The MySQL NDB Cluster team works on fundamental redesigns of core parts of NDB architecture. One of these changes is the partial checkpoint algorithm. You can now take full advantage of it when building much larger clusters: NDB 8.0 can use 16 TB data memory per data node for in-memory tables. 3-replica 5 PB clusters can be build with disk data.
The new partial checkpoint algorithm executes restarts up to 4x faster, reduces checkpoint times by a factor of 6x in typical set-ups and minimizes cluster’s disk space consumption. In addition the new checkpoints reduce the synchronization delays between nodes. This makes smaller clusters much easier to maintain and allows in turn to build much larger clusters with higher storage capacity.
An in-memory database writing to disk?
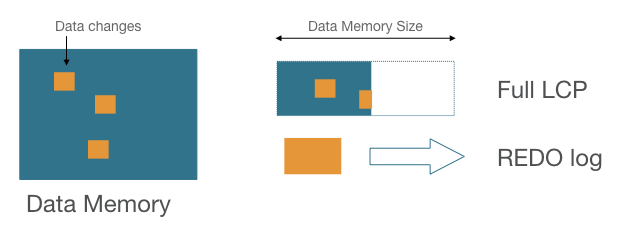
For durability, MySQL Cluster records in-memory data changes to parallel transaction logs (REDO) on disk. Periodic ‘local’ checkpoints (LCP) write all in-memory content to disk, allowing the REDO logs to be truncated giving bounds on disk space usage and recovery time.
In order to keep the disk latency out of the way of cluster’s real-time in-memory transactions LCPs to disk happen asynchronously in the background.
In previous MySQL Cluster versions these checkpoints always wrote the entire dataset to disk per checkpoint, known as ‘Full LCP’, a process that can take hours for databases with hundreds of GB of memory configured. During such an LCP, in write intense applications REDO logs could grow quite large. While LCPs were written locally on each node they had effects on node restarts, whith noticeable impact with increasing LCP duration.
The new checkpointing algorithm
A number of partial Local Checkpoints (pLCP) are maintained on disk. Each partial Local Checkpoint contains all changes made since the previous pLCP, but only a subset of the entire unchanged dataset.

During recovery the content of multiple pLCPs are restored together with REDO log content to return the entire dataset to its recovery point in-memory. This algorithm reduces the volume of data written per checkpoint, which linearly affects the checkpoint duration, affecting the REDO log size and synchronization delays. Together with some disk space usage optimisations, the total on-disk checkpoint size may also be reduced.
To ensure that LCP related synchronization delays are minimised in all situations, checkpoint execution on each node has been further decoupled to ensure that data node recovery cannot adversely affect LCP duration. This improves system stability and robustness.
How restarts become faster
The following numbers demonstrate the benefits of the new implementation. For the test we loaded 600 DBT2 warehouses into a 2 data node cluster with 100G DataMemory resulting in about 60GB of data stored.
We see an improvement of almost 3.5x in node restart times in this case. A normal node restart takes around 25 minutes in versions with the legacy LCP with some variance in the results. With partial checkpoints it only takes roughly 7 minutes to restart a node and the restart times are much more predictable. These are node restarts where cluster recovers data in the starting node while remaining nodes continue full service.
We take a closer look at where times are spent. Walking through the cluster node restart phases we can identify how cluster benefits:
During the initial setup phase memory is initialized. This takes time linear to the amount of memory to be initialized and is independent of checkpoint algorithms.
In the next phase data is restored from the checkpoints into cluster memory. This phase will actually take longer with partial checkpoints as multiple, smaller partial Local Checkpoints must be restored from disk.
During the REDO execution phase we start to see the real benefits of the new checkpoint algorithm. REDO logs are smaller and thus restore 2x as fast (43 seconds with partial checkpoints, 75 seconds with legacy LCP). With the additional improvements in our new UNDO log applier we will see an additional 5x improvement for datasets stored in disk tables.
The next phase is rebuilding indexes and this improved as well. The then following synch phase only lasts 3 – 4 seconds in any cluster version.
The most dramatic improvements are reached in the next phase. We need to execute (write) a Local Checkpoint during restart to insure that the data node can recover data independently. Data nodes have to wait for the checkpoint to finish. In this particular scenario a full LCP could take up to 20 minutes. With the new checkpointing executing faster the waiting time could be reduced down to only about 2 minutes.
The final handover phase is another short phase that will take short 6 – 7 seconds both with the old and the new checkpoint algorithm.
Tradeoffs?
With all the advantages listed I also want to mention the tradeoffs of the new checkpointing algorithm: online version upgrades from versions prior to the new partial checkpoint require an initial rolling restart of all data nodes. And this one time initial node restarts may take longer.