MySQL 9.7 Release Notes
Replication in NDB Cluster makes use of a number of dedicated
tables in the mysql database on each MySQL
Server instance acting as an SQL node in both the cluster being
replicated and in the replica. This is true regardless of whether
the replica is a single server or a cluster.
The ndb_binlog_index and
ndb_apply_status tables are created in the
mysql database. They should not be explicitly
replicated by the user. User intervention is normally not required
to create or maintain either of these tables, since both are
maintained by the NDB binary log
(binlog) injector thread. This keeps the source
mysqld process updated to changes performed by
the NDB storage engine. The
NDB binlog
injector thread receives events directly from the
NDB storage engine. The
NDB injector is responsible for
capturing all the data events within the cluster, and ensures that
all events which change, insert, or delete data are recorded in
the ndb_binlog_index table. The replica I/O
(receiver) thread transfers the events from the source's
binary log to the replica's relay log.
The ndb_replication table must be created
manually. This table can be updated by the user to perform
filtering by database or table. See
ndb_replication Table, for more
information. ndb_replication is also used in
NDB Replication conflict detection and resolution for conflict
resolution control; see
Conflict Resolution Control.
Even though ndb_binlog_index and
ndb_apply_status are created and maintained
automatically, it is advisable to check for the existence and
integrity of these tables as an initial step in preparing an NDB
Cluster for replication. It is possible to view event data
recorded in the binary log by querying the
mysql.ndb_binlog_index table directly on the
source. This can be also be accomplished using the
SHOW BINLOG EVENTS statement on
either the source or replica SQL node. (See
Section 15.7.7.3, “SHOW BINLOG EVENTS Statement”.)
You can also obtain useful information from the output of
SHOW ENGINE NDB
STATUS.
Note
When performing schema changes on
NDB tables, applications should
wait until the ALTER TABLE
statement has returned in the MySQL client connection that
issued the statement before attempting to use the updated
definition of the table.
ndb_apply_status is used to keep a record of
the operations that have been replicated from the source to the
replica. If the ndb_apply_status table does
not exist on the replica, ndb_restore
re-creates it.
Unlike the case with ndb_binlog_index, the
data in this table is not specific to any one SQL node in the
(replica) cluster, and so ndb_apply_status
can use the NDBCLUSTER storage engine, as
shown here:
CREATE TABLE `ndb_apply_status` (
`server_id` INT(10) UNSIGNED NOT NULL,
`epoch` BIGINT(20) UNSIGNED NOT NULL,
`log_name` VARCHAR(255) CHARACTER SET latin1 COLLATE latin1_bin NOT NULL,
`start_pos` BIGINT(20) UNSIGNED NOT NULL,
`end_pos` BIGINT(20) UNSIGNED NOT NULL,
PRIMARY KEY (`server_id`) USING HASH
) ENGINE=NDBCLUSTER DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
The ndb_apply_status table is populated only
on replicas, which means that, on the source, this table never
contains any rows; thus, there is no need to allot any
DataMemory to
ndb_apply_status there.
Because this table is populated from data originating on the
source, it should be allowed to replicate; any replication
filtering or binary log filtering rules that inadvertently
prevent the replica from updating
ndb_apply_status, or that prevent the source
from writing into the binary log may prevent replication between
clusters from operating properly. For more information about
potential problems arising from such filtering rules, see
Replication and binary log filtering rules with replication between NDB
Clusters.
It is possible to delete this table, but this is not
recommended. Deleting it puts all SQL nodes in read-only mode;
NDB detects that this table has been dropped,
and re-creates it, after which it is possible once again to
perform updates. Dropping and re-creating
ndb_apply_status creates a gap event in the
binary log; the gap event causes replica SQL nodes to stop
applying changes from the source until the replication channel
is restarted.
0 in the epoch column of
this table indicates a transaction originating from a storage
engine other than NDB.
ndb_apply_status is used to record which
epoch transactions have been replicated and applied to a replica
cluster from an upstream source. This information is captured in
an NDB online backup, but (by design) it is
not restored by ndb_restore. In some cases,
it can be helpful to restore this information for use in new
setups; you can do this by invoking
ndb_restore with the
--with-apply-status option.
See the description of the option for more information.
NDB Cluster Replication uses the
ndb_binlog_index table for storing the binary
log's indexing data. Since this table is local to each
MySQL server and does not participate in clustering, it uses the
InnoDB storage engine. This means
that it must be created separately on each
mysqld participating in the source cluster.
(The binary log itself contains updates from all MySQL servers
in the cluster.) This table is defined as follows:
CREATE TABLE `ndb_binlog_index` (
`Position` BIGINT(20) UNSIGNED NOT NULL,
`File` VARCHAR(255) NOT NULL,
`epoch` BIGINT(20) UNSIGNED NOT NULL,
`inserts` INT(10) UNSIGNED NOT NULL,
`updates` INT(10) UNSIGNED NOT NULL,
`deletes` INT(10) UNSIGNED NOT NULL,
`schemaops` INT(10) UNSIGNED NOT NULL,
`orig_server_id` INT(10) UNSIGNED NOT NULL,
`orig_epoch` BIGINT(20) UNSIGNED NOT NULL,
`gci` INT(10) UNSIGNED NOT NULL,
`next_position` bigint(20) unsigned NOT NULL,
`next_file` varchar(255) NOT NULL,
PRIMARY KEY (`epoch`,`orig_server_id`,`orig_epoch`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
Note
If you are upgrading from an older release, perform the MySQL
upgrade procedure and ensure that the system tables are
upgraded by starting the MySQL server with the
--upgrade=FORCE option. The system table
upgrade causes an
ALTER TABLE ...
ENGINE=INNODB statement to be executed for this
table. Use of the MyISAM storage engine for
this table continues to be supported for backward
compatibility.
ndb_binlog_index may require additional
disk space after being converted to InnoDB.
If this becomes an issue, you may be able to conserve space by
using an InnoDB tablespace for this table,
changing its ROW_FORMAT to
COMPRESSED, or both. For more information,
see Section 15.1.26, “CREATE TABLESPACE Statement”, and
Section 15.1.25, “CREATE TABLE Statement”, as well as
Section 17.6.3, “Tablespaces”.
The size of the ndb_binlog_index table is
dependent on the number of epochs per binary log file and the
number of binary log files. The number of epochs per binary log
file normally depends on the amount of binary log generated per
epoch and the size of the binary log file, with smaller epochs
resulting in more epochs per file. You should be aware that
empty epochs produce inserts to the
ndb_binlog_index table, even when the
--ndb-log-empty-epochs option is
OFF, meaning that the number of entries per
file depends on the length of time that the file is in use; this
relationship can be represented by the formula shown here:
[number of epochs per file] = [time spent per file] / TimeBetweenEpochs
A busy NDB Cluster writes to the binary log regularly and
presumably rotates binary log files more quickly than a quiet
one. This means that a “quiet” NDB Cluster with
--ndb-log-empty-epochs=ON can
actually have a much higher number of
ndb_binlog_index rows per file than one with
a great deal of activity.
When mysqld is started with the
--ndb-log-orig option, the
orig_server_id and
orig_epoch columns store, respectively, the
ID of the server on which the event originated and the epoch in
which the event took place on the originating server, which is
useful in NDB Cluster replication setups employing multiple
sources. The SELECT statement
used to find the closest binary log position to the highest
applied epoch on the replica in a multi-source setup (see
Section 25.7.10, “NDB Cluster Replication: Bidirectional and Circular Replication”)
employs these two columns, which are not indexed. This can lead
to performance issues when trying to fail over, since the query
must perform a table scan, especially when the source has been
running with
--ndb-log-empty-epochs=ON. You
can improve multi-source failover times by adding an index to
these columns, as shown here:
ALTER TABLE mysql.ndb_binlog_index
ADD INDEX orig_lookup USING BTREE (orig_server_id, orig_epoch);
Adding this index provides no benefit when replicating from a
single source to a single replica, since the query used to get
the binary log position in such cases makes no use of
orig_server_id or
orig_epoch.
See Section 25.7.8, “Implementing Failover with NDB Cluster Replication”, for
more information about using the
next_position and
next_file columns.
The following figure shows the relationship of the NDB Cluster
replication source server, its binary log injector thread, and
the mysql.ndb_binlog_index table.
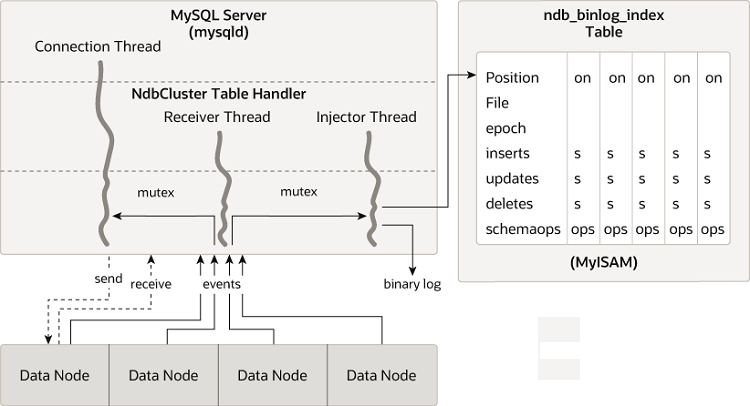
The ndb_replication table is used to control
binary logging and conflict resolution, and acts on a per-table
basis. Each row in this table corresponds to a table being
replicated, determines how to log changes to the table and, if a
conflict resolution function is specified, and determines how to
resolve conflicts for that table.
Unlike the ndb_apply_status and
ndb_replication tables, the
ndb_replication table must be created
manually, using the SQL statement shown here:
CREATE TABLE mysql.ndb_replication (
db VARBINARY(63),
table_name VARBINARY(63),
server_id INT UNSIGNED,
binlog_type INT UNSIGNED,
binlog_row_slice_count UNSIGNED,
binlog_row_slice_id UNSIGNED,
conflict_fn VARBINARY(128),
PRIMARY KEY USING HASH (db, table_name, server_id)
) ENGINE=NDB
PARTITION BY KEY(db,table_name);The columns of this table are listed here, with descriptions:
dbcolumnThe name of the database containing the table to be replicated.
You may employ either or both of the wildcards
_and%as part of the database name. (See Matching with wildcards, later in this section.)table_namecolumnThe name of the table to be replicated.
The table name may include either or both of the wildcards
_and%. See Matching with wildcards, later in this section.server_idcolumnThe unique server ID of the MySQL instance (SQL node) where the table resides.
0in this column acts like a wildcard equivalent to%, and matches any server ID. (See Matching with wildcards, later in this section.)binlog_typecolumnThe type of binary logging to be employed. See text for values and descriptions.
binlog_row_slice_countcolumnThe number of slices into which to divide the binary log.
1if slicing is not being used for this table;0is ignored and is thus effectively the same as1.binlog_row_slice_idcolumnThe ID of the slice for this server to log.
0if slicing is not being used for this table.conflict_fncolumnThe conflict resolution function to be applied; one of NDB$OLD(), NDB$MAX(), NDB$MAX_DELETE_WIN(), NDB$EPOCH(), NDB$EPOCH_TRANS(), NDB$EPOCH2(), NDB$EPOCH2_TRANS() NDB$MAX_INS(), or NDB$MAX_DEL_WIN_INS();
NULLindicates that conflict resolution is not used for this table.See Conflict Resolution Functions, for more information about these functions and their uses in NDB Replication conflict resolution.
Some conflict resolution functions (
NDB$OLD(),NDB$EPOCH(),NDB$EPOCH_TRANS()) require the use of one or more user-created exceptions tables. See Conflict Resolution Exceptions Table.
To enable conflict resolution with NDB Replication, it is necessary to create and populate this table with control information on the SQL node or nodes on which the conflict should be resolved. Depending on the conflict resolution type and method to be employed, this may be the source, the replica, or both servers. In a simple source-replica setup where data can also be changed locally on the replica this is typically the replica. In a more complex replication scheme, such as bidirectional replication, this is usually all of the sources involved. See Section 25.7.12, “NDB Cluster Replication Conflict Resolution”, for more information.
The ndb_replication table allows table-level
control over binary logging outside the scope of conflict
resolution, in which case conflict_fn is
specified as NULL, while the remaining column
values are used to control binary logging for a given table or
set of tables matching a wildcard expression. By setting the
proper value for the binlog_type column, you
can make logging for a given table or tables use a desired
binary log format, or disabling binary logging altogether.
Possible values for this column, with
values and descriptions, are shown in the following table:
Table 25.42 binlog_type values, with values and descriptions
| Value | Description |
|---|---|
| 0 | Use server default |
| 1 | Do not log this table in the binary log (same effect as
sql_log_bin = 0, but
applies to one or more specified tables only) |
| 2 | Log updated attributes only; log these as WRITE_ROW
events |
| 3 | Log full row, even if not updated (MySQL server default behavior) |
| 6 | Use updated attributes, even if values are unchanged |
| 7 | Log full row, even if no values are changed; log updates as
UPDATE_ROW events |
| 8 | Log update as UPDATE_ROW; log only primary key
columns in before image, and only updated columns in after
image (same effect as
--ndb-log-update-minimal,
but applies to one or more specified tables only) |
| 9 | Log update as UPDATE_ROW; log only primary key
columns in before image, and all columns other than
primary key columns in after image |
Note
binlog_type values 4 and 5 are not used,
and so are omitted from the table just shown, as well as from
the next table.
Several binlog_type values are equivalent to
various combinations of the mysqld logging
options --ndb-log-updated-only,
--ndb-log-update-as-write, and
--ndb-log-update-minimal, as
shown in the following table:
Table 25.43 binlog_type values with equivalent combinations of NDB logging options
| Value | --ndb-log-updated-only Value |
--ndb-log-update-as-write Value |
--ndb-log-update-minimal Value |
|---|---|---|---|
| 0 | -- | -- | -- |
| 1 | -- | -- | -- |
| 2 | ON | ON | OFF |
| 3 | OFF | ON | OFF |
| 6 | ON | OFF | OFF |
| 7 | OFF | OFF | OFF |
| 8 | ON | OFF | ON |
| 9 | OFF | OFF | ON |
Binary logging can be set to different formats for different
tables by inserting rows into the
ndb_replication table using the appropriate
db, table_name, and
binlog_type column values. The internal
integer value shown in the preceding table should be used when
setting the binary logging format. The following two statements
set binary logging to logging of full rows (
value 3) for table test.a, and to logging of
updates only (
value 2) for table test.b:
# Table test.a: Log full rows
INSERT INTO mysql.ndb_replication VALUES("test", "a", 0, 3, 1, 0, NULL);
# Table test.b: log updates only
INSERT INTO mysql.ndb_replication VALUES("test", "b", 0, 2, 1, 0, NULL);
To disable logging for one or more tables, use 1
for binlog_type, as shown here:
# Disable binary logging for table test.t1
INSERT INTO mysql.ndb_replication VALUES("test", "t1", 0, 1, 1, 0, NULL);
# Disable binary logging for any table in 'test' whose name begins with 't'
INSERT INTO mysql.ndb_replication VALUES("test", "t%", 0, 1, 1, 0, NULL);
Disabling logging
for a given table is the equivalent of setting
sql_log_bin = 0, except that it
applies to one or more tables individually.
If an SQL node is not performing binary logging for a given
table, it is not sent the row change events for those tables.
This means that it is not receiving all changes and discarding
some, but rather it is not subscribing to these changes.
Disabling logging can be useful for a number of reasons, including those listed here:
Not sending changes across the network generally saves bandwidth, buffering, and CPU resources.
Not logging changes to tables with very frequent updates but whose value is not great is a good fit for transient data (such as session data) that may be relatively unimportant in the event of a complete failure of the cluster.
Using a session variable (or
sql_log_bin) and application code, it is also possible to log (or not to log) certain SQL statements or types of SQL statements; for example, it may be desirable in some cases not to record DDL statements on one or more tables.Splitting replication streams into two (or more) binary logs can be done for reasons of performance, a need to replicate different databases to different places, use of different binary logging types for different databases, and so on.
Per-table binary log slicing.
You can distribute logging for a given table among multiple
MySQL servers by inserting appropriate values for the
binlog_row_slice_count and
binlog_row_slice_id columns.
binlog_row_slice_count is the number of
binary log slices, and should be the same for all MySQL
servers in this group; binlog_row_slice_id
determines which slice is written to a given server's
binary log.
For example, inserting these rows into the table causes the
mysqld with the slice ID 0
to log half of the row changes for table t1,
while another mysqld (whose slice ID is
1) logs the other half:
mysql> INSERT INTO mysql.ndb_replication VALUES ("test", "t1", 1, 2, 2, 0, NULL);
mysql> INSERT INTO mysql.ndb_replication VALUES ("test", "t1", 2, 2, 2, 1, NULL);
In both statements, 2 is inserted into the
binlog_row_slice_count column. Similarly, the
binary logging for t2 can be divided into
four slices by inserting four rows into the
ndb_replication table, each row using
4 in the
binlog_row_slice_count column and IDs in
sequence in the binlog_row_slice_id column,
like this:
mysql> INSERT INTO mysql.ndb_replication VALUES ("test", "t2", 1, 2, 4, 0, NULL);
mysql> INSERT INTO mysql.ndb_replication VALUES ("test", "t2", 2, 2, 4, 1, NULL);
mysql> INSERT INTO mysql.ndb_replication VALUES ("test", "t2", 3, 2, 4, 2, NULL);
mysql> INSERT INTO mysql.ndb_replication VALUES ("test", "t2", 4, 2, 4, 3, NULL);
It is also possible to set up redundant per-slice logging by
inserting duplicate rows into the
ndb_replication table. For example, the
following INSERT statement yields
two groups of three servers each, each splitting the binary
logging for table t3 into three slices:
mysql> INSERT INTO mysql.ndb_replication
-> VALUES
-> ("test", "t3", 1, 2, 3, 0, NULL),
-> ("test", "t3", 2, 2, 3, 1, NULL),
-> ("test", "t3", 3, 2, 3, 2, NULL),
-> ("test", "t3", 4, 2, 3, 0, NULL),
-> ("test", "t3", 5, 2, 3, 1, NULL),
-> ("test", "t3", 6, 2, 3, 2, NULL);
You can also perform this task more generally (for all
NDBCLUSTER tables in a given MySQL Cluster at
one time) by starting the servers with the
--ndb-log-row-slice-count and
--ndb-log-row-slice-id options.
See the descriptions of these options for further information.
Matching with wildcards.
In order not to make it necessary to insert a row in the
ndb_replication table for each and every
combination of database, table, and SQL node in your
replication setup, NDB supports wildcard
matching on the this table's db,
table_name, and
server_id columns. Database and table names
used in, respectively, db and
table_name may contain either or both of
the following wildcards:
_(underscore character): matches zero or more characters%(percent sign): matches a single character
(These are the same wildcards as supported by the MySQL
LIKE operator.)
The server_id column supports
0 as a wildcard equivalent to
_ (matches anything). This is used in the
examples shown previously.
A given row in the ndb_replication table can
use wildcards to match any of the database name, table name, and
server ID in any combination. Where there are multiple potential
matches in the table, the best match is chosen, according to the
table shown here, where W represents a
wildcard match, E an exact match, and the
greater the value in the Quality column,
the better the match:
Table 25.44 Weights of different combinations of wildcard and exact matches on columns in the mysql.ndb_replication table
db |
table_name |
server_id |
Quality |
|---|---|---|---|
| W | W | W | 1 |
| W | W | E | 2 |
| W | E | W | 3 |
| W | E | E | 4 |
| E | W | W | 5 |
| E | W | E | 6 |
| E | E | W | 7 |
| E | E | E | 8 |
Thus, an exact match on database name, table name, and server ID is considered best (strongest), while the weakest (worst) match is a wildcard match on all three columns. Only the strength of the match is considered when choosing which rule to apply; the order in which the rows occur in the table has no effect on this determination.
Logging Full or Partial Rows.
There are two basic methods of logging rows, as determined by
the setting of the
--ndb-log-updated-only option
for mysqld:
Log complete rows (option set to
ON)Log only column data that has been updated—that is, column data whose value has been set, regardless of whether or not this value was actually changed. This is the default behavior (option set to
OFF).
It is usually sufficient—and more efficient—to log
updated columns only; however, if you need to log full rows, you
can do so by setting
--ndb-log-updated-only to
0 or OFF.
Logging Changed Data as Updates.
The setting of the MySQL Server's
--ndb-log-update-as-write
option determines whether logging is performed with or without
the “before” image.
Because conflict resolution for updates and delete operations is done in the MySQL Server's update handler, it is necessary to control the logging performed by the replication source such that updates are updates and not writes; that is, such that updates are treated as changes in existing rows rather than the writing of new rows, even though these replace existing rows.
This option is turned on by default; in other words, updates are
treated as writes. That is, updates are by default written as
write_row events in the binary log, rather
than as update_row events.
To disable the option, start the source
mysqld with
--ndb-log-update-as-write=0 or
--ndb-log-update-as-write=OFF. You must do this
when replicating from NDB tables to tables using a different
storage engine; see
Replication from NDB to other storage engines, and
Replication from NDB to a nontransactional storage engine,
for more information.
Important
For insert conflict resolution using
NDB$MAX_INS() or
NDB$MAX_DEL_WIN_INS(), an SQL node (that
is, a mysqld process) can record row
updates on the source cluster as WRITE_ROW
events with the
--ndb-log-update-as-write
option enabled for idempotency and optimal size. This works
for these algorithms since they both map a
WRITE_ROW event to an insert or update
depending on whether the row already exists, and the required
metadata (the “after” image for the timestamp
column) is present in the “WRITE_ROW” event.