PDF (US Ltr)
- 2.3Mb
PDF (A4)
- 2.3Mb
An emergency failover makes a selected replica cluster into the primary InnoDB Cluster for the InnoDB ClusterSet deployment. This procedure can be used when the current primary cluster is not working or cannot be contacted. During an emergency failover process, data consistency is not assured, so for safety, the original primary cluster is marked as invalidated during the failover process. If the original primary cluster remains online, it should be shut down as soon as it can be contacted. You can repair and rejoin an invalidated primary cluster to the InnoDB ClusterSet topology afterwards, provided that you can fix the issues.
When the primary InnoDB Cluster in an InnoDB ClusterSet deployment has an issue or you cannot access it, do not immediately implement an emergency failover to a replica cluster. Instead, you should always start by attempting to repair the currently active primary cluster.
Important
Why Not Just Fail Over? The replica clusters in the InnoDB ClusterSet topology are doing their best to keep themselves synchronized with the primary cluster. However, depending on the volume of transactions and the speed and capacity of the network connections between the primary cluster and the replica clusters, replica clusters can fall behind the primary cluster in receiving transactions and applying the changes to their data. This is called replication lag. Some replication lag is to be expected in most replication topologies, and is quite likely in an InnoDB ClusterSet deployment where the clusters are geographically dispersed and in different data centers.
Also, it is possible for the primary cluster to become disconnected from other elements of the InnoDB ClusterSet topology by a network partition, but remain online. If that happens, some replica clusters might stay with the primary cluster, and some instances and client applications might continue to connect to the primary cluster and apply transactions. In this situation, the partitioned areas of the InnoDB ClusterSet topology begin to diverge from each other, with a different transaction set on each group of servers.
When there is replication lag or a network partition, if you trigger an emergency failover to a replica cluster, any unreplicated or divergent transactions on the primary cluster are at risk of being lost. In the case of a network partition, the failover can create a split-brain situation, where the different parts of the topology have divergent transaction sets. You should therefore always make an attempt to repair or reconnect the primary cluster before triggering an emergency failover. If the primary cluster cannot be repaired quickly enough or cannot be reached, you can go ahead with the emergency failover.
The diagram shows the effects of an emergency failover in an example InnoDB ClusterSet deployment. The primary cluster in the Rome datacenter has gone offline, so an emergency failover has been carried out to make the replica cluster in the Brussels datacenter into the primary InnoDB Cluster of the InnoDB ClusterSet deployment. The Rome cluster has been marked as invalidated, and its status in the InnoDB ClusterSet deployment has been demoted to a replica cluster, although it is not currently able to replicate transactions from the Brussels cluster.
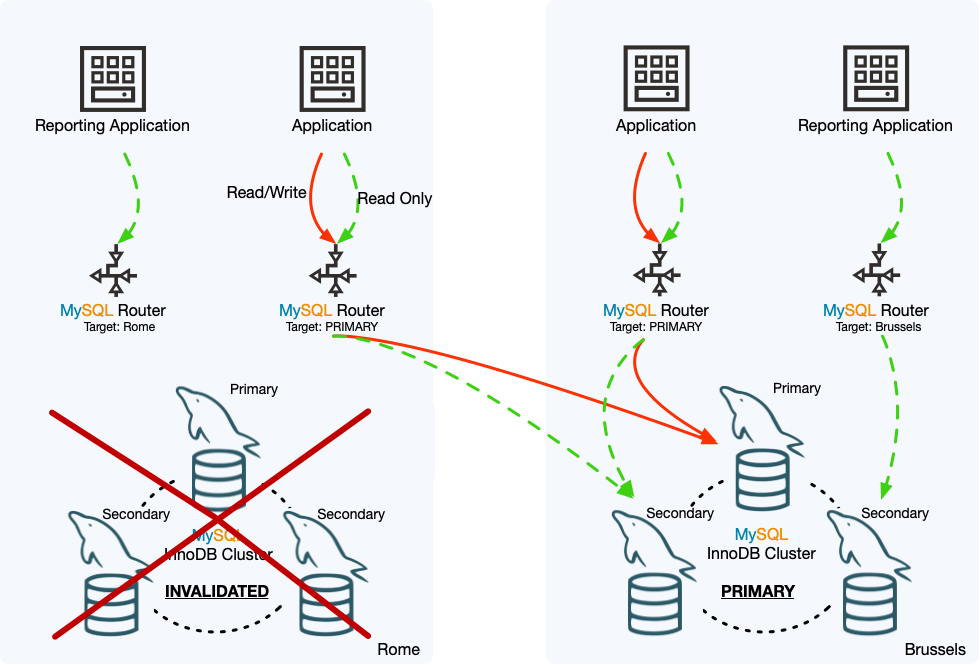
The MySQL Router instances that were set to follow the primary have routed read and write traffic to the Brussels cluster which is now the primary. The MySQL Router instance that was routing read traffic to the Brussels cluster by name when it was a replica cluster, continues to route traffic to it, and is not affected by the fact that the cluster is now the primary rather than a replica cluster. However, the MySQL Router instance that was routing read traffic to the Rome cluster by name cannot currently send any traffic there. The reporting application in this example does not need to report when the local datacenter is offline, but if the application did still need to function, the MySQL Router instance should have its routing options changed either to follow the primary or to send traffic to the Brussels cluster.
To carry out an emergency failover for the primary InnoDB Cluster, follow this procedure:
-
Using MySQL Shell, connect to any member server that is still active in the InnoDB ClusterSet deployment, using an InnoDB Cluster administrator account (created with
cluster.setupAdminAccount()When the connection is established, get the
ClusterSetobject from that member server using adba.getClusterSet()orcluster.getClusterSet()ClusterSetobject that you previously retrieved from a member server that is now offline will not work any more, so you need to get it again from a server that is online. It is important to use an InnoDB Cluster administrator account or server configuration account so that the default user account stored in theClusterSetobject has the correct permissions. For example:mysql-js> \connect admin2@127.0.0.1:4410 Creating a session to 'admin2@127.0.0.1:4410' Please provide the password for 'admin2@127.0.0.1:4410': ******** Save password for 'admin2@127.0.0.1:4410'? [Y]es/[N]o/Ne[v]er (default No): Fetching schema names for autocompletion... Press ^C to stop. Closing old connection... Your MySQL connection id is 71 Server version: 8.0.27-commercial MySQL Enterprise Server - Commercial No default schema selected; type \use <schema> to set one. <ClassicSession:admin2@127.0.0.1:4410> mysql-js> myclusterset = dba.getClusterSet() <ClusterSet:testclusterset> -
Check the status of the whole deployment using AdminAPI's
clusterSet.status()extendedoption to see exactly where and what the issues are. For example:mysql-js> myclusterset.status({extended: 1})For an explanation of the output, see Section 8.7, “InnoDB ClusterSet Status and Topology”.
-
An InnoDB Cluster can tolerate some issues and be functioning well enough to continue as part of the InnoDB ClusterSet deployment. A primary cluster that is functioning acceptably has the global status
OKwhen you check it using theclusterSet.status()If the primary cluster is still functioning acceptably in the InnoDB ClusterSet deployment according to the reported status, but you need to carry out maintenance or fix some minor issues to improve the primary cluster's function, you can carry out a controlled switchover to a replica cluster. You can then take the primary cluster offline if necessary, repair any issues, and bring it back into operation in the InnoDB ClusterSet deployment. For instructions to do this, see Section 8.8, “InnoDB ClusterSet Controlled Switchover”.
If the primary cluster is not functioning acceptably (with the global status
NOT_OK) in the InnoDB ClusterSet deployment, but you can contact it, first try to repair any issues using AdminAPI through MySQL Shell. For example, if the primary cluster has lost quorum, it can be restored using acluster.forceQuorumUsingPartitionOf-
If you cannot carry out a controlled switchover, and you cannot fix the issue quickly enough by working with the primary cluster (for example, because you cannot contact it), proceed with the emergency failover. First identify a suitable replica cluster that can take over as the primary cluster. A replica cluster's eligibility for an emergency failover depends on its global status, as reported by the
clusterSet.status()Table 8.2 Permitted Cluster Operations By Status
InnoDB Cluster Global Status in ClusterSet Routable Controlled Switchover Emergency Failover OKYes Yes Yes OK_NOT_REPLICATINGYes, if specified as target cluster by name Yes Yes OK_NOT_CONSISTENTYes, if specified as target cluster by name No Yes OK_MISCONFIGUREDYes Yes Yes NOT_OKNo No No INVALIDATEDYes, if specified as target cluster by name and accept_rorouting policy is setNo No UNKNOWNConnected Router instances might still be routing traffic to the cluster No No The replica cluster you select must have the most up to date set of transactions (GTID set) among all of the replica clusters that are reachable. If more than one replica cluster is eligible for the emergency failover, check the replication lag for each cluster (which is shown in the extended output for the
clusterSet.status() -
Check the routing options that are set for each MySQL Router instance, and the global policy for the InnoDB ClusterSet deployment, by issuing a
clusterSet.routingOptions()mysql-js> myclusterset.routingOptions() { "domainName": "testclusterset", "global": { "invalidated_cluster_policy": "drop_all", "target_cluster": "primary" }, "routers": { "Rome1": { "target_cluster": "primary" }, "Rome2": {} } }If all the MySQL Router instances are set to follow the primary (
"target_cluster": "primary"), traffic will be automatically redirected to the new primary cluster within a few seconds of the failover. If a routing option is not displayed for a MySQL Router instance, as in the example above with"target_cluster"forRome2, it means the instance does not have that policy set, and it follows the global policy.If any of the instances are set to target the current primary cluster by name (
"target_cluster": "), they will not redirect traffic to the new primary. When the primary cluster is not functioning, thename_of_primary_cluster"clusterSet.setRoutingOption() If you can, try to verify that the original primary cluster is offline, and if it is online, attempt to shut it down. If it remains online and continues to receive traffic from clients, a split-brain situation can be created where the separated parts of the InnoDB ClusterSet diverge.
-
To proceed with the emergency failover, issue a
clusterSet.forcePrimaryCluster()mysql-js> myclusterset.forcePrimaryCluster("clustertwo") Failing-over primary cluster of the clusterset to 'clustertwo' * Verifying primary cluster status None of the instances of the PRIMARY cluster 'clusterone' could be reached. * Verifying clusterset status ** Checking cluster clustertwo Cluster 'clustertwo' is available ** Checking whether target cluster has the most recent GTID set * Promoting cluster 'clustertwo' * Updating metadata PRIMARY cluster failed-over to 'clustertwo'. The PRIMARY instance is '127.0.0.1:4410' Former PRIMARY cluster was INVALIDATED, transactions that were not yet replicated may be lost.In the
clusterSet.forcePrimaryCluster()The
clusterNameparameter is required and specifies the identifier used for the replica cluster in the InnoDB ClusterSet, as given in the output from theclusterSet.status()clustertwoUse the
dryRunoption if you want to carry out validations and log the changes without actually executing them.Use the
invalidateReplicaClustersoption to name any replica clusters that are unreachable or unavailable. These will be marked as invalidated during the failover process. The failover is canceled if any unreachable or unavailable replica clusters that you do not name are discovered during the process. In this situation you must either repair and rejoin the replica clusters then retry the command, or name them on this option when you retry the command, and fix them later.Use the
timeoutoption to define the maximum number of seconds to wait for pending transactions to be applied in each instance of the cluster. Ensuring GTID_EXECUTED has the most up-to-date GTID set. The default value is retrieved from thedba.gtidWaitTimeoutoption.
When you issue the
clusterSet.forcePrimaryCluster()If the target replica cluster meets the requirements, MySQL Shell carries out the following tasks:
Attempts to contact the current primary cluster, and stops the failover if it actually can be reached.
Checks for any unreachable or unavailable replica clusters that have not been specified using
invalidateReplicaClusters, and stops the failover if any are found.Marks all replica clusters listed in
invalidateReplicaClustersas invalidated, and marks the old primary cluster as invalidated.Checks that the target replica cluster has the most up to date GTID set among the available replica clusters. This involves stopping the ClusterSet replication channel in all of the replica clusters.
Updates the ClusterSet replication channel on all replica clusters to replicate from the target cluster as the new primary cluster.
Sets the target cluster as the primary cluster in the ClusterSet metadata, and changes the old primary cluster into a replica cluster, although it is not currently functioning as a replica cluster because it is marked as invalidated.
During an emergency failover, MySQL Shell does not attempt to synchronize the target replica cluster with the current primary cluster, and does not lock the current primary cluster. If the original primary cluster remains online, it should be shut down as soon as it can be contacted.
-
If you have any MySQL Router instances to switch over to targeting the new primary cluster, do that now. You can change them to follow the primary (
"target_cluster": "primary"), or specify the replica cluster that has taken over as the primary ("target_cluster": "). For example:name_of_new_primary_cluster"mysql-js> myclusterset.setRoutingOption('Rome1', 'target_cluster', 'primary') or mysql-js> myclusterset.setRoutingOption('Rome1', 'target_cluster', 'clustertwo') Routing option 'target_cluster' successfully updated in router 'Rome1'.Issue a
clusterSet.routingOptions() Issue a
clusterSet.status()extendedoption, to verify the status of the InnoDB ClusterSet deployment.-
If and when you are able to contact the old primary cluster again, first ensure that no application traffic is being routed to it, and take it offline. Then follow the process in Section 8.10, “InnoDB ClusterSet Repair and Rejoin” to check the transactions and decide how to arrange the InnoDB ClusterSet topology going forward.
Following an emergency failover, and there is a risk of the transaction sets differing between parts of the ClusterSet, you have to fence the cluster either from write traffic or all traffic. For more details, see Fencing Clusters in an InnoDB ClusterSet.
If you had to invalidate any replica clusters during the switchover process, if and when you are able to contact them again, you can use the process in Section 8.10, “InnoDB ClusterSet Repair and Rejoin” to repair them and add them back into the InnoDB ClusterSet.