Astute readers will note that InnoDB already had compression since the MySQL 5.1 plugin. We are using the terminology of ‘Page Compression’ to describe the new offering that will ship with MySQL 5.7, and ‘InnoDB Compression’ for the earlier offering.
First a brief history and explanation of the current motivation.
InnoDB Compression
Compressed tables were introduced in 2008 as part of the InnoDB plugin for MySQL 5.1. By adding compression, InnoDB is able to more efficiently make use of modern hardware such as fast SSD devices. Facebook was an early adopter of this technology. They did extensive analysis and made lots of improvements, most of which were later pushed to the upstream MySQL code as well.
The code changes required to get the old InnoDB compression to work properly were extensive and complex. Its tentacles are everywhere—I think that just about every module inside InnoDB has had modifications done to it in order to make it work properly when compression is in use. This complexity has its challenges, both in terms of maintainability and when it comes to improving the feature. We have been debating internally about what we should do about this over the long run. As much as we would like to redesign and rewrite the entire old compression code, it is impractical. Therefore we are only fixing issues in the old compression code reported by customers. We think there are better ways to solve the underlying performance and compression problems around B-Trees. For example by adding support for other types of indexes e.g. LSM tree and/or BW-Tree or some variation of the two. We also want to change our page and row formats so that we have the flexibility to add new indexing algorithms as required by the changing landscape and at the same time maintaining full backward compatibility. As we continue to develop and improve InnoDB, we also think that the write amplification and compression efficacy problems need to be fixed more substantially rather than tinkering around the edges of our old compression codebase.
Introducing InnoDB Page Compression
When FusionIO (now part of SanDisk) floated the idea around transparent page compression, the appeal was in its simplicity—the changes to the code base were very localised and more importantly it complements the existing InnoDB compression as both transparent page compression and the old compression can coexist in the same server instance. Users can then choose the compression scheme that makes more sense for their use case, even on a table-by-table basis.
From a high level, transparent page compression is a simple page transformation:
Write : Page -> Transform -> Write transformed page to disk -> Punch hole
Read : Page from disk -> Transform -> Original Page
When we put these abstractions in place, it was immediately obvious that we could apply any type of transformation to the page including encryption/decryption and other things as we move forward. It is then trivial to add support for a new compression algorithm, among other things. Also, MySQL 5.7 already had the multiple dedicated dirty page flushing threads feature. This existing 5.7 feature was a natural fit for offloading the “transformation” to a dedicated background thread before writing the page to disk thus parallelizing the compression and the “hole punch” after the write to disk. By contrast, with the old InnoDB compression the compress/decompress/recompress operations are done in the query threads (mostly), and it would take a mini-series of blog posts to explain how it works, even when assuming that you’re already very familiar with the InnoDB internals.
To use the new Transparent Page Compression feature the operating system and file system must support sparse files and hole punching.
Linux
Several popular Linux file systems already support the hole punching feature. For example: XFS since Linux 2.6.38, ext4 since Linux3.0, tmpfs (/dev/shm) since Linux 3.5, and Btrfs since Linux 3.7.
Windows
While this feature is supported on Windows, it may not provide much practical value “out of the box”. The issue is in the way NTFS clustering is designed.
On Windows the block size is not used as the allocation unit for sparse files. The underlying infrastructure for sparse files on NTFS is based on NTFS compression. The hole punch is done on a “compression unit” and this compression unit is derived from the cluster size (see the table below). This means that by default you cannot punch a hole if the cluster size >= 8K. Here’s a breakdown for smaller cluster sizes:
| Cluster Size | Compression Unit |
|---|---|
| 512 Bytes | 8K Bytes |
| 1K Bytes | 16K Bytes |
| 2K Bytes | 32K Bytes |
| 4K Bytes | 64K Bytes |
The default NTFS cluster size is 4K bytes, which means that the compression unit size is 64K bytes. Therefore, unless the user has created the file system with a smaller cluster size and used larger InnoDB page sizes, there is little practical benefit from transparent compression “out of the box”.
Using the Feature
In the current release we support two compression algorithms, ZLib and LZ4. We introduced a new table level attribute that is stored in the .frm file. The new attribute is:
COMPRESSION := ( "zlib" | "lz4" | "none")
If you create a new table and you want to enable transparent page compression on it you can use the following syntax:
CREATE TABLE T (C INT) COMPRESSION="lz4";
If later you want to disable the compression you can do that with:
ALTER TABLE T COMPRESSION="none";
Note that the above ALTER TABLE will only result in a meta-data change. This is because inside InnoDB COMPRESSION is a page level attribute. The Implication is that a tablespace can contain pages that could be a mix of any supported compression algorithm. If you want to force the conversion of every page then you need to force it by invoking:
OPTIMIZE TABLE T;
Tuning
Remember to set the innodb-page-cleaners to a suitable value, in my tests I’ve used a value of 32. Configuring for reads is not that straight forward. InnoDB can do both sync and async reads. Sync reads are done by the query threads. Async reads are done during read ahead, one downside with read ahead is that even if the page is not used it will be decompressed. Since the async read and decompress is done by the background IO read threads, it should not be too much of an issue in practice. Sync read threads will use the page otherwise they wouldn’t be doing a sync read in the first place. One current problem with converting a sync read to an async read is the InnoDB IO completion logic. If If there are too many async read requests, it can cause a lot of contention on the buffer pool and page latches.
Monitoring
With hole punching the file size shown by ls -l displays the logical file size and not the actual allocated size on the block device. This is a generic issue with sparse files. Users can now query the INNODB_SYS_TABLESPACES information schema table in order to get both the logical and the actual allocated size.
The following additional columns have been added to that Information Schema view: FS_BLOCK_SIZE, FILE_SIZE, ALLOCATED_SIZE, and COMPRESSION.
- FS_BLOCK_SIZE is the file system block size
- FILE_SIZE is the file logical size, the one that you see with
ls -l - ALLOCATED_SIZE is the actual allocated size on on the block device where the filesystem resides
- COMPRESSION is the current compression algorithm setting, if any
Note: As mentioned earlier, the COMPRESSION value is the current tablespace setting and it doesn’t guarantee that all pages currently in the tablespace have that format.
Here are some examples:
|
1 2 3 4 5 6 7 |
mysql> select * from information_schema.INNODB_SYS_TABLESPACES WHERE name like 'linkdb%'; +-------+------------------------+------+-------------+----------------------+-----------+---------------+------------+---------------+-------------+----------------+-------------+ | SPACE | NAME | FLAG | FILE_FORMAT | ROW_FORMAT | PAGE_SIZE | ZIP_PAGE_SIZE | SPACE_TYPE | FS_BLOCK_SIZE | FILE_SIZE | ALLOCATED_SIZE | COMPRESSION | +-------+------------------------+------+-------------+----------------------+-----------+---------------+------------+---------------+-------------+----------------+-------------+ | 23 | linkdb/linktable#P#p0 | 0 | Antelope | Compact or Redundant | 16384 | 0 | Single | 512 | 4861198336 | 2376154112 | LZ4 | ... |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
mysql> select name, ((file_size-allocated_size)*100)/file_size as compressed_pct from information_schema.INNODB_SYS_TABLESPACES WHERE name like 'linkdb%'; +------------------------+----------------+ | name | compressed_pct | +------------------------+----------------+ | linkdb/linktable#P#p0 | 51.1323 | | linkdb/linktable#P#p1 | 51.1794 | | linkdb/linktable#P#p2 | 51.5254 | | linkdb/linktable#P#p3 | 50.9341 | | linkdb/linktable#P#p4 | 51.6542 | | linkdb/linktable#P#p5 | 51.2027 | | linkdb/linktable#P#p6 | 51.3837 | | linkdb/linktable#P#p7 | 51.6309 | | linkdb/linktable#P#p8 | 51.8193 | | linkdb/linktable#P#p9 | 50.6776 | | linkdb/linktable#P#p10 | 51.2959 | | linkdb/linktable#P#p11 | 51.7169 | | linkdb/linktable#P#p12 | 51.0571 | | linkdb/linktable#P#p13 | 51.4743 | | linkdb/linktable#P#p14 | 51.4895 | | linkdb/linktable#P#p15 | 51.2749 | | linkdb/counttable | 50.1664 | | linkdb/nodetable | 31.2724 | +------------------------+----------------+ 18 rows in set (0.00 sec) |
Limitations
Nothing is perfect. There are always potential issues and it is best to be aware of them up front.
Usage
Currently you cannot compress shared system tablespaces (for example the system tablepsace and the UNDO tablespaces) nor general tablespaces, and it will silently ignore pages that belong to spatial (R-Tree) indexes. The first two are more like artificial limitations from an InnoDB perspective. Inside InnoDB it doesn’t make any difference whether it is a shared tablespace or an UNDO log. It is a page level attribute. The problem is because we store the compression table attributes in a .frm file and the .frm file infrastructure doesn’t know about InnoDB tablespaces. The spatial index (R-Tree) limitation is because both features use the same 8 bytes within the header file. The first is a limitation due to MySQL legacy issues and difficult to fix. The latter is probably fixable by changing the format of the compressed page for R-Tree indexes, but we decided not to introduce two formats for the the same feature. Many of these limitations will go away with the new Data Dictionary and related work.
Space savings
The granularity of the block size on many file systems by default is 4K. This means that even if the data in the InnoDB data block compresses down from 16K to say 1K we cannot punch a hole and release the 15K of empty space on the block, but rather only 12K. By contract, for file systems that use a much smaller size of 512 bytes by default, this works extremely well (e.g. DirectFS/NVMFS). There is a trend on the hardware side to move from 512 byte sectors to larger sectors e.g. 4K, as larger sector sizes usually result in faster writes provided the writes are the same size as the sector size. FusionIO devices provide the ability to set this size during the formatting phase. Perhaps other vendors will follow and allow this flexibility too. Then one can decide on the size vs speed trade off during capacity planning.
Copying files from one system to another
If you copy files on a host that has hole punching support and the files are compressed using the transparent page compression feature, then on the destination host the files could “expand” and fill the holes. Special care must be taken when copying such files. (rsync generally has good support for copying sparse files, while scp does not.)
ALTER TABLE/OPTIMIZE TABLE
If you use the ALTER TABLE syntax to change the compression algorithm of a tablespace or you disable transparent page compression, this will only result in a meta-data change. The actual pages will be modified when they are next written. To force a change to all of the pages, you can use OPTIMIZE TABLE.
File system fragmentation
The file system can get fragmented due to hole punching releasing blocks back to the file system free list. This has two ramifications:
- Sequential scans can actually end up as random IO. This is particularly problematic with HDDs.
- It may increase the FS free list management overhead. In our (shorter) tests using XFS I haven’t seen any major problem, but one should do an IO intensive test over the course of several months to be sure.
Implementation Details
We repurposed 8 bytes in the InnoDB page header, which exists on every page in every tablespace file. The repurposed field is the “FLUSH_LSN” (see definition of the page header as a C struct below). This field, prior to the MySQL 5.7 R-Tree implementation being added, was only valid for the system tablespace’s (ID: 0) first page (ID: 0). For all other pages it was unused.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
typedef uint64_t lsn_t; struct Page _PACKED_ { struct Header _PACKED_ { uint32_t checksum; uint32_t offset; uint32_t prev; uint32_t next; lsn_t lsn; uint16_t page_type; /* Originally only valid for space 0 and page 0. In 5.7 it is now used by the R-Tree and the transparent page compression to store their relevant meta-data */ lsn_t flush_lsn; uint32_t space; }; /* PAGE_SIZE on of : 1K, 2K, 4K, 8K, 16K, 32K and 64K */ byte data[PAGE_SIZE - (sizeof(Header) + sizeof(Footer)]; struct Footer _PACKED_ { uint32_t checksum; /* Low order bits from Header::lsn */ uint32_t lsn_low; }; }; |
flush_lsn is interpreted as meta_t below. Before writing the page to disk we compress the page and set the various fields in the meta_t structure for later deserialization when we read the page from disk.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
/** Compressed page meta-data */ struct meta_t _PACKED_ { /** Version number */ uint8_t m_version; /** Algorithm type */ uint8_t m_algorithm; /** Original page type */ uint16_t m_original_type; /** Original page size, before compression */ uint16_t m_original_size; /** Size after compression */ uint16_t m_compressed_size; }; |
Readers will notice that the size type is a uint16_t. This limits the page size to 64K bytes. This is a generic limitation in the current InnoDB page layout, not a limitation introduced by this new feature. Issues like this are the reason why we want to rethink our long term objectives and fix them by doing more structural changes.
Performance
The first test uses FusionIO hardware along with their NVMFS file system. When I ran my first set of tests using the new compression last week, it was a little underwhelming to say the least. I hadn’t run any performance tests for over a year and a half, and a lot has changed since then. The numbers were not very good, the compression was roughly the same as the older compression and the Linkbench requests per second were quite similar to the old compression, just a little bit better, nothing compelling. I think it could be due to NUMA issues in the NVMFS driver as the specific hardware that I tested on is one of our newer machines with 4 sockets.
I did some profiling using Linux Perf but nothing stood out, the biggest CPU hog was Linkbench. I played around with the Java garbage collector settings, but it made no difference. Then I started looking for any latching overheads that may have been introduced in the final version. I noticed that the hole punching call was invoked under the protection of the AIO mutex. After moving the code out of that mutex, there was only a very small improvement. After a bit of head scratching, I tried to decompose the problem into smaller pieces. We don’t really do much in this feature, we compress the page, write the page to disk and then punch a hole to release the unused disk blocks. Next I disabled the hole punching stage and the requests per second went up 500%, this was encouraging. Were we making too many hole punching calls? It turns out we were. We only need to punch a hole if the compressed length is less than the previous length on disk. With this fix (which is not in the current 5.7.8 RC) the numbers were again looking much better.
One observation that I would like to make is that the compression/decompression doesn’t seem to be that expensive, about 15% overhead. The hole punching in NVMFS seems to have a bigger impact on the numbers, approximately 25% on NVMFS.
The host specs are:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
RAM: 1 TB Disk1: FusionIO ioMemory SX300-1600 + NVMFS Disk2: 2 x Intel SSDSA2BZ10 in a RAID configuration + EXT4 Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 80 On-line CPU(s) list: 0-79 Thread(s) per core: 2 Core(s) per socket: 10 Socket(s): 4 NUMA node(s): 4 Vendor ID: GenuineIntel CPU family: 6 Model: 47 Stepping: 2 CPU MHz: 2394.007 BogoMIPS: 4787.84 Virtualization: VT-x L1d cache: 32K L1i cache: 32K L2 cache: 256K L3 cache: 30720K NUMA node0 CPU(s): 0-9,40-49 NUMA node1 CPU(s): 10-19,50-59 NUMA node2 CPU(s): 20-29,60-69 NUMA node3 CPU(s): 30-39,70-79 |
Below are the important my.cnf settings from my tests. I won’t claim that this is a highly tuned configuration, it’s just what I used. As long as it is the same for all three tests, I don’t think it should matter much:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
loose_innodb_buffer_pool_size = 50G loose_innodb_buffer_pool_instances = 16 loose_innodb_log_file_size = 4G loose_innodb_log_buffer_size = 128M loose_innodb_flush_log_at_trx_commit = 2 loose_innodb_max_dirty_pages_pct = 50 loose_innodb_lru_scan_depth = 2500 loose_innodb_page_cleaners = 32 loose_innodb_checksums = 0 loose_innodb_flush_neighbors = 0 loose_innodb_read_io_threads = 8 innodb_write_io_threads = 8 loose_innodb_thread_concurrency = 0 loose_innodb_io_capacity = 80000 loose_innodb_io_capacity_max=100000 |
I then ran three tests:
- No compression with the default page size of 16K.
- Old compression with an 8K page size.
- New compression with default page size of 16K and
COMPRESSION="lz4".
The Linkbench commands used to load and test were:
|
1 2 3 |
linkbench -D dbid=linkdb -D maxid1=100000001 -c config/MyConfig.properties -l linkbench -D requesters=64 -Dmaxid1=100000001 -c config/MyConfig.properties -D requests=500000000 -D maxtime=3600 -r |
LinkBench Load Times
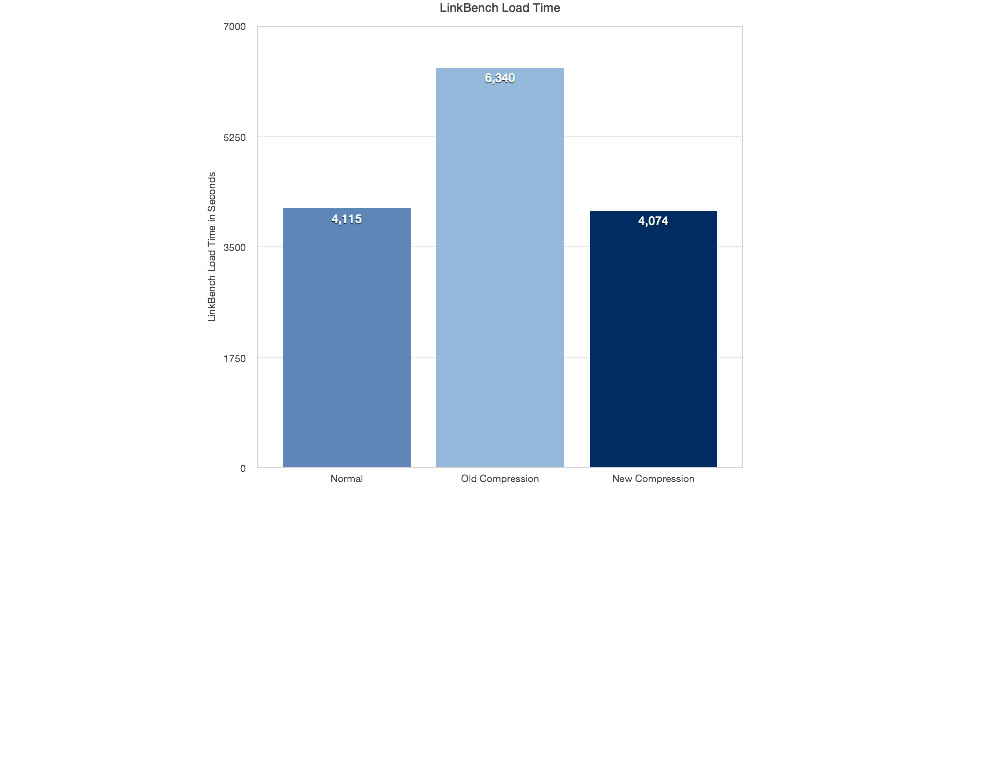
The loading times when using the new compression were quite similar to the loading times without any compression, while the old compression quite slow by comparison.
The first test was on NVMFS:
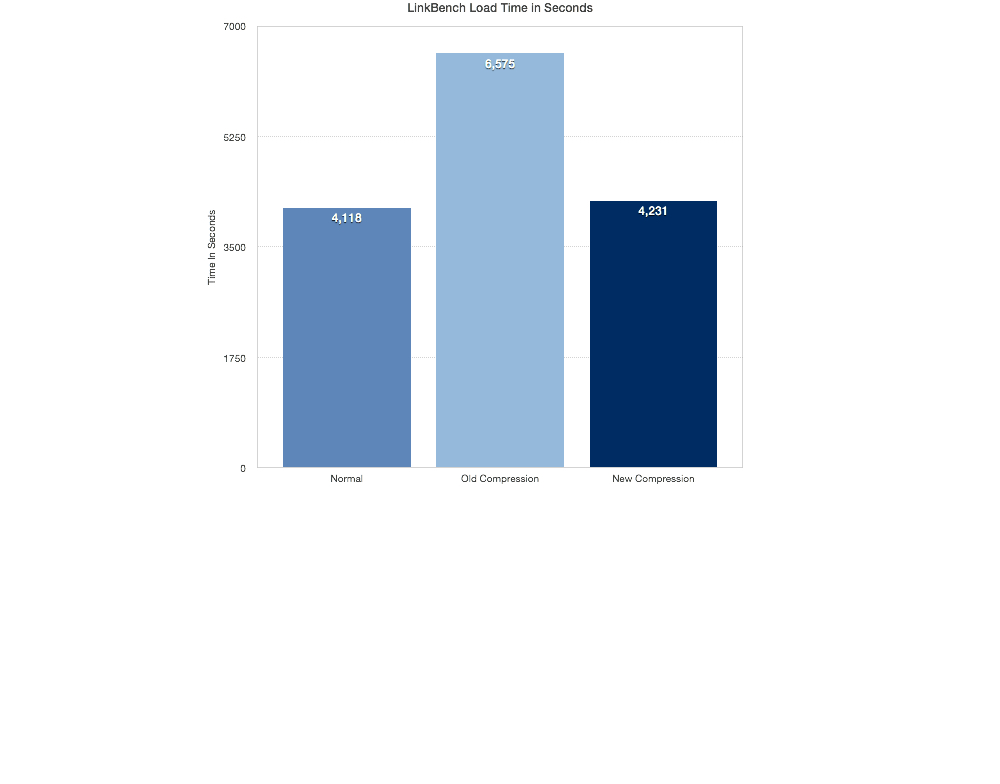
The next test was on a slower Intel SSD using EXT4:
LinkBench Request Times
The old compression gave the worst result again. It is 3x times slower than the new compression. I also think that since we haven’t even really begun to optimise the new compression code yet, we can squeeze some more juice out of it.
This is on NVMFS:
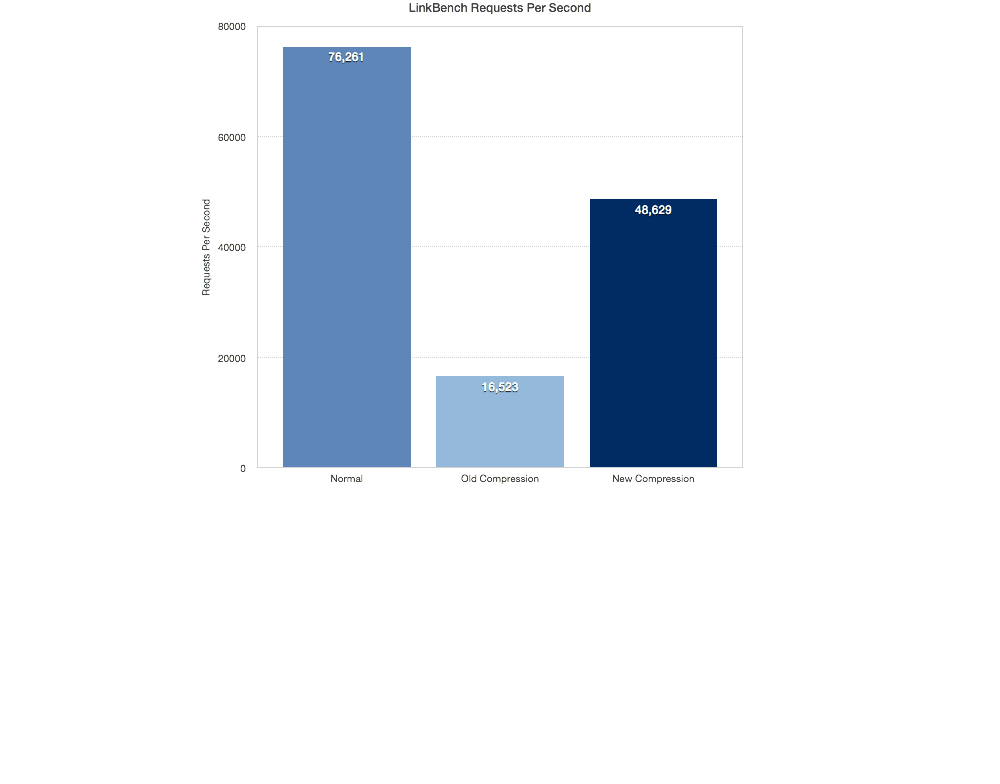
This is on a slower Intel SSD using EXT4:
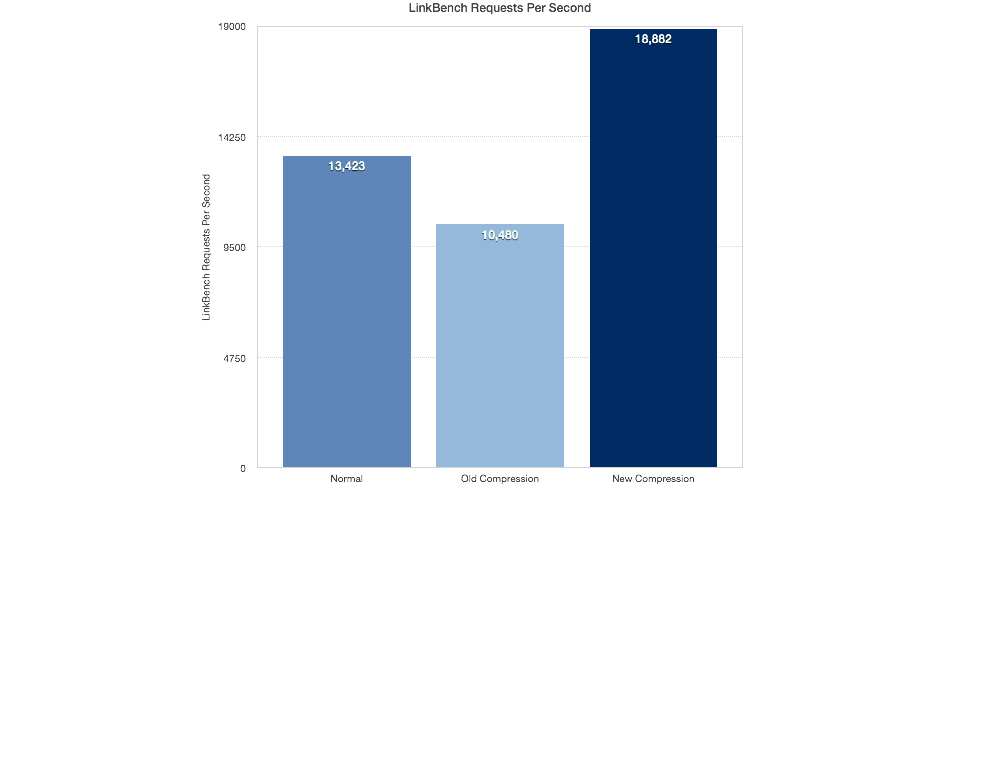 I was quite surprised with this result and it needs more analysis. The new transparent compression actually performed better than with no compression. I was not expecting this :-). Perhaps the new compression gives better numbers because it writes less data to the disk compared to the uncompressed table. I don’t know for sure yet.
I was quite surprised with this result and it needs more analysis. The new transparent compression actually performed better than with no compression. I was not expecting this :-). Perhaps the new compression gives better numbers because it writes less data to the disk compared to the uncompressed table. I don’t know for sure yet.
Space Savings
So it performs better, but does it save on disk space? The old compression performs a little better here, but only by about 1.5%.
The is using NVMFS: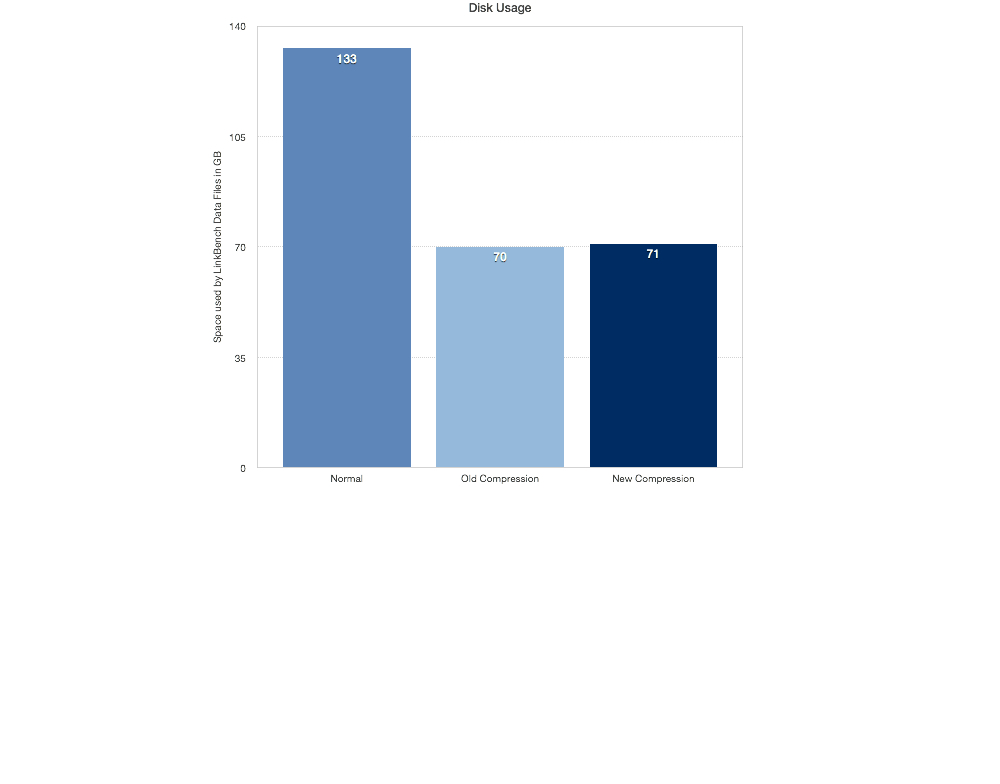
This is with the Intel SSD using EXT4: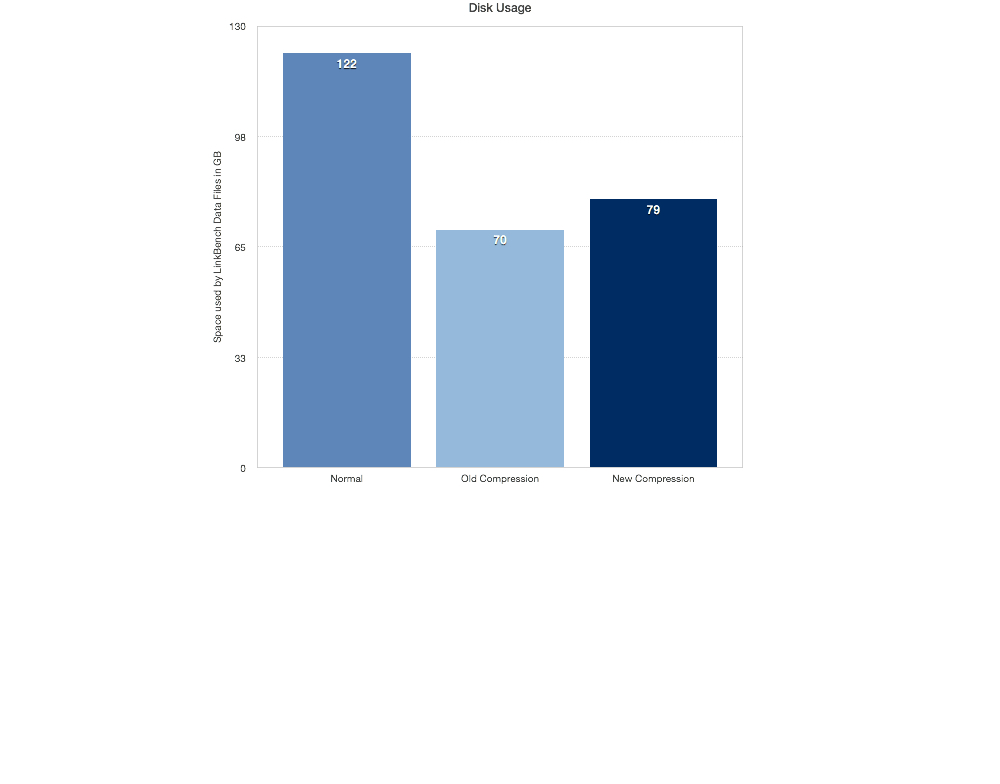
The old compression saves more space in our second test. This is likely because the block size on the EXT4 file system was set at the default of 4K. Next I want to check if using a smaller block size helps us and provides the better requests/per second numbers.
Conclusion
This feature adds more choice for our users. On the right hardware and file system combination you can get up to a 300% performance boost and get the same space savings you get with the older compression.
Please let us know what you think of this new feature. We’d love to hear your feedback! If you encounter any problems with this new feature, please let us know here in the comments, open a bug report at bugs.mysql.com, or open a support ticket.
Thank you for using MySQL!.