Now that MySQL 5.7 has become GA it’s a good time to highlight how much performance has improved in replication since the 5.6 era. This blog post will focus on the performance of the multi-threaded slave applier (MTS), and about it’s scalability in particular.
For those in a hurry, here is a summary of what follows:
- The multi-threaded applier can reach a speedup of over 10x, even on a fast storage system;
- 4 MTS threads already provide more than 3.5 times the throughput of single-threaded replication (STS).
- The ROW replication format is significantly faster than STATEMENT (even more if minimal images are used), but MTS helps to level the performance when different formats and durability settings are used.
1. About the multi-threaded slave applier
One of the big improvements of MTS in MySQL 5.7 is that it can now be used for any workload, including intra-schema, unlike 5.6 where it could only be applied with one thread per schema. There are two main aspects that influence the gain that can be achieved by the MTS applier:
- the number of transactions that are executed in parallel (dependent on the ability of the algorithms to explore parallelism);
- how more efficient are the grouped transactions when committing to disk (dependent on the underlying storage system and the durability settings select by the user).
Prior to 5.7.3 the parallelism window was bound to the size of a single binary log group-commit, but now it expands beyond that limit and, to achieve good slave performance, there is less need for any artificial delays that might impair the master performance, as will also be shown below. But the number of client threads is still a particularly important parameter, with higher number of threads on the master allowing a greater degree of parallelism on the slave.
The following sections will present some measurements focused mostly on the applier effectiveness, showing the execution time, the speedup and the thread-count efficiency that can be expected in such systems and hopefully help tune MTS initially.
2. Benchmarking MTS
The performance of the MTS is dependent on the type of workload that must be executed on the slave, and different workloads can have dissimilar parallelism potential, so users should check their own workloads for better evaluation.
For the tests we selected two workloads generated by the Sysbench 0.5 benchmark: the RW and the Update Index profiles. The database was configured with 10M rows in 8 tables, 256 client threads on the master and GTIDs active, while the tests were repeated at least 5 times in non-adjacent moments in each configuration tested.
The STS and the MTS with 2, 4, 8, 16 and 32 threads were tested with several options:
- Statement-based/Row-based replication/Row-based replication with minimal images replication format;
- with and without binary logs on the slave to measure the influence of having the IO and GTIDs on tables;
- with durability (sync-binlog=1, innodb_flush_log_at_trx_commit=1) and without (sync-binlog=0, innodb_flush_log_at_trx_commit=2) and
- with a binary-log group-commit delay of 1ms and without delay (binlog_group_commit_sync_delay=1000 or 0) to show the influence of the group-commit delay on parallelism.
The benchmarks executed in what we believe is the most widely used machine architecture in high-performance replication scenarios: a modern two multi-core processor (Intel Xeon E5-2699v3) NUMA machine with a fast random-access storage system (so, many cores in two physical sockets and, if you didn’t guess it, spinning disks are out, although with this we lose the ability to claim any speedup we want by finding a slow enough storage configuration to show it ;-).
2.1 Throughput
The charts that follow show the throughput of the STS and MTS to apply the workloads (3M transactions in RW and Update Index) in several configurations, including using statement-based/row-based replication, using durability settings on disk or not and using binary logs on the slave.
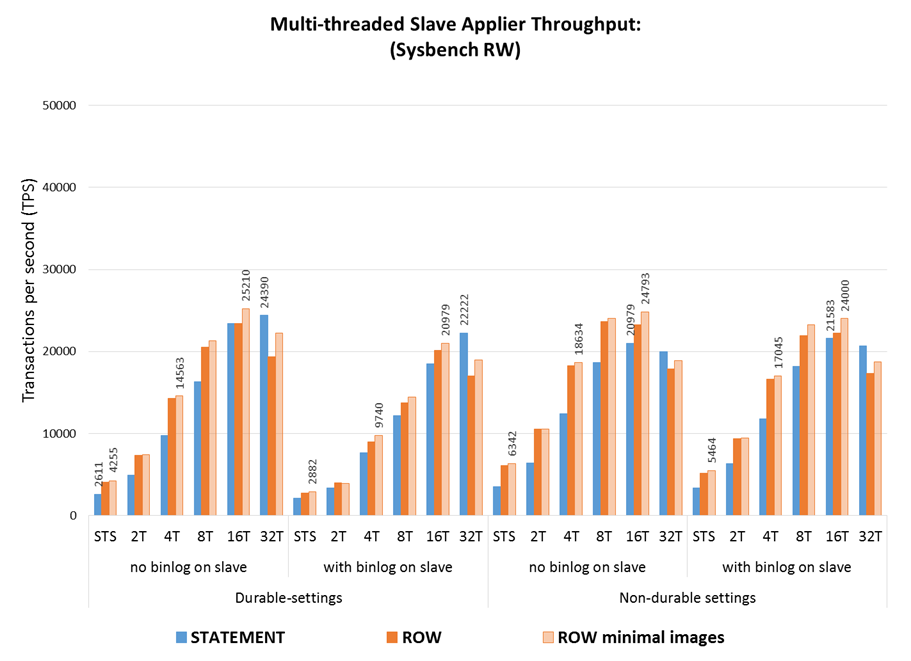
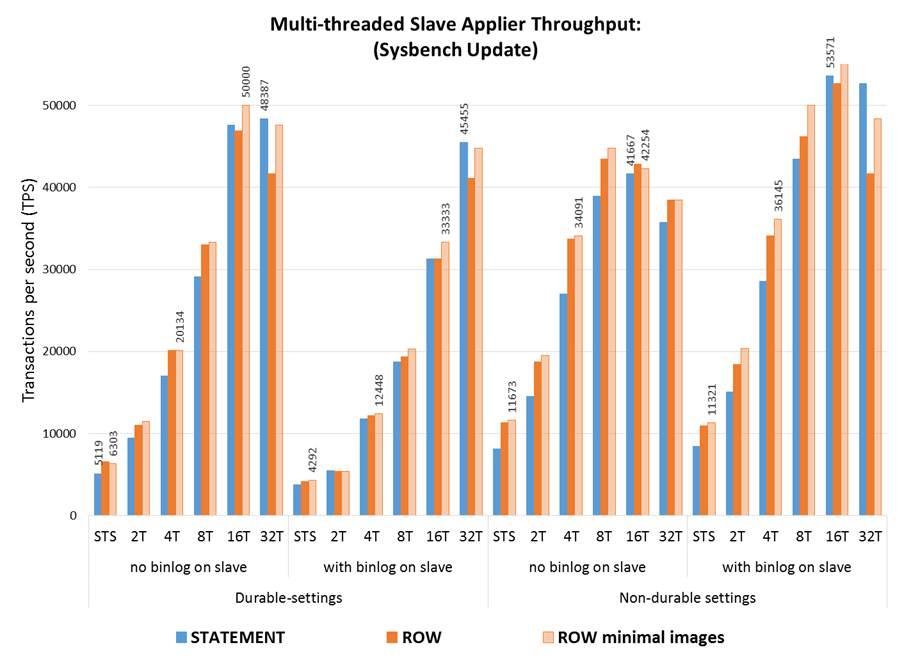
Some observations:
- The order of factors affecting the execution time is using durability settings, followed by using the binary log on the slave (mainly when durability is used), and finally the replication format;
- As the number of threads grows past 8 the effect of each of there factors is very much reduced, which means that MTS is able to hide the added latency that results from having to write the binary log and sync the binary log and database to disk;
- The ROW replication format provides higher throughput then STATEMENT, with around 40% (60% with no durability) lower execution time on STS, and keeps being faster until the highest number of threads where the gaps is reduced.
- ROW-based replication with minimal images is another 5% to 7% faster then ROW with full images, which means that the extra effort to apply the minimal images is compensated by the reduction in binary log information that must be processed.
2.2 Speedup
Another way of measuring the effectiveness of MTS applier is using the speedup, which is calculated by dividing the time it takes to apply a workload using MTS by the time it takes to apply the same workload using the single-threaded slave (STS) applier. The speedup can be seen as representing how many times faster is MTS at applying the same workload as STS .
In an optimally efficient parallel applier the speedup would be equal to the number of cores used by the applier threads, but in a database system that linear scalability is very hard to achieve and so it becomes important to know how much of that linear scalability is attainable.
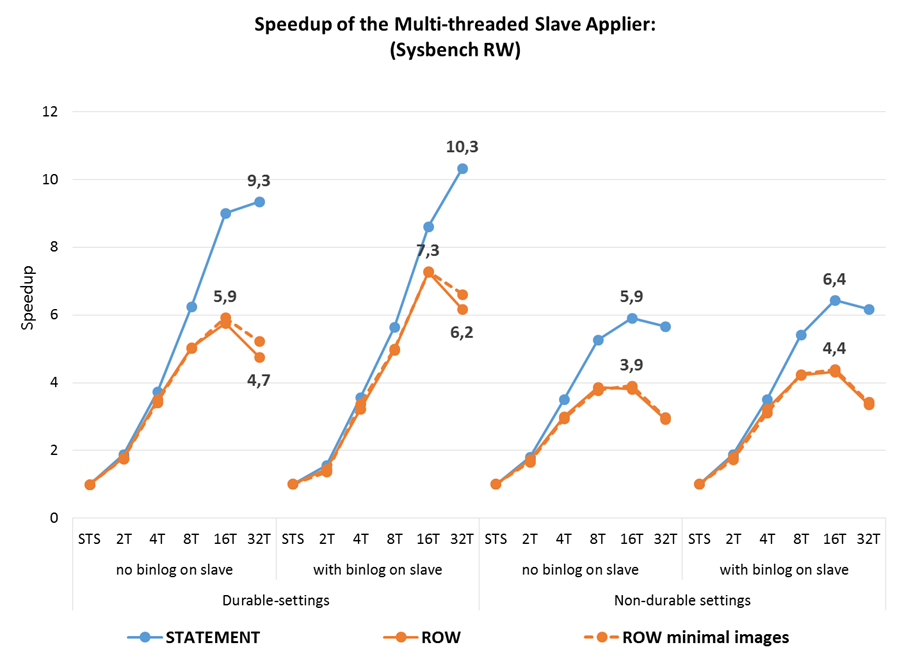
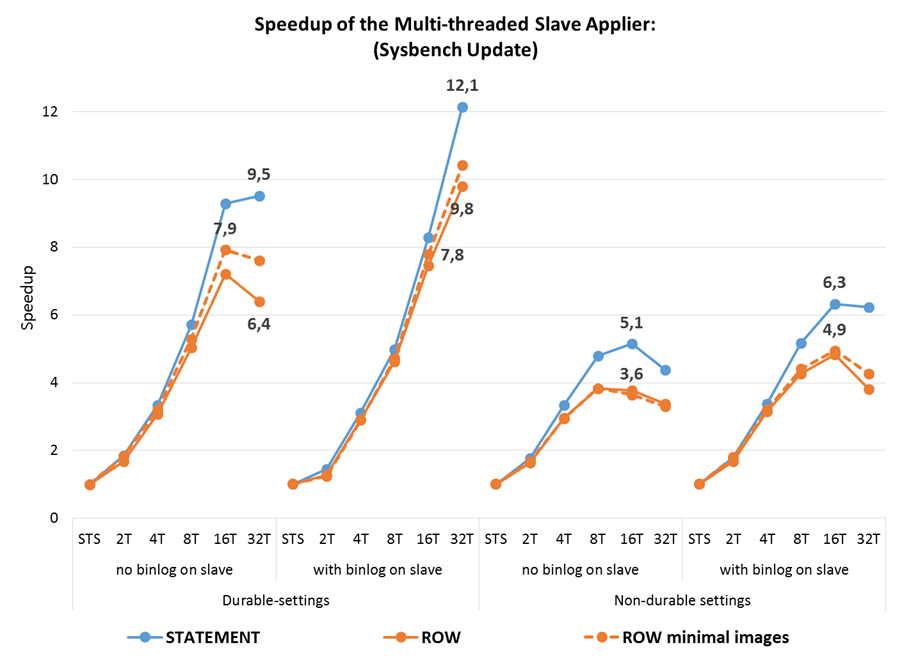
Some observations:
- The speedup is larger when using durable settings, where it reaches 10X for RW and 12X for Update Index, as we benefit from both the parallelism in the applier and in the commit to disk;
- This is achieved with durability on an fast SSD, but even on systems with no durability the speed-up can still get above 6X;
- The maximum for STATEMENT-based replication is higher, at a higher thread-count, than for ROW-based row-based replication (where the maximum is reduced to above 9X);
- On non-durable settings there is higher speedup when the binlog is used, a consequence of having to write the executed GTID set to tables when the binlog is not used, which right now is still a bit costly;
- STATEMENT-based replication has higher speedups than ROW-based replication, with or without minimal-images, both because the STS time is higher and because the STATEMENT-applier has larger units to process so it scales better; at the higher thread counts the benefit is lower (it stays at 8% with no durability).
2.3 MTS-thread efficiency
The inverse of the speedup (divided by the number of cores) is the efficiency, which represents how well the threads use the underlying resources. If cores were dedicated to threads that would could be converted to how efficiently the processors were being used, but as threads are scheduled out when they don’t have work that cannot be used directly. Nevertheless, this metric may still be useful because, in many replication scenarios, the applier competes for resources with the users workloads and having less threads synchronizing and being scheduled around is more efficient, so we get the “bang for the thread buck”.
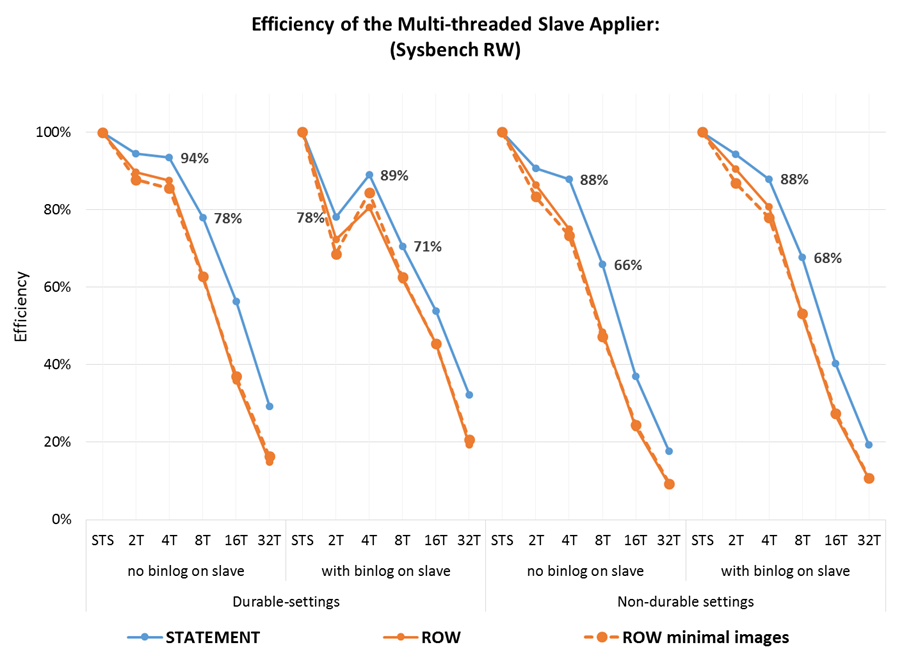
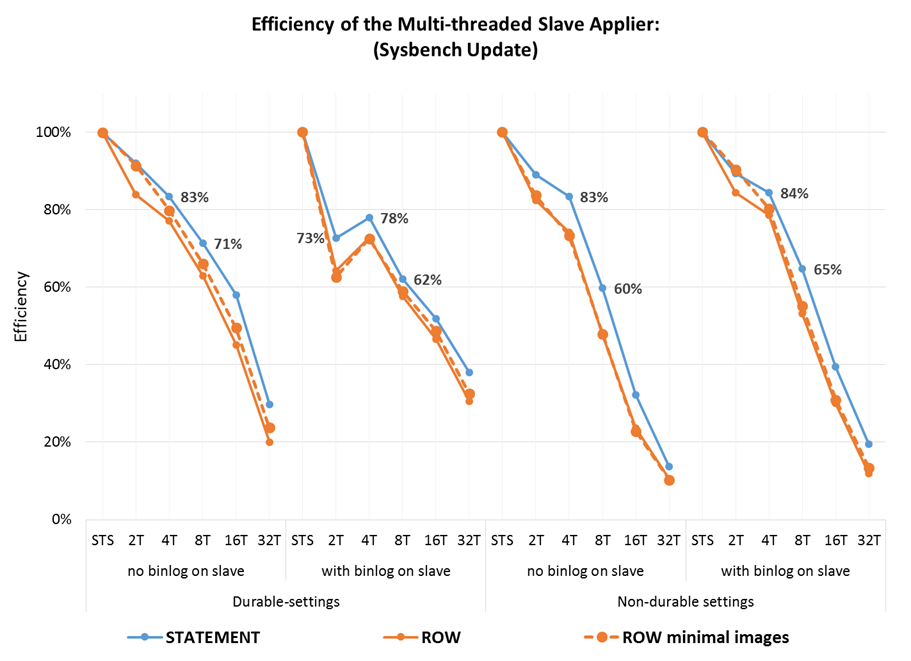
Some observations:
- The average efficiency per thread, with 2 and 4 threads, is around 85%, dropping to 60% for 8 threads;
- However, that varies significantly per combination, with durable settings dropping faster initially and non-durable setting dropping slower initially but faster later.
2.4 Effect of the binary-log group-commit delay
As mentioned above, the parallelism on the workload is important to give MTS the opportunity to execute in parallel in the slave. One way to artificially increase the parallelism in the source is to artificiality delay the group commit on the master so that more transactions are packed together and seen as independent.
Before the improvement in 5.7.3 the logical clock scheduler in MTS would only consider parallel transactions that were grouped in the same commit, which on fast commit systems would leave little opportunity to execute in parallel in the slave. That has improved significantly, and now the MTS can execute more transactions in parallel without depending on the group commit size. Nevertheless, there is still more parallelism potential if the group commits are larger, so the next charts compare the execution with and without delays on the master to see how much is gained by them.
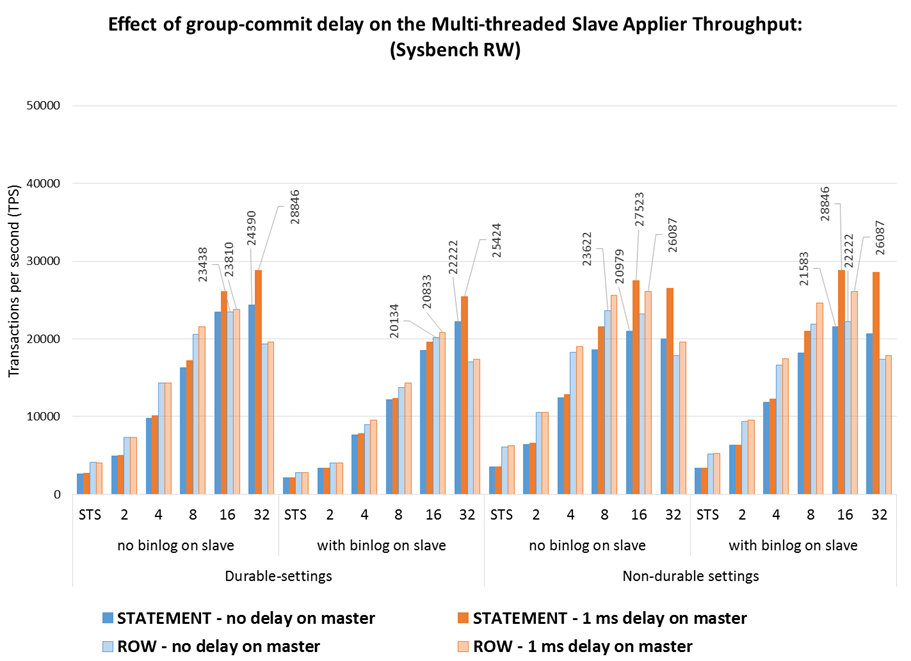
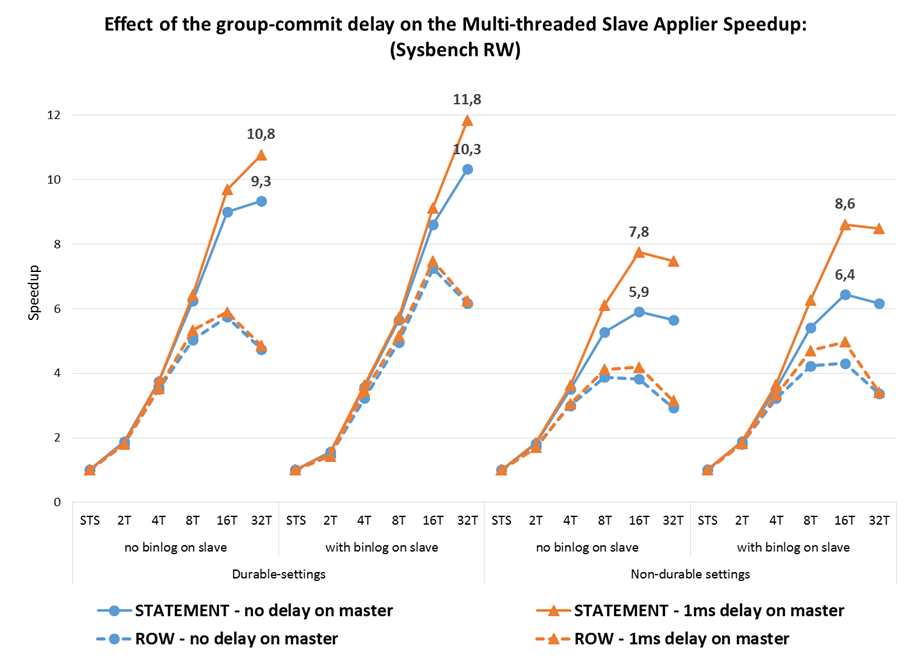
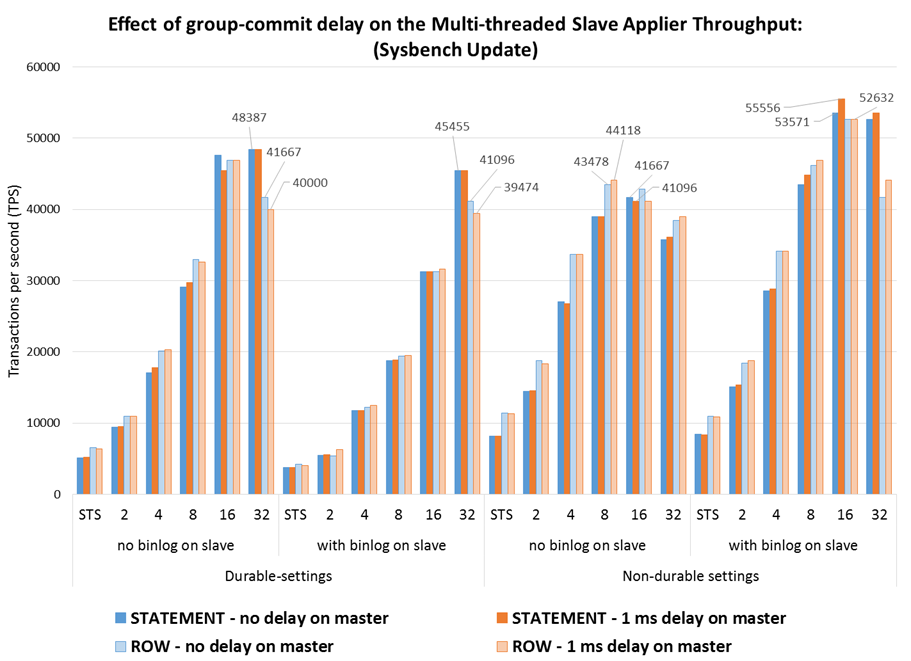
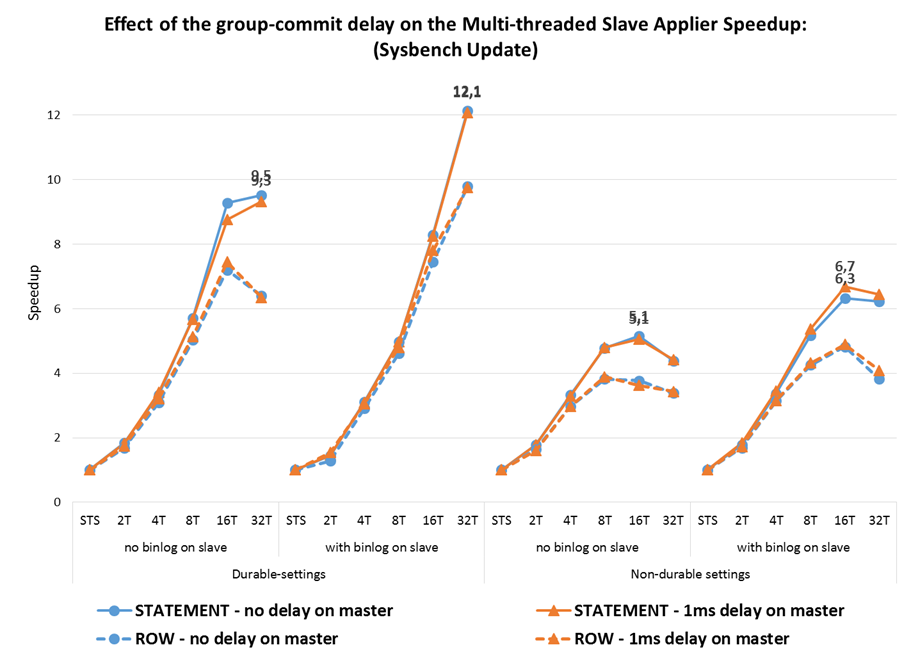
Some observations:
- In the tested setup, the delay on group commit benefits mostly the Statement-based replication, where the speedup grows from 10X to around 12X with durability and from 6X to 8X without durability, while for ROW-based replication the gain is very small or even non-existent.
- While this means that with a high number of clients there is little need to do any delays on the master, when there is little parallelism on the master that may be useful to improve the MTS throughput.
3. Recommendations
There is no good substitute for careful testing with your own system and workload, as the charts above are specific to this system and to the workloads tested.
However, in case you have a setup somewhat similar to the one presented, we dare to make a few suggestions:
- Use ROW-based replication (preferably with minimal images) when possible: even with a lower speedup, the execution time is usually much smaller then STATEMENT-based replication;
- Too many MTS threads will increase the synchronization effort between threads and may bring reduced benefit, use only those needed: it will depend on the workload, but something like 4 to 8 threads for ROW-based replication, a bit more for STATEMENT-based replication and even a bit more if durability is a requirement;
- If your workload has many clients there is little need to throttle the master the increase parallelism on the binary log commit.
Enjoy!