PDF (US Ltr)
- 2.5Mb
PDF (A4)
- 2.5Mb
Table of Contents
- 9.1 InnoDB ClusterSet Requirements
- 9.2 InnoDB ClusterSet Limitations
- 9.3 User Accounts for InnoDB ClusterSet
- 9.4 Deploying InnoDB ClusterSet
- 9.5 Asynchronous Replication Channel Options
- 9.6 Integrating MySQL Router With InnoDB ClusterSet
- 9.7 InnoDB ClusterSet Status and Topology
- 9.8 InnoDB ClusterSet Controlled Switchover
- 9.9 InnoDB ClusterSet Emergency Failover
- 9.10 InnoDB ClusterSet Repair and Rejoin
- 9.11 Dissolving a ClusterSet
- 9.12 Upgrade InnoDB ClusterSet
MySQL InnoDB ClusterSet provides disaster tolerance for InnoDB Cluster deployments by linking a primary InnoDB Cluster with one or more replicas of itself in alternate locations, such as different datacenters. InnoDB ClusterSet automatically manages replication from the primary cluster to the replica clusters using a dedicated ClusterSet replication channel. If the primary cluster becomes unavailable due to the loss of the data center or the loss of network connectivity to it, you can make a replica cluster active instead to restore the availability of the service. See Chapter 8, MySQL InnoDB Cluster for information on deploying InnoDB Cluster.
Emergency failover between the primary InnoDB Cluster and a replica cluster in an InnoDB ClusterSet deployment can be triggered by an administrator through MySQL Shell (see MySQL Shell 9.7), using AdminAPI (see Section 6.1, “Using MySQL AdminAPI”), which is included with MySQL Shell. You can also carry out a controlled switchover from the primary cluster to a replica cluster while the primary cluster is still available, for example if a configuration change or maintenance is required on the primary cluster. MySQL Router (see MySQL Router 9.7) automatically routes client applications to the right clusters in an InnoDB ClusterSet deployment.
A replica cluster in an InnoDB ClusterSet deployment cannot diverge from the primary cluster while it remains a passive replica, because it does not accept writes. It can be read by applications, although a typical amount of replication lag for asynchronous replication should be expected, so the data might not be complete yet. The minimum size of a replica cluster is a single member server instance, but a minimum of three members is recommended for fault tolerance. If more members are needed, for example because the replica cluster has become a primary cluster through a switchover or failover, you can add further instances at any time through MySQL Shell using AdminAPI. There is no defined limit on the number of replica clusters that you can have in an InnoDB ClusterSet deployment.
The example InnoDB ClusterSet deployment in the following diagram consists of a primary InnoDB Cluster in the Rome datacenter, with replica clusters in the Lisbon and Brussels datacenters. The primary cluster and its replica clusters each consist of three member server instances, one primary and two secondaries.
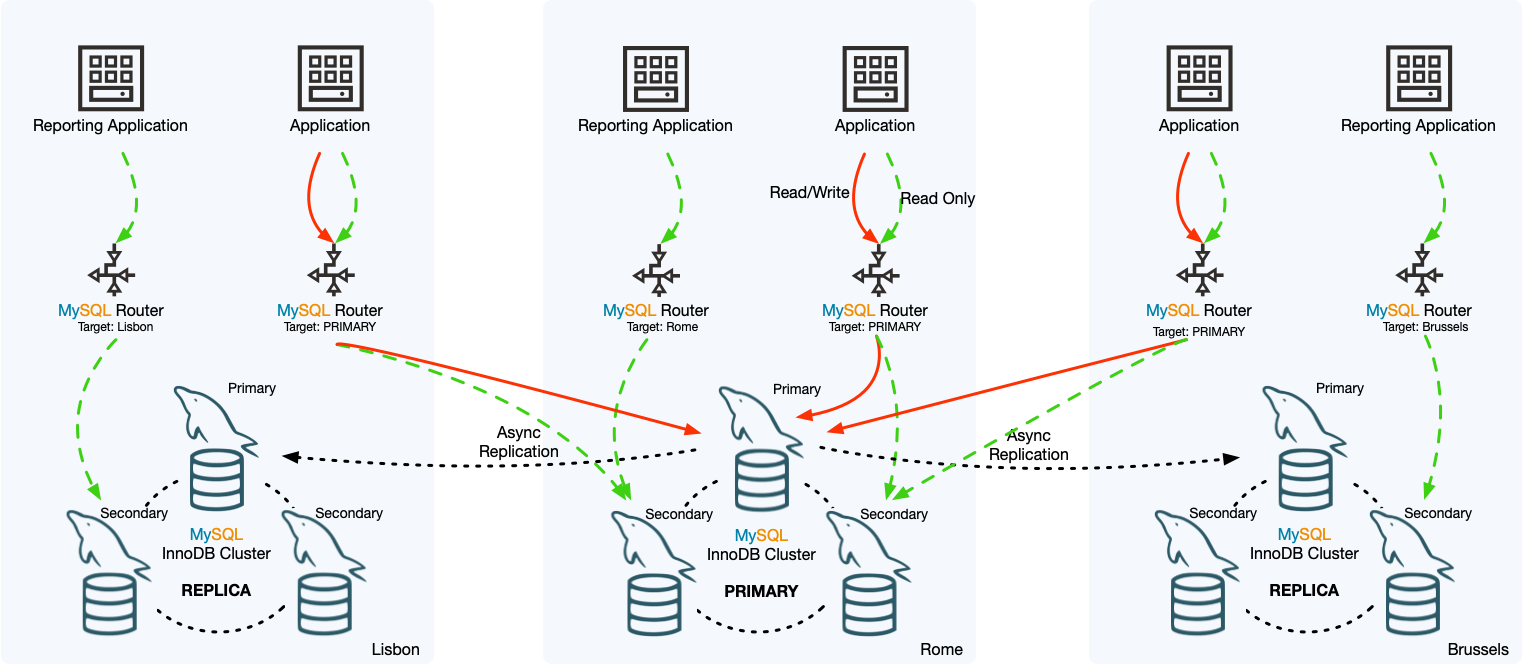
Asynchronous replication channels replicate transactions from the
primary cluster to the replica clusters. A ClusterSet replication
channel named clusterset_replication is set up on
each cluster during the InnoDB ClusterSet creation process, and
when a cluster is a replica, it uses the channel to replicate
transactions from the primary. The underlying Group Replication
technology manages the channel and ensures that replication is
always taking place between the primary server of the primary
cluster (as the sender), and the primary server of the replica
cluster (as the receiver). If a new primary is elected for either
the primary cluster or the replica cluster, the ClusterSet
replication channel is automatically re-established between them.
Although each cluster in the example InnoDB ClusterSet deployment has a primary MySQL server, only the primary server of the primary InnoDB Cluster accepts write traffic from client applications. The replica clusters do not. MySQL Router instances route all write traffic to the primary cluster in the Rome datacenter, where it is handled by the primary server. Most of the read traffic is also routed to the primary cluster, but the reporting applications that only make read requests are specifically routed to the replica cluster in their local datacenter instead, to save on networking resources. Notice that the MySQL Router instances that handle read and write traffic are set to route traffic to the primary InnoDB Cluster in the InnoDB ClusterSet whichever one that is. So if one of the other clusters becomes the primary following a controlled switchover or emergency failover, those MySQL Router instances will route traffic to that cluster instead.
It is important to know that InnoDB ClusterSet prioritizes availability over data consistency in order to maximize disaster tolerance. Consistency within each individual InnoDB Cluster is guaranteed by the underlying Group Replication technology. However, normal replication lag or network partitions can mean that some or all of the replica clusters are not fully consistent with the primary cluster at the time the primary cluster experiences an issue. In these scenarios, if you trigger an emergency failover, any unreplicated or divergent transactions are at risk of being lost, and can only be recovered and reconciled manually (if they can be accessed at all). There is no guarantee that data will be preserved in the event of an emergency failover.
You should therefore always make an attempt to repair or reconnect the primary cluster before triggering an emergency failover. AdminAPI removes the need to work directly with Group Replication to repair an InnoDB Cluster. If the primary cluster cannot be repaired quickly enough or cannot be reached, you can go ahead with the emergency failover to a replica InnoDB Cluster, to restore availability for applications. During a controlled switchover process, data consistency is assured, and the original primary cluster is demoted to a working read-only replica cluster. However, during an emergency failover process, data consistency is not assured, so for safety, the original primary cluster is marked as invalidated during the failover process. If the original primary cluster remains online, it should be shut down as soon as it can be contacted.
You can rejoin an invalidated primary cluster to the InnoDB ClusterSet topology afterwards, provided that there are no issues and the transaction set is consistent with the other clusters in the topology. Checking, restoring, and rejoining the invalidated primary cluster does not happen automatically - an administrator needs to do this using AdminAPI commands. You can choose to repair the invalidated primary cluster and bring it back online, or you can discard the original primary cluster, continue to use the new primary cluster as the primary, and create new replica clusters.