The Write Ahead Log (WAL) is one of the most important components of a database. All the changes to data files are logged in the WAL (called the redo log in InnoDB). This allows to postpone the moment when the modified pages are flushed to disk, still protecting from data losses.
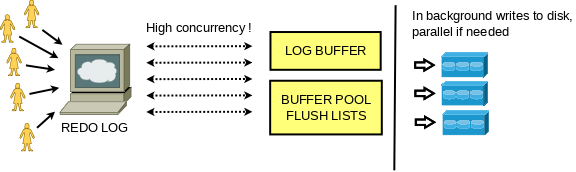
The write intense workloads had performance limited by synchronization in which many user threads were involved, when writing to the redo log. This was especially visible when testing performance on servers with multiple CPU cores and fast storage devices, such as modern SSD disks.
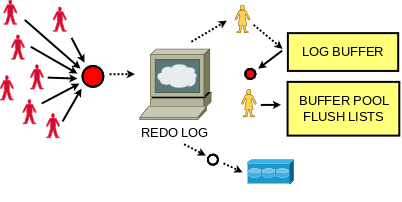
We needed a new design that would address the problems faced by our customers and users today and also in the future. Tweaking the old design to achieve scalability was not an option any more. The new design also had to be flexible, so that we can extend it to do sharding and parallel writes in the future. With the new design we wanted to ensure that it would work with the existing APIs and most importantly not break the contract that the rest of InnoDB relies on. A challenging task under these constraints.
Redo log can be seen as a producer/consumer persistent queue. The user threads that do updates can be seen as the producers and when InnoDB has to do crash recovery the recovery thread is the consumer. InnoDB doesn’t read from the redo log when the server is running.
But writing a scalable log with multiple producers is only one part of the problem. There are InnoDB specific details that also need to work. The biggest challenge was to preserve the total order of the dirty page list (a.k.a the flush list). There is one per buffer pool. Changes to pages are applied within so-called mini transactions (mtr), which allow to modify multiple pages in atomic way. When a mini transaction commits, it writes its own log records to the log buffer, increasing the global modification number called LSN (Log Sequence Number). The mtr has the list of dirty pages that need to be added to the buffer pool specific flush list. Each flush list is ordered on the LSN. In the old design we held the log_sys_t::mutex and the log_sys_t::flush_order_mutex in a lock step manner to ensure that the total order on modification LSN was maintained in the flush lists.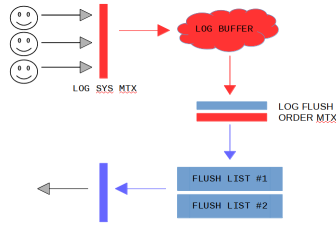
Note that when some mtr was adding its dirty pages (holding flush_order_mutex), another thread could be waiting to acquire the flush_order_mutex (even if it wanted to add pages to other flush list). In such case the waiting thread was holding log_sys_t::mutex (to maintain the total order), so any other thread that wanted to write to the log buffer had to wait… With the removal of these mutexes there is no guarantee on the order of the flush list. 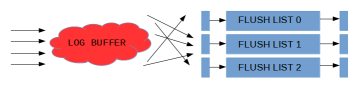
Second problem is that we cannot write the full log buffer to disk because there could be holes in the LSN sequence, because writes to the log buffer are not finished in any particular order.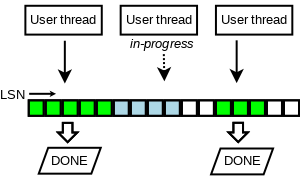
The solution for the second problem is to track which writes were finished, and for that we invented a new lock-free data structure.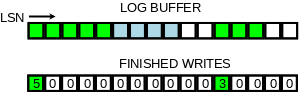
The new data structure has a fixed size array of slots. The slots are updated in atomic way and reused in a circular fashion. A single thread is used to traverse and clear them, making a pause at a hole (empty slot). This thread updates the maximum reachable LSN (M).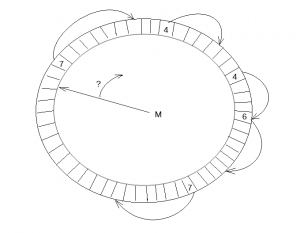 Two instances of this data structure are used: the recent_written and the recent_closed. The recent_written instance is used for tracking the finished writes to the log buffer. It can provide maximum LSN, such that all writes to the log buffer, for smaller LSN values, were finished. Potential crash recovery would need to end at such LSN, so it is a maximum LSN up to which we consider a next write. The slots are traversed by the same thread that writes the log buffer to disk afterwards. The proper memory ordering for reads and writes to the log buffer is guaranteed by the barriers set when reading/writing the slots.
Two instances of this data structure are used: the recent_written and the recent_closed. The recent_written instance is used for tracking the finished writes to the log buffer. It can provide maximum LSN, such that all writes to the log buffer, for smaller LSN values, were finished. Potential crash recovery would need to end at such LSN, so it is a maximum LSN up to which we consider a next write. The slots are traversed by the same thread that writes the log buffer to disk afterwards. The proper memory ordering for reads and writes to the log buffer is guaranteed by the barriers set when reading/writing the slots.
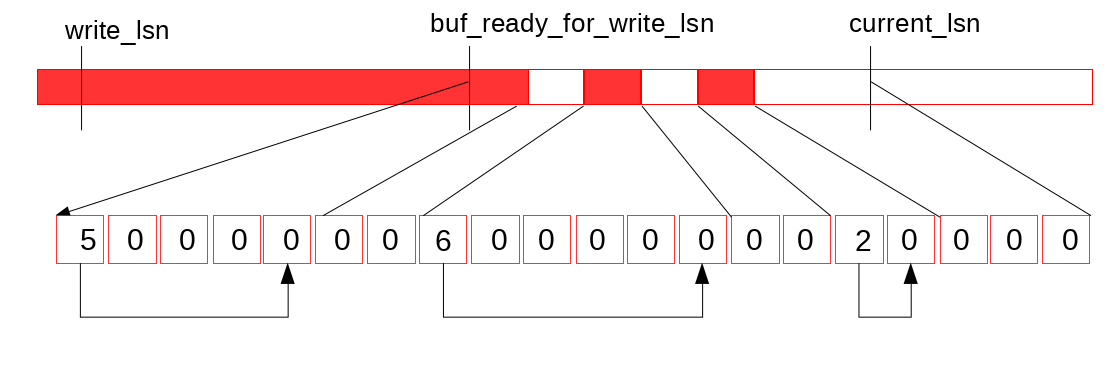
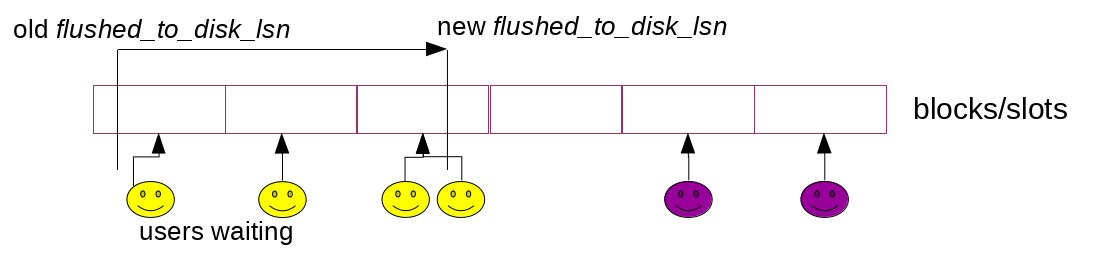
Let’s look at the picture above. Suppose that we finished one more write to the log buffer: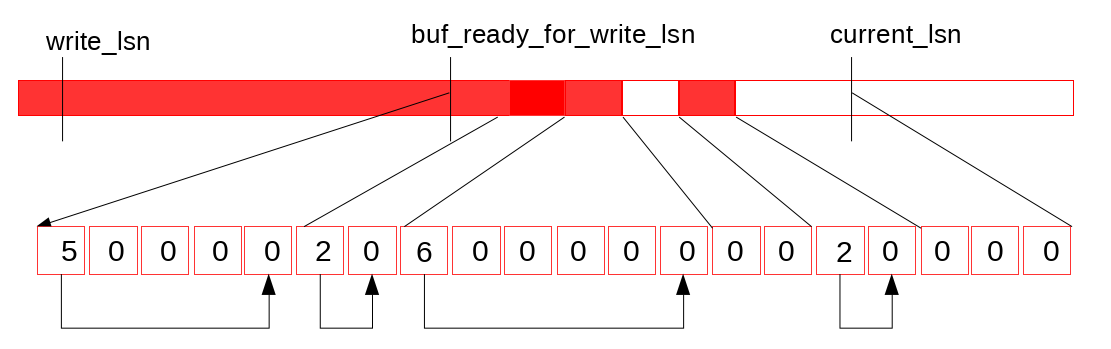
Now, the dedicated thread (log_writer) comes in, traverses the slots: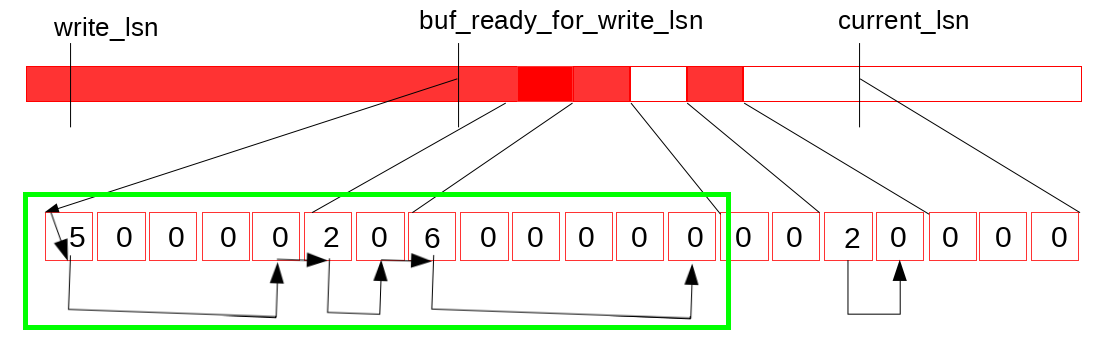
and updates the maximum LSN reachable without the holes – buf_ready_for_write_lsn: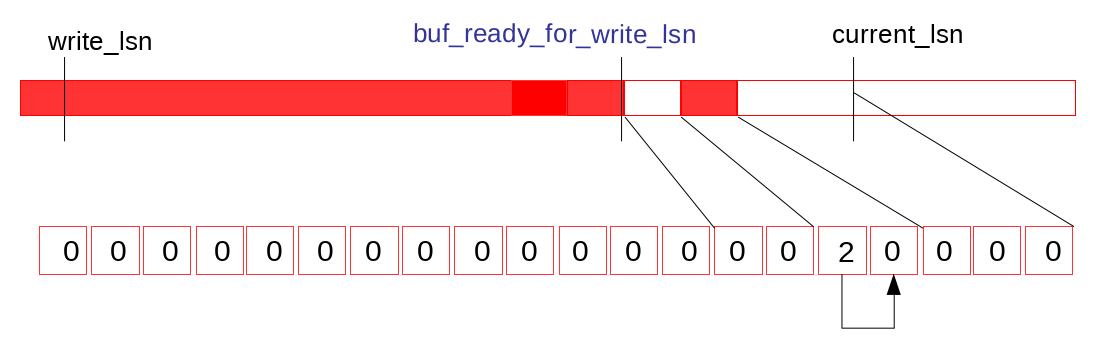
The recent_closed instance of the new data structure is used to address problems related to the missing log_sys_t::flush_order_mutex. To understand the flush list order problem and the lock free solution there is a little more detail required to explain.
Individual flush lists are protected by their internal mutexes. But we no longer preserve the guarantee that we add dirty pages to flush lists in the order of increasing LSN values. However, the two constraints that must be satisfied are:
- Checkpoint – We must not write fuzzy checkpoint at LSN = L2, if there is a dirty page for LSN = L1, where L1 < L2. That’s because recovery starts at such checkpoint_lsn.
- Flushing – Flushing by flush list should always be from the oldest page in the flush list. This way we prefer to flush pages that were modified long ago, and also help to advance the checkpoint_lsn.
In the recent_closed instance we track the concurrent executions of adding dirty pages to the flush lists, and track the maximum LSN (called M), such that all executions, for smaller LSN values have completed. Before a thread adds its dirty pages to the flush lists, it waits until M is not that far away. Then it adds the pages and then reports the finished operation to the recent_closed.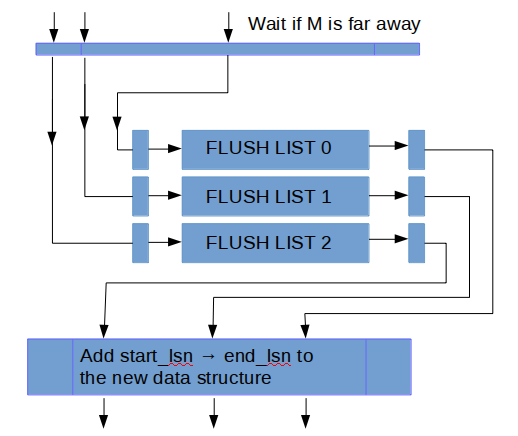
Let’s take an example. Suppose that some mtr, during its commit, copied all its log records to the log buffer for LSN range between start_lsn and end_lsn. It reported the finished write to the recent_written (the log records might be written to disk since now). Then the mtr must wait until it holds: start_lsn – M < L, where L is a constant that limits how much the order in flush lists might be distorted. After the condition holds, the mtr adds all the pages it made dirty to buffer pool specific flush lists. Now, let’s look at one of flush lists. Suppose that last_lsn is the LSN of the last page in the flush list (the earliest added there). In the old design it was the oldest modified page there, so it was guaranteed that all pages in the flush list had oldest_modification >= last_lsn. In the new design it is only guaranteed that all the pages in the flush list have oldest_modification >= last_lsn – L. The condition holds because we always wait if M is too far away before inserting pages.
Proof. Let’s suppose we had two pages: P1 with LSN = L1, and P2 with LSN = L2, and P1 was added to flush list first, but L2 < L1 – L. Before P1 was inserted we ensured that L1 – M < L. We had M <= L2 then, because P2 wasn’t inserted yet, so we couldn’t advance M over L2. Hence L > L1 – M >= L1 – L2, so L2 > L1 – L. Contradiction – we assumed that L2 < L1 – L.
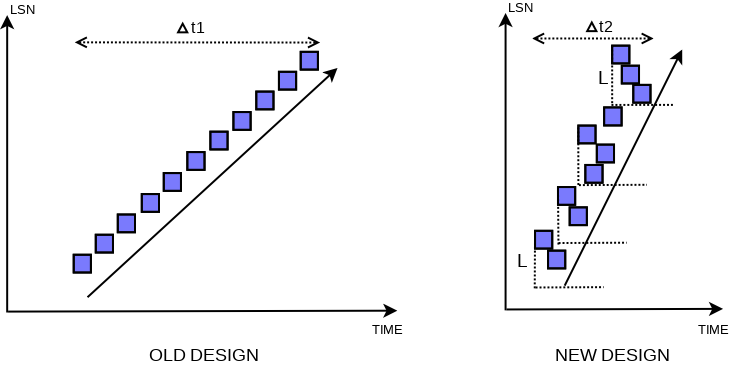
Therefore we relax the previous total order constraint, but at the same time, we provide good enough properties for the new order. The order in the flush list is distorted only locally and the missing dirty pages for smaller LSN values are possible only within the recent period of size L. That’s good enough for constraint #2, and it also allows to pick last_lsn – L as a candidate for checkpoint LSN, satisfying constraint #1.

This impacts the way recovery has to be done. Recovery logic could start from LSN which points to the middle of some mtr, in which case it needs to find the first mtr that starts afterwards and from there it can proceed with parsing. Now, let’s go back to our example. When all pages are added to the flush lists, a finished operation between start_lsn and end_lsn is reported to the recent_closed. Since then, the log_closer thread can traverse the finished addition, going from start_lsn to end_lsn, and update the maximum LSN up to which all additions are finished (setting M to end_lsn).

Thanks to lock-free log buffer and relaxed order in flush lists, synchronization between commits of concurrent mini transactions is negligible!
So far we described writing the page changes to the redo log buffer and adding the dirty pages to the buffer pool specific flush list. Let’s examine what happens when we need the log buffer written to disk.
We have introduced dedicated threads for particular tasks related to the redo log writes. User threads no longer do writes to the redo files themselves. They simply wait when they need redo flushed to disk and it is not flushed yet.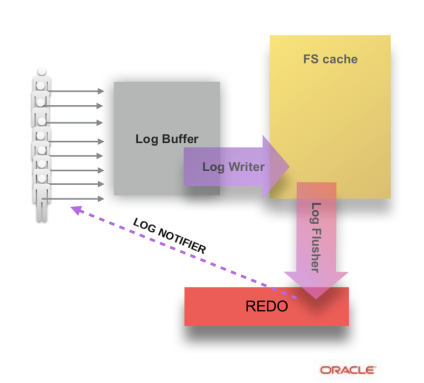
The log_writer thread keeps writing the log buffer to the OS page cache, preferring to write only full blocks to avoid the need to overwrite an incomplete block later. As soon as data is in the log buffer it may become written. In the old design the write was started when the requirement for written data occurred, in which case the whole log buffer was written. In the new design writes are driven by the dedicated thread. They may start earlier and the amount of data per write could be driven by a better strategy (e.g. skipping an incomplete yet block). The log_writer thread is also responsible for updates of the write_lsn (after write is finished).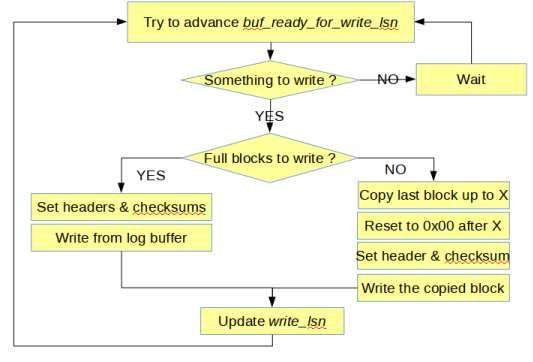
There is a log_flusher thread, which is responsible for reading write_lsn, invoking fsync() calls and updating flushed_to_disk_lsn. This way the writes to OS cache and the fsync() calls, are driven by two different threads in parallel at their own speeds, and the only synchronization between them happens inside internals of OS / FS (except the atomic reads and writes of write_lsn).
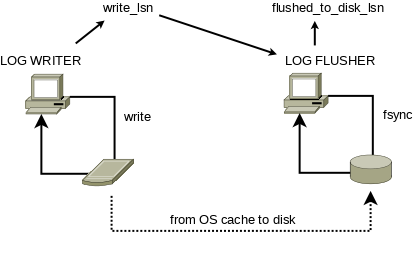 When a transaction commits, corresponding thread executes last mtr and then it needs to wait for the redo log flushed up to end_lsn of the mtr. In the old design, the user thread either started the fsync() itself or waited on the global IO completion event for the pending fsync() started earlier by other user thread (and then retried if needed).
When a transaction commits, corresponding thread executes last mtr and then it needs to wait for the redo log flushed up to end_lsn of the mtr. In the old design, the user thread either started the fsync() itself or waited on the global IO completion event for the pending fsync() started earlier by other user thread (and then retried if needed).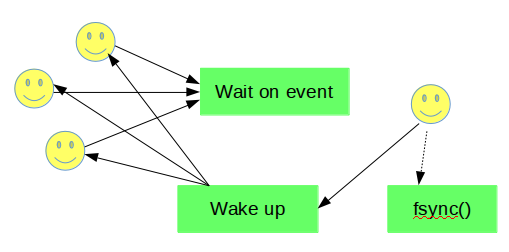 In the new design, it simply waits unless flushed_to_disk_lsn is already big enough, because it is always log_flusher thread which executes fsync(). The events used for waiting are sharded to improve the scalability. Consecutive redo blocks are assigned to consecutive shards in a circular manner. A thread waiting for flushed_to_disk_lsn >= X, selects a shard to which the X belongs. This decreases the synchronization required when attempting a wait. But what is even more important, thanks to such split, we can wake up only these threads that will be happy with the advanced flushed_to_disk_lsn (except some of those waiting in the last block).
In the new design, it simply waits unless flushed_to_disk_lsn is already big enough, because it is always log_flusher thread which executes fsync(). The events used for waiting are sharded to improve the scalability. Consecutive redo blocks are assigned to consecutive shards in a circular manner. A thread waiting for flushed_to_disk_lsn >= X, selects a shard to which the X belongs. This decreases the synchronization required when attempting a wait. But what is even more important, thanks to such split, we can wake up only these threads that will be happy with the advanced flushed_to_disk_lsn (except some of those waiting in the last block).
When flushed_to_disk_lsn is advanced, the log_flush_notifier thread wakes up threads waiting on intermediate values of LSN. Note that when log_flush_notifier is busy with the notifications, next fsync() call could be started within the log_flusher thread!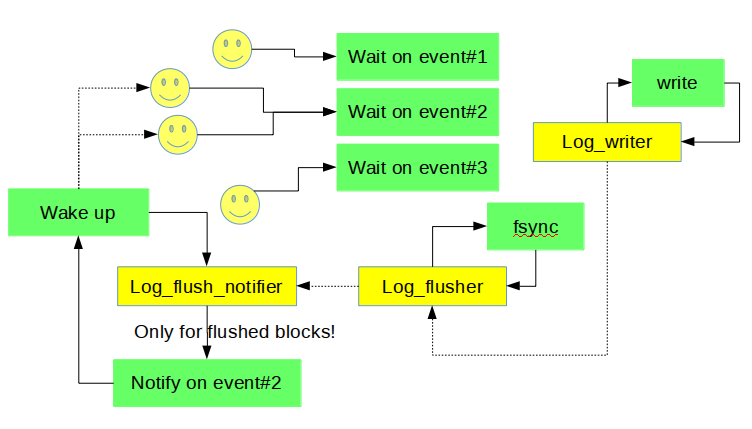
The same approach is used when innodb_flush_log_at_trx_commit =2, in which case users don’t care about fsyncs() that much and wait only for finished writes to OS cache (they are notified by the log_write_notifier thread in such case, which synchronizes with the log_writer thread on the write_lsn).
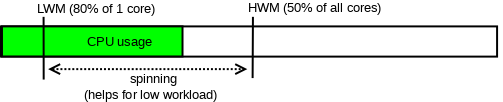
Because waiting on an event and being woken up increases latency, there is an optional spin-loop which might be used in front of that. It’s by default being used unless we don’t have too much free CPU resources on the server. You can control that via new dynamic system variables: innodb_log_spin_cpu_abs_lwm, and innodb_log_spin_cpu_pct_hwm.
As we mentioned at the very beginning, redo log can be seen as producer/consumer queue. InnoDB relies on fuzzy checkpoints from which potential recovery would need to start. By flushing dirty pages, InnoDB allows to move the checkpoint LSN forward. This allows us to reclaim free space in the redo log (blocks before the checkpoint LSN are basically considered free) and also makes a potential recovery faster (shorter queue).
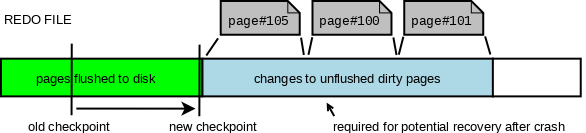
In the old design user threads were competing with each other when selecting the one that will write the next checkpoint. In the new design there is a dedicated log_checkpointer thread that monitors what are the oldest pages in flush lists and decides to write the next checkpoint (according to multiple criteria). That’s why no longer the master thread has to take care of periodical checkpoints. With the new lock free design we have also decreased the default period from 7s to 1s. This is because we can handle transactions much faster since the 7s were set (we write more data/s so faster potential recovery was the motivation for this change).
The new WAL design provides higher concurrency when updating data and a very small (read negligible) synchronization overhead between user threads!
Let’s have a look at simple comparison made between version just before the new redo log, and just after. It’s a sysbench oltp update_nokey test for 8 tables, each with 10M rows, innodb_flush_log_at_trx_commit = 1.
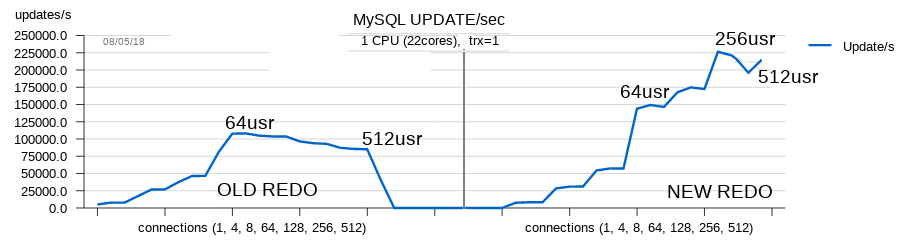
For details about different tests please read: http://dimitrik.free.fr/blog/archives/2018/05/mysql-performance-80-and-sysbench-oltp_rw-updatenokey.html
Thank you for using MySQL !