread executes user queries, sending results back to the user, until the user disconnects.
When more and more users connect to the database, more and more user threads execute in parallel. As long as all user threads execute as if they are alone we can say that the system (MySQL) scales well. But at some point we reach a limit and adding more user threads will not be useful or efficient.
Connect and Disconnect
Connections correspond to Sessions in SQL standard terminology. A client connects to the MySQL Server and stays connected until it does a disconnect. Figure 1 illustrates what happens when a MySQL Client connects to a MySQL Server.
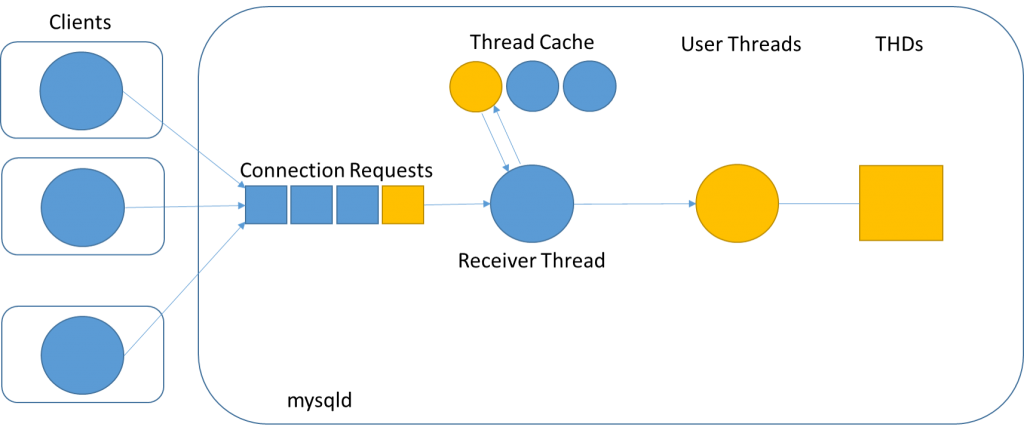
Clients. A MySQL Client is a command line tool or an application that talks to the MySQL Server over the MySQL Client-Server protocol using the libmysqlclient library or some of the many MySQL connectors. A single multi-threaded client can open many connections to the server, but for simplicity we here say one client opens one connection to the server.
Connection Requests. The MySQL Clients send connection requests to the MySQL Server. A connection request is simply a TCP-IP connect message sent to port 3306 on the server host machine.
Receiver Thread. Incoming connection requests are queued and then processed by the receiver thread one by one. The only job of the receiver thread is to create a user thread, further processing is done by the user thread.
Thread Cache. The receiver thread will either create a new OS thread or reuse an existing “free” OS thread if found in the thread cache. The thread cache used to be important for connect speed when OS threads were costly to create. Nowadays creating an OS thread is relatively cheap and the thread cache can perhaps be said to be legacy. The thread_cache_size default value is calculated as 8 + (max_connections / 100) and is rarely changed. It might make sense to try increasing the thread cache in cases where number of connections fluctuates between having very few connections and having many connections.
User Thread. It is the user thread that handles the client-server protocol, e.g. sends back the initial handshake packet. This user thread will allocate and initialize the corresponding THD, and then continue with capability negotiation and authentication. In this process the user credentials are stored in the THD’s security context. If everything goes well in the connection phase, the user thread will enter the command phase.
THD. The connection is represented by a data structure called the THD which is created when the connection is established and deleted when the connection is dropped. There is always a one-to-one correspondence between a user connection and a THD, i.e. THDs are not reused across connections. The size of the THD is ~10K and its definition is found in sql_class.h. The THD is a large data structure which is used to keep track of various aspects of execution state. Memory rooted in the THD will grow significantly during query execution, but exactly how much it grows will depend upon the query. For memory planning purposes we recommend to plan for ~10MB per connection on average.

Figure 2 illustrates the command phase. Here, the client sends queries to the server and get results back in several rounds. In general, a sequence of statements can be enclosed by a start transaction and a commit/rollback. In this case there is a need to keep track of the transaction context. In auto-commit mode, each statement will be executed as a transaction (each statement constitutes the full transaction context). In addition there is the session context, i.e. the session can hold session variables, user variables, and temporary tables. Thus, as long as the context is relevant for executing queries, all queries on a connection must use the same THD.
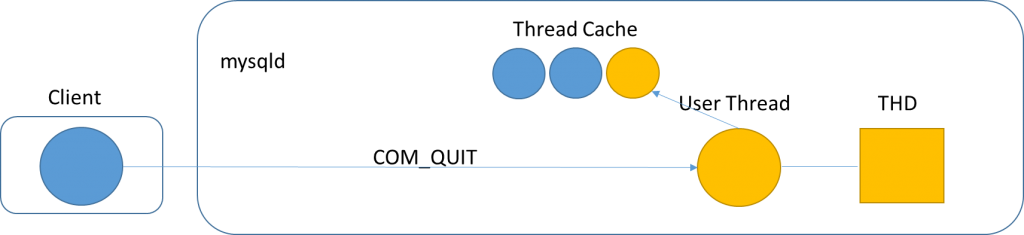
Figure 3 illustrates what happens when a MySQL Client disconnects from a MySQL Server. The Client sends a COM_QUIT command which causes the server to close the socket. A disconnect can also happen when either side closes its end of the socket. Upon a disconnect the user thread will clean up, deallocate the THD, and finally put itself in the Thread Cache as “suspended” if there are free slots. If there are no free slots, the user thread will be “terminated”.
Short Lived Connections
A short lived connection is a connection that is only open for a short period of time. This is typically the case for PHP applications, the client opens a connection, executes a simple query, and then closes the connection. Due to its architecture, MySQL is really good at accepting new connections at a high speed, up to 80.000 connects/disconnects per second as shown in Figure 4 below.
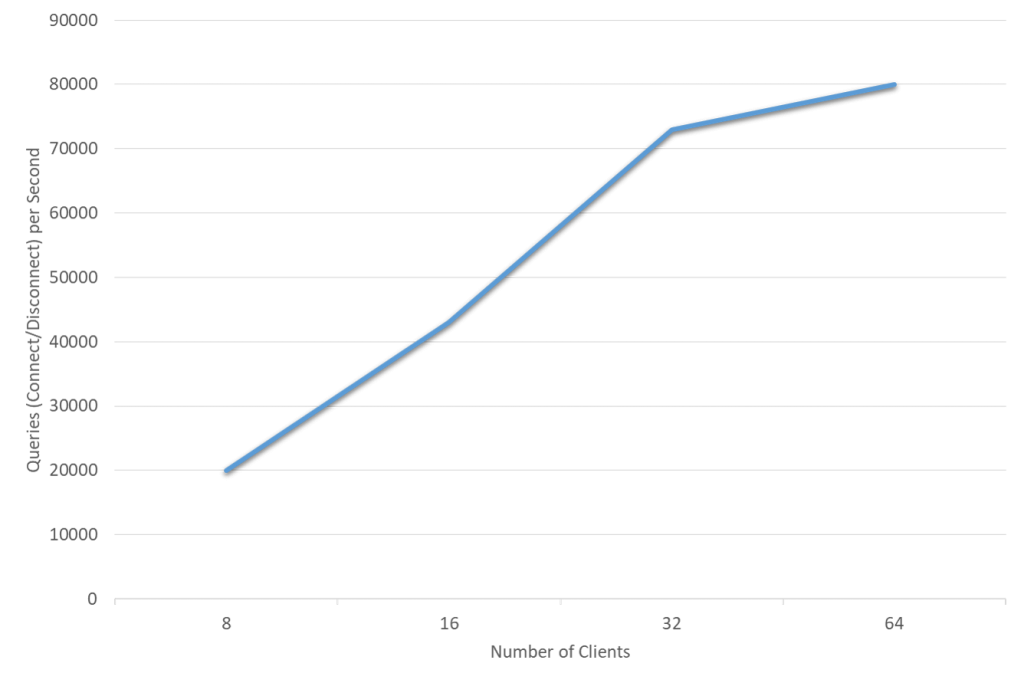
Figure 4 illustrates MySQL Connect/Disconnect performance. The test machine has Intel(R) Xeon(R) e5-2699 v4 CPU, 2CPU-sockets, 22 Cores-HT per socket, 2.20GHz (Broadwell). We are running Sysbench clients and MySQL server on the same set of cores. Each Sysbench thread connects though a socket, issues a point select, disconnects and then repeats. Data is in memory. The graph shows the TPS for varying number of Clients, 20.000 for 8 clients, 43.000 for 16 clients, 73.000 for 32 clients, and 80.000 for 64 clients.
MySQL has always been relatively good at doing connects/disconnects, but got really good with some help from Facebook in MySQL 5.6. See blog posts by Domas Mituzas and Yoshinori Matsunobu. Some additional improvements were done in MySQL 5.7.
Long Lived Connections
A long lived connection is a connection that is open “indefinitely”. For example one might have a Web server or an Application server opening many connections to the MySQL server and keeping them open until the client (Web/Application server) is stopped, perhaps for months.
The maximum number of clients the server permits to connect simultaneously is determined by the max_connections system variable, configurable by the user. When this maximum is reached the server will not accept new connections until one of the active clients disconnects. The MySQL server will have one user thread (with its THD) for the life time of the connection, as illustrated by Figure 5.
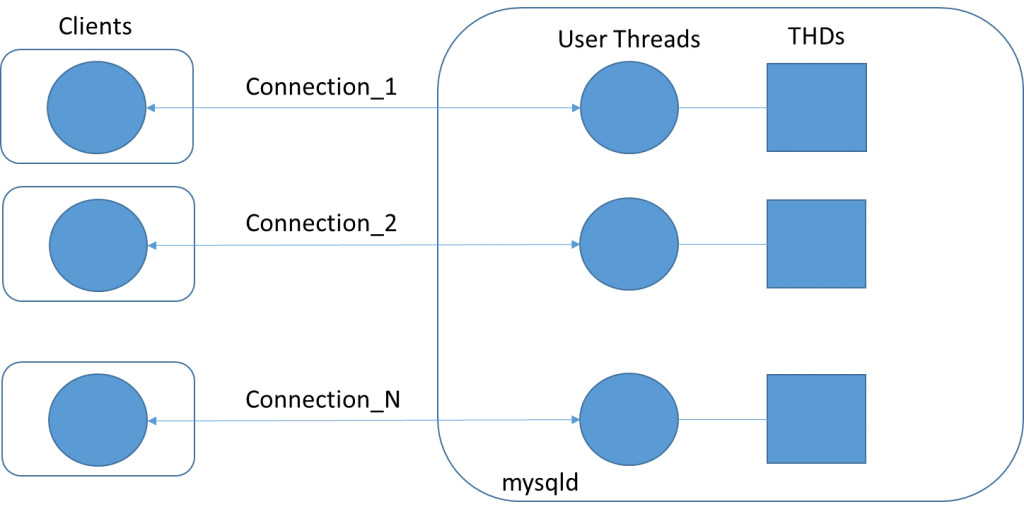
So, what is the best value for max_connections? The answer is “it depends”. It will mainly depend upon two things, the client load and the hardware MySQL is running on.
A connection can be more or less busy. A connection is very busy when the client sends back-to-back queries to the server, that is, each time the client gets a result back it immediately sends a new query to the server. A connection is not busy if the client now and then sends a query to the server and there are long pauses between receiving the result from one query until the next query is sent (idle periods). In a situation when there are many connections and all connections are very busy we say that the MySQL server is under heavy load.
When connections are less busy one can accept more connections. Let us say a given server instance is maxing out on 5000 TPS for a user load over 200 connections. The same server will then be able to handle the same concurrency (5000 TPS) over 10000 connections, but adding more connections will not increase the concurrency. However, 10000 connections will require higher memory usage for (more) THDs and will result in less efficient use of hardware. One also needs to be aware that when setting max_connections to 10000 there is a risk of overloading the server if all connections send more and more queries exceeding the 5000 TPS overall capacity. In this case the server might start thrashing.
What is the maximum load? And how do I know that the server has reached maximum load? You have to test your workload, for example as follows: You can start with 2 busy clients and measure server TPS and Latency, and then continue step-wise by doubling the number of clients for each step. Initially, TPS will increase and latency will be constant for each step you take. At some point TPS will be the same as before and latency will start to increase, and this is the maximum load and the maximum number of (useful) clients.
What is the maximum user thread concurrency MySQL can handle? Let us find a load which reaches thread concurrency limitations before it hits other limitations. A load that fits this requirement is Primary Key look-ups (Sysbench POINT SELECT) of data present in main memory (buffer pool). Since the primary key in MySQL/InnoDB is stored together with the data (clustered index) the only thing MySQL has to do for a point select is to navigate the in-memory B-tree, find the record, and return the result.
Since we want to illustrate thread concurrency we choose a machine with 48 CPU cores. The test machine has Intel(R) Xeon(R) Platinum 8168 CPU, 2CPU-sockets, 24 Cores-HT per socket, 2.70GHz (Skylake). We are running Sysbench clients and MySQL 8.0.15 server on the same set of cores.
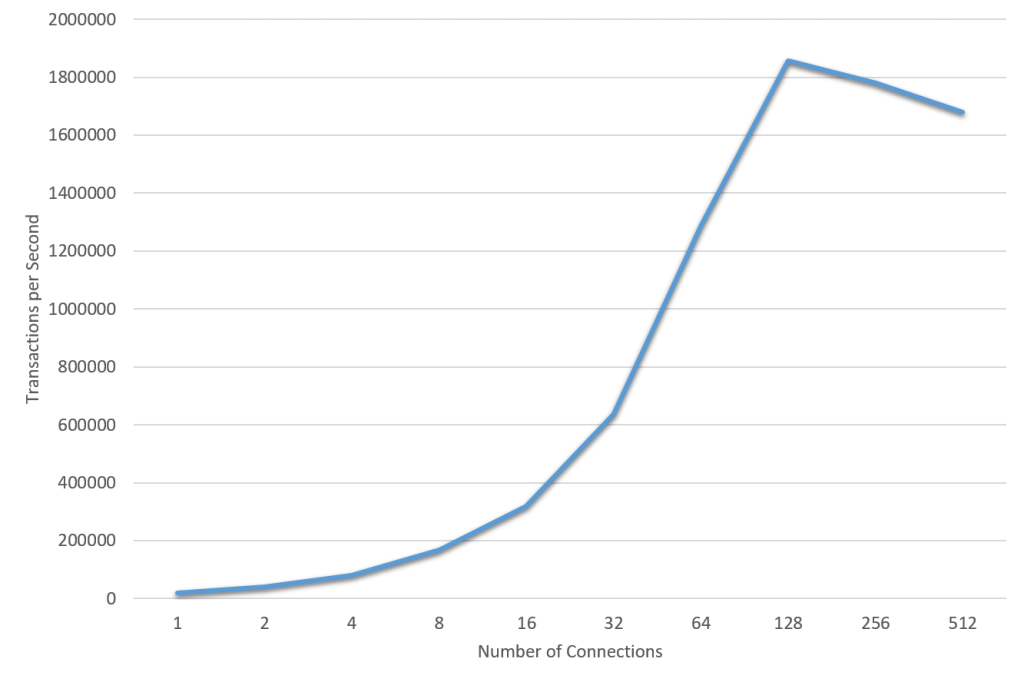
Figure 6 shows the relationship between number of connections (user threads) and the overall load in terms of Transactions per second (TPS). Each client generates POINT SELECT load back-to-back. Initially, the overall load grows close to linear with respect to the number of concurrent clients, for example 16 clients gives you 300 thousand TPS, 32 clients gives you 600 thousand TPS, 64 clients gives you 1.2 million TPS. The maximum is reached with 128 clients with 1.8 million TPS. With more than 128 clients the increase stops and then starts to decline. So, what is happening here?
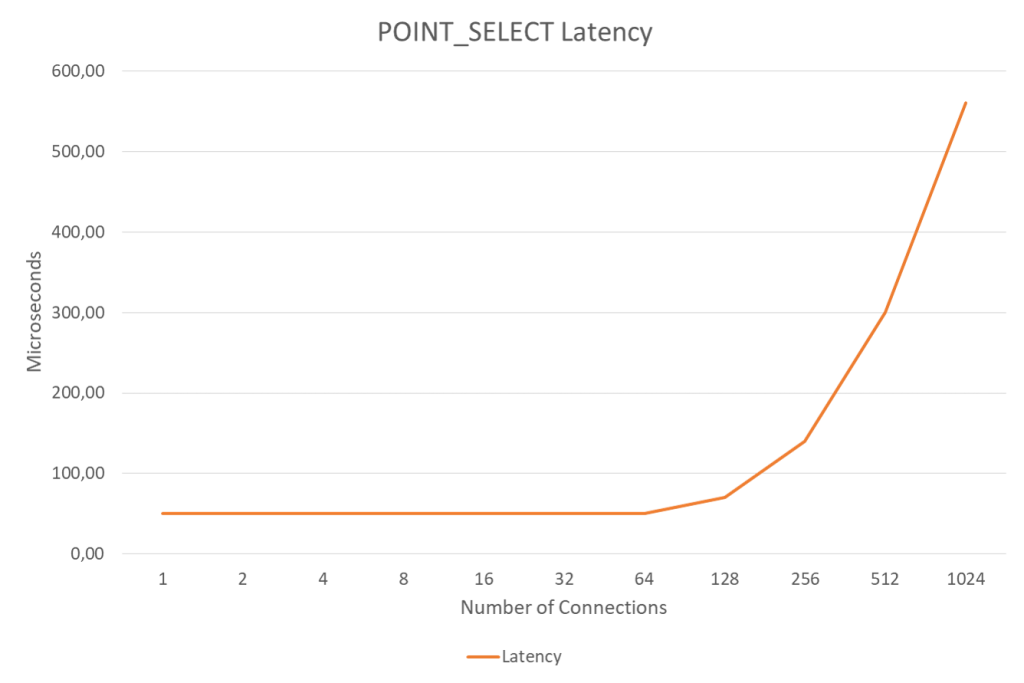
Let’s take a look at query latency depicted in Figure 7 above. From 1 to 64 clients the query response time (latency) is constant around 50 microseconds. It then grows to 70 microseconds for 128 clients, 140 microseconds for 256 clients, and 300 microseconds for 512 clients.
MySQL reaches maximum efficiency for 128 user threads, with its max TPS (1.8 million) and low latency (70 microseconds). Thus, at its peak, the user thread per core ratio is 128/48 = 2.7, and from then on the efficiency goes down. Adding more user threads will cause latency to grow and it will depend upon application requirements what is acceptable latency, i.e. the defined service level agreement. In our example here, 95% of all transactions had latency less than 210 microseconds, which might be good enough for most applications. This gives us a user thread per core ratio is 256/48 = 5.3. Based on accumulated experience we recommend at maximum 4 times number of user threads as the number of real CPU cores, thus 4×48=196 user threads in our example.
MySQL did not always scale as well as shown above. MySQL 5.6 came with major RO scaleability improvements, but you had to use the READ-ONLY TRANSACTIONS feature and AUTO COMMIT to get the effect. MySQL 5.7 came with auto-discovery of RO transactions and removed the contention around Meta Data Locking, THR_LOCK and the InnoDB trx_sys mutex and the lock_sys mutex. For those interested in the complete in-depth history, see Dimitri’s posts here, here, here, here, and here.
What happens if you hit some other bottleneck before you hit the thread concurrency bottleneck? One such example is illustrated in Figure 8 below. Figure 8 shows the same Sysbench POINT SELECT query as in Figure 6 above, but now the data volume is much higher and data must be read from disk most of the time. In this example we are using the fast Intel Optane SSDs but are still able to saturate the disk-to-memory bandwidth. I.e. the user threads in this example are waiting for disk pages to be brought in from the SSD to the InnoDB buffer pool. The overall result is a lower TPS (1 million as compared to 1.8 million) since each query will spend more time waiting for data. Adding more clients increases TPS until the disk capacity is saturated, at roughly 128-256 connections. At this point all user threads are just waiting for IO and adding more user threads will be counter productive.
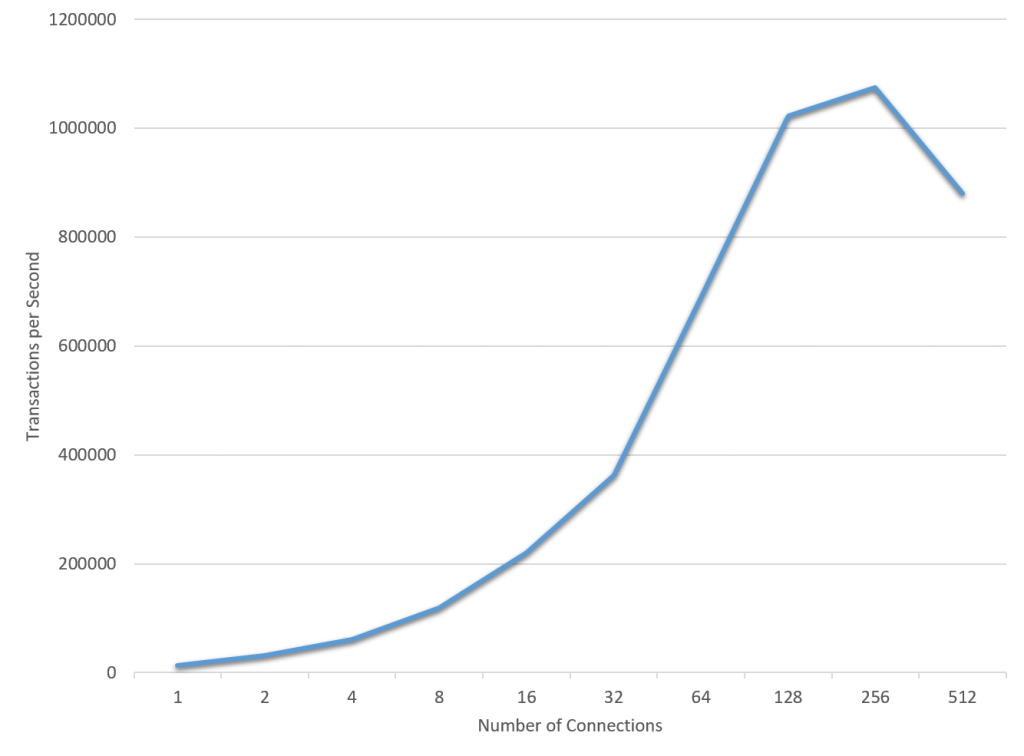
Dimitri’s post here discusses 8.0 improvements in IO Scalability , removing the contention around InnoDB fil_system mutex. In the current context it only goes to show that although the contention here is on Disk IO and TPS is lower(1.1 million), it still follows the same thread concurrency pattern as in the in-memory case above: Linear scalability up to 128 user threads, max out on 256 user threads reaching 1.1 million QPS.
What Limits Thread Concurrency?
A thread will happily execute instructions until it needs to wait for something or until it has used its timeshare as decided by the OS scheduler. There are three things a thread might need to wait for: A mutex, a database lock, or IO.
Mutex. A mutex protects a shared internal datastucture, i.e. when one needs to assure that only one thread can execute at any time. If one thread holds a mutex, the other threads must wait in line until it is their turn. The use of mutexes is an implementation technique and thus something that can be juggled by programmers as long as overall program correctness is maintained. Techniques include the use of lock free algorithms and to decompose protected resources into more fine grained resources to ensure that different threads ask for different mutexes (reducing contention on global resources). Much of the scalability work done by MySQL developers over the past 5-10 years has been centered around better usage of mutexes.
Locks. Database locks are in a certain sense the same thing but they are tied to database semantics and therefore more difficult to avoid. (MySQL/InnoDB is quite good at avoiding locks due to its multi-version concurrency control, MVCC). Database locks can broadly be divided into data locks (caused by SQL DML) and meta-data locks (caused by SQL DDL). A data lock such as a row lock will typically protect data being updated by one thread from being read or written by another thread. A meta-data lock will typically protect the database schema from concurrent, incompatible updates. Maintaining database semantics is more important than performance and scale so it is harder to remove locks than it is to remove mutexes. As a consequence, scalability bottlenecks caused by locks must often be resolved at the OLTP application design level, e.g. a better database schema design combined with better query designs. MySQL 8.0 also provides some new interesting features for application developers to avoid locking, e.g. NO WAIT and SKIP LOCKED.
Disk and Network IO. IO is something one tries to minimize whenever possible, and when not possible one tries to do it as efficiently as possible, e.g. pre-fetching, parallelizing, batching, etc. But at some point most user threads will need IO. When a user thread needs to wait for IO the OS will typically put the thread in wait state and give the CPU to another waiting thread. This will work well if the new thread is capable of making progress and will lead to efficient use of the CPU. But, for example if the IO bandwith has been saturated, the new thread will potentially also just wait for IO and no progress can be made. So, thread concurrency will be limited by IO capacity, as we saw in Figure 8.
What happens when a thread is suspended by the OS? First, it is not progressing anymore. Second, it might hold mutexes or locks which prevent other threads from progressing. Third, when it is woken up again, cached items might have been evicted requiring data to be re-read. At some point more threads will just cause queues of waiting threads to grow and the system will be soon be jammed. The solution is to limit the number of user threads by limiting max_connections, just allowing as many concurrent user threads as the system can efficiently deal with.
The Role of Application Developers
In some cases application developers are in control of the overall system architecture, the database schema, and database queries. But perhaps more often than not, the application developers will be required to develop an application on top of an existing database. In both cases that application developer will need to pay attention to the queries sent to the database layer.
The classical use case for MySQL is Online Transaction Processing (OLTP) which typically has demanding response time requirements. Acceptable database response times are often specified in milliseconds and this will of course limit the type of queries which can be expected to run (perhaps combined with limitations on data volume and the structure of the database schema). This is often contrasted to Online Analytical Processing (OLAP) where there are more complex queries, but the query frequency is lower and response time requirements may be more relaxed.
Especially for OLTP, the application developer must take care in designing queries that can execute within certain response time SLA and that can be executed in parallel. It is not very hard to produce a workload which does not scale, for example many parallel clients doing nothing other than updating the exact same row in the same table (see alternative designs here).
Conclusion
- MySQL is very good at handling many clients connecting and disconnecting to the database at a high frequency, up to 80 thousand connect and disconnects per second
- MySQL scales well on multi-core CPUs and can deliver up to 2 million primary key look-ups per second on 48 CPU cores.
- Rule of thumb: Max number of connections = 4 times available CPU cores
- Efficient use of connections will depend upon user load, useful number of user connections can even be lower than number of CPU cores when the bottleneck is somewhere else than on the threading
- Check out your own load by doubling the number of connections until TPS no longer increases and latency starts to increase
Thank you for using MySQL !