A friend of mine asked me how they could automatically follow and unfollow people on Twitter. But they didn’t want to follow just anyone and everyone. He had a Twitter account which they used for recruiting in a very narrow construction industry. He wanted to find people in the same industry and follow them – hoping they would follow him back and learn about his open jobs. When I joined Twitter back in 2008, I wrote a similar program to automatically follow/unfollow users, but the Twitter API has changed quite a bit since then. So I decided to re-write the program with the latest Perl-Twitter API – Net::Twitter::Lite::WithAPIv1_1.
Before you attempt to use these scripts, you will need to register your application with twitter via apps.twitter.com, and obtain the following:
|
1
2
3
4
|
consumer_key consumer_secret access_token access_token_secret |
When running these types of scripts on Twitter, you have to be careful to not surpass the rate limits that Twitter has established for using the API. I have included a script named rate_limit.pl – which can give you the limits you have for each API-call, and how many calls you have remaining before the limits are reset by Twitter. I have added pauses in the scripts to help prevent you from going over the rate limits (but you will need to check to ensure you don’t surpass them). You are free to modify these scripts (but I won’t be able to help you figure out how to do this.) The rate limits may be found at https://dev.twitter.com/rest/public/rate-limiting. The key with using the Twitter API is to not be too aggressive, or your app will be banned by Twitter. For example, Twitter does not allow bulk follows and unfollows – so having patience is important.
There are several programs involved, and all of them utilize MySQL databases to store the information. A summary of the scripts are as follows:
followers_find.pl – To use this script, you choose a Twitter user that has an audience similar to yours, and then follow their users. For example, if you want to follow cat lovers, you could grab the followers of the Twitter user named @Cat. This script will pull the last 5,000 followers of @Cat, and place those user ID’s into a database named follows_other_users. The script will also save the cursor information, so you can run this script multiple times to obtain a large pool of users, and avoid duplicates. This script stores the account you followed (@Cat) and the user_id of the follower.
friend_lookup.pl – This script takes 100 of the user ID’s from the follows_other_users database, pulls the user’s details from Twitter and inserts this information into the twitter_users database. The user information includes the name, the user ID, number of tweets, how many followers, how many people they are following, time zone and description. You can modify the database and the script to include or omit other pieces of information.
follow_user.pl – This script follows users from the twitter_users database, based upon the percentage of followers/following and the number of tweets (you can change the search criteria). For example, I didn’t want to follow someone who was following 2,000 people but only had 100 followers. I wanted the followers/following ratio to be a little more even. I also wanted to follow people who had posted at least 30 tweets. Even though the followers_find.pl script downloads the information for 5,000 users (at a time), you might only follow a couple hundred of these users who fit your criteria.
friends_follow_check.pl – This script will check to see if a user you followed has followed you back, and if not, then the script will unfollow that user. You will need to specify how many days to give someone to follow you back before you unfollow them. For example: You follow a group of users on 10/05/2015 (the database stores what date you follow someone). You decide to wait five days to see if anyone from this group follows you back. Therefore, on 10/10/2015, you can run this script and change the $date_to_delete variable to 2015-10-05, and the script will unfollow anyone you followed on 2015-10-05 (or prior) who is not following you back.
This diagram shows you the steps for each script and to what database they connect:
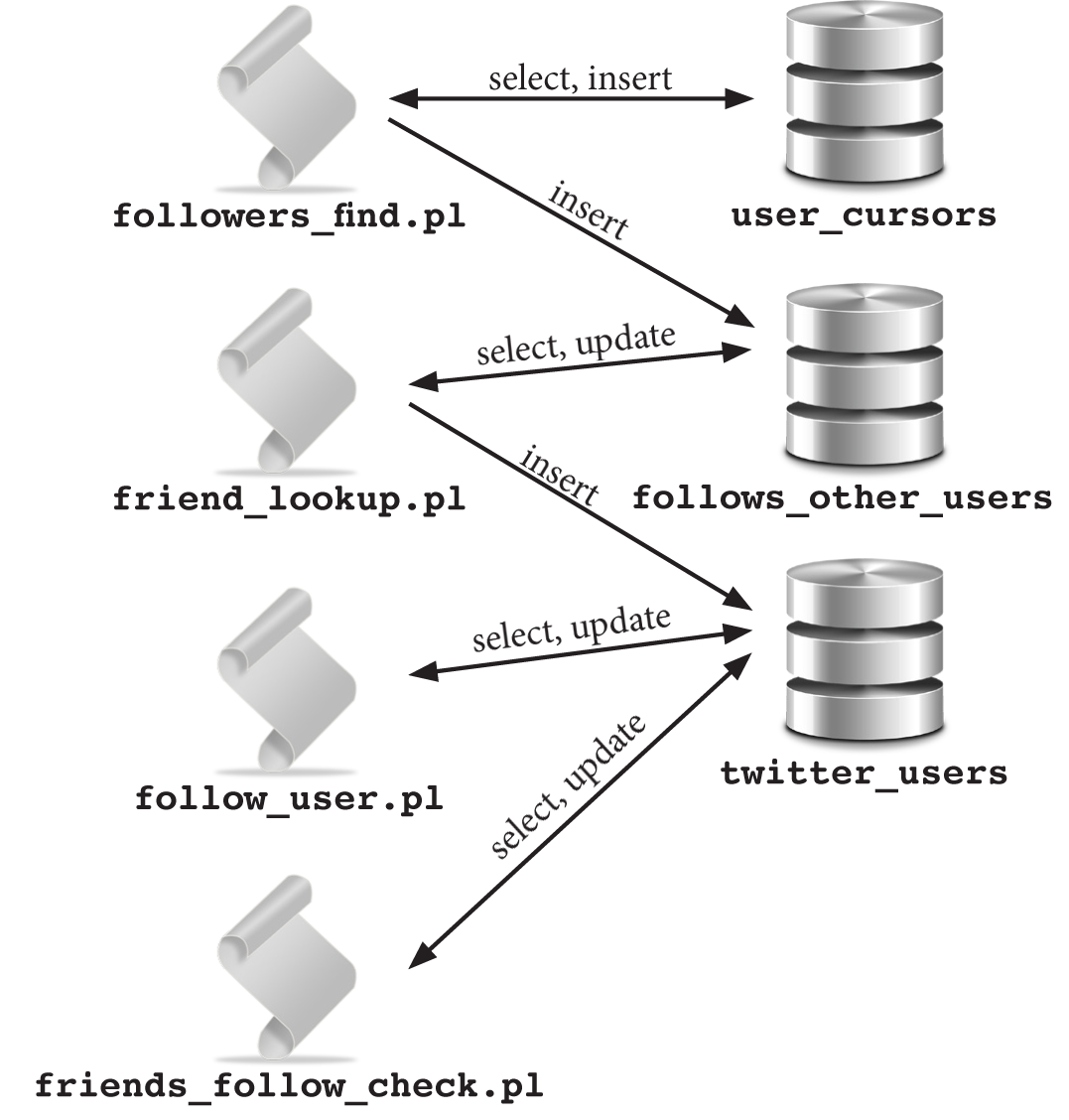
More details on each script:
followers_find.pl – Use this to grab followers of a related Twitter user by providing a value for $user_to_find_followers. This value should be the Twitter user’s name without the “@” symbol – and not their description name. The script will insert 5,000 followers at a time into follows_other_users and insert cursor information in user_cursors.
This script uses the followers_ids API call, which has a limit of 15 every 15 minutes. When you run the rate_limit.pl script, you can see how many calls are remaining:
|
1
2
3
4
5
6
|
'followers' => { '/followers/ids' => { 'limit' => 15, 'remaining' => 14 'reset' => 1445026087, }, |
friend_lookup.pl – Selects users from follows_other_users, gets the user’s details, and then inserts the information into twitter_users. The script can get information on 100 users at a time. Some users may produce an error, and the script will stop. If this happens, just re-run the script. If the script still has an error, delete that user from the database.
This script uses the lookup_users API call, which has a limit of 180 every 15 minutes. When you run the rate_limit.pl script, you can see how many calls are remaining:
|
1
2
3
4
5
|
'/users/lookup' => { 'limit' => 180 'remaining' => 179, 'reset' => 1445028838, }, |
For some reason, when I ran this script, I would get an error on a particular user. I spent a lot of time trying to figure out why the error occurred, but there were too many unknowns as to why the error existed. So, when the script finds a bad user, it updates the follows_other_users database and marks that users with an error (err). You may have to delete a user from the follows_other_users if the script doesn’t automatically mark the user with an error and the script exits immediately after running it.
follow_user.pl – Selects users from twitter_users database and follows them if they meet certain criteria. The script also updates the twitter_users database as to whether or not they were followed, and what date/time they were followed.
This script uses the create_friend API call. The web site does not specify the limit, and the limit does not appear when you run the rate_limit.pl script. I only follow 10-20 new friends an hour – to avoid Twitter’s ban on automatic bulk follow/unfollow.
Before you run this script, you want to be sure that you have enough users in the twitter_users database that fit your search criteria. Use this SQL command to find the number of users available for you to follow: (and feel free to modify the criteria)
|
1 |
select user_id FROM twitter_users where sent_follow_request IS NULL and percent_follow > 90 and percent_follow 30; |
The number of users to follow is set with the $limit variable, and I have it set to 250. This means the script will follow 250 users before quitting. I used a sleep command (a random-length pause between six minutes ($minimum = 360;) and twelve minutes ($maximum = 720;) between following users so Twitter doesn’t think you are a robot. You may adjust these values as well.
friends_follow_check.pl – Selects users you followed from the twitter_users database and unfollows them if they haven’t followed you. It updates twitter_users with the unfollow information.
After you run the follow_user.pl script, you will need to wait a few days to give people time to follow you back. You then will need to change the variable $date_to_delete to be a few days prior to the current date. I usually give people five days to follow me.
You can always change your search criteria to be less restrictive, in order to find more followers. But I have found that a strict search criteria removes most of the spammers.
This script uses the lookup_friendships API call, which has a limit of 15 every 15 minutes. When you run the rate_limit.pl script, you can see how many calls are remaining:
|
1
2
3
4
5
|
'/friendships/lookup' => { 'limit' => 15, 'remaining' => 14 'reset' => 1445031488, }, |
In each of the scripts, you have an option to print out the results from the Twitter API call. You will need to uncomment (remove the #) from these lines:
|
1
2
3
|
# print "---DUMPER START---\n"; # print Dumper $followers_list; # print "---DUMPER END---\n\n"; |
Also, there are print statements that have been commented out as well. Uncomment them if you want to see the output.
Here are the CREATE TABLE statements for each database. Some fields are longer than you would think they should be, but I did this to leave room for special characters which are longer than one character (I had to use decode_utf8 on names and descriptions):
|
1
2
3
4
5
6
7
|
CREATE TABLE `follows_other_users` ( `id` int(11) NOT NULL AUTO_INCREMENT, `user_to_find_followers` varchar(16) DEFAULT NULL, `follower_id` varchar(32) DEFAULT NULL, `looked_up_info` char(3) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=latin1 |
|
1
2
3
4
5
6
7
|
CREATE TABLE 'user_cursors' ( 'id' int(11) NOT NULL AUTO_INCREMENT, 'user_id' varchar(16) DEFAULT NULL, 'next_cursor' varchar(48) DEFAULT NULL, 'previous_cursor' varchar(48) DEFAULT NULL, PRIMARY KEY ('id') ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=latin1 |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
CREATE TABLE 'twitter_users' ( 'id' int(11) NOT NULL AUTO_INCREMENT, 'name' varchar(56) DEFAULT NULL, `screen_name` varchar(32) DEFAULT NULL, 'user_id' varchar(16) DEFAULT NULL, 'sent_follow_request' varchar(3) DEFAULT NULL, 'sent_request_datetime' datetime DEFAULT NULL, 'followed_me' varchar(3) DEFAULT NULL, 'unfollowed_them' varchar(3) DEFAULT NULL, 'statuses_count' int(11) DEFAULT NULL, 'following_count' int(11) DEFAULT NULL, 'followers_count' int(11) DEFAULT NULL, 'percent_follow' int(11) DEFAULT NULL, 'time_zone' varchar(256) DEFAULT NULL, 'description' varchar(4096) DEFAULT NULL, 'creation_datetime' datetime DEFAULT NULL, PRIMARY KEY ('id') ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=latin1 |
And here are the scripts. Remember you need to create your own keys and tokens and insert them into the script for $consumer_key, $consumer_secret, $access_token and $access_token_secret.
In the subroutine ConnectToMySql used in the Perl scripts, I store the MySQL login credentials in a text file one directory below where my Perl script is located. This file – named accessTweets contains this information:
|
1
2
3
4
|
database_name hostname or IP MySQL user name password |
The scripts are also available on GitHub – https://github.com/ScriptingMySQL/PerlFiles.
followers_find.pl
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
|
#!/usr/bin/perl # Updated 2015-10-25 use Net::Twitter::Lite::WithAPIv1_1; use DBI; use DBD::mysql; use Data::Dumper; use Scalar::Util 'blessed'; # ---------------------------------------------------------------------------------- # this has to be near the top - as other parts of the script rely on these figures # ---------------------------------------------------------------------------------- my ($sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst) = localtime time; $year = $year + 1900; $mon = $mon + 1; # add a zero if the value is less than 10 if ($sec < 10) { $sec = "0$sec"; } if ($min < 10) { $min = "0$min"; } if ($hour < 10) { $hour = "0$hour"; } if ($mday < 10) { $mday = "0$mday"; } if ($mon < 10) { $mon = "0$mon"; } if ($year < 10) { $year = "0$year"; } if ($wday < 10) { $wday = "0$wday"; } if ($yday < 10) { $yday = "0$yday"; } if ($isdst new( traits => [qw/API::RESTv1_1/], consumer_key => "$consumer_key", consumer_secret => "$consumer_secret", access_token => "$access_token", access_token_secret => "access_token_secret", apiurl => 'http://api.twitter.com/1.1', ssl => 1 ); $count=1; # twitter user name without the @ $user_to_find_followers = "Cat"; $dbh = ConnectToMySql($Database); $query = "select user_id, next_cursor FROM user_cursorswhere user_id = '$user_to_find_followers' order by id desc limit 1"; $sth = $dbh->prepare($query); $sth->execute(); print "\n$query\n"; $count_users = 0; # print "name | friends_count | followers_count | statuses_count | percent_follow\% |$time_zone | description | creation_datetime\n"; # loop through our results - one tweet at a time while (@data = $sth->fetchrow_array()) { $cursor = $data[1]; if ($cursor == 0) { $cursor = "-1"; } } print "Starting at cursor: $data[1]\n"; # Use the optional cursor parameter to retrieve IDs in pages of 5000. When the cursor parameter is used, # the return value is a reference to a hash with keys previous_cursor, next_cursor, and ids. # The value of ids is a reference to an array of IDS of the user's followers. # Set the optional cursor parameter to -1 to get the first page of IDs. # Set it to the prior return's value of previous_cursor or next_cursor to page forward or backwards. # When there are no prior pages, the value of previous_cursor will be 0. # When there are no subsequent pages, the value of next_cursor will be 0. eval { my $followers_list = $nt->followers_ids({ screen_name => "$user_to_find_followers", cursor => "$cursor", }); # count => 1 # print "---DUMPER START---\n"; # print Dumper $followers_list; # print "---DUMPER END---\n\n"; $next_cursor = $followers_list->{next_cursor_str}; $previous_cursor = $followers_list->{previous_cursor_str}; print "next_cursor $next_cursor - previous_cursor $previous_cursor \n"; for my $status2 ( @{$followers_list->{ids}} ) { # print "$count $status $next_cursor\n"; $follower_id = $status2; # uncomment to watch as it prints each user #print "$count $user_to_find_followers $follower_id\n"; $dbh = ConnectToMySql($Database); $query = "insert into follows_other_users(user_to_find_followers, follower_id) values ('$user_to_find_followers','$follower_id')"; #print "\n $query\n"; $sth = $dbh->prepare($query); $sth->execute(); #sleep 1; $count++; # end for my $status } # end eval }; if ( my $err = $@ ) { die $@ unless blessed $err && $err->isa('Net::Twitter::Lite::Error'); warn "HTTP Response Code: ", $err->code, "\n", "HTTP Message......: ", $err->message, "\n", "Twitter error.....: ", $err->error, "\n"; } # put this into a database in case you want to search for more of their followers print "\n$user_to_find_followers $next_cursor $previous_cursor\n"; $user_id = $user_to_find_followers; $dbh = ConnectToMySql($Database); $query = "insert into user_cursors(user_id, next_cursor, previous_cursor) values ('$user_id','$next_cursor','$previous_cursor')"; print "\n $query\n"; $sth = $dbh->prepare($query); $sth->execute(); # ---------------------------------------------------------------------------------- # this has to be near the top - as other parts of the script rely on these figures # ---------------------------------------------------------------------------------- my ($sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst) = localtime time; $year = $year + 1900; $mon = $mon + 1; # add a zero if the value is less than 10 if ($sec < 10) { $sec = "0$sec"; } if ($min < 10) { $min = "0$min"; } if ($hour < 10) { $hour = "0$hour"; } if ($mday < 10) { $mday = "0$mday"; } if ($mon < 10) { $mon = "0$mon"; } if ($year < 10) { $year = "0$year"; } if ($wday < 10) { $wday = "0$wday"; } if ($yday < 10) { $yday = "0$yday"; } if ($isdst < 10) { $isdst = "0$isdst"; } $DateTime = "$year-$mon-$mday $hour:$min:$sec"; # ---------------------------------------------------------------------------------- print "Finished importing - $DateTime....\n"; print "\n----------------------------------------------------------------------------\n"; #---------------------------------------------------------------------- sub ConnectToMySql { #---------------------------------------------------------------------- my ($db) = @_; open(PW, "<..\/accessTweets") || die "Can't access login credentials"; my $db= ; my $host= ; my $userid= ; my $passwd= ; chomp($db); chomp($host); chomp($userid); chomp($passwd); my $connectionInfo="dbi:mysql:$db;$host:3306"; close(PW); # make connection to database my $l_dbh = DBI->connect($connectionInfo,$userid,$passwd); return $l_dbh; } exit; |
friend_lookup.pl
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
|
#!/usr/bin/perl # Updated 2015-10-25 use Net::Twitter::Lite::WithAPIv1_1; use DBI; use DBD::mysql; use Data::Dumper; use Scalar::Util 'blessed'; use Encode; # ---------------------------------------------------------------------------- # get the relationship between my user name and another user name to see # if they are following me or if I am following them # ---------------------------------------------------------------------------- $number = 1; # you are allowed 180 of these lookups every 15 minutes # with a 15 second pause at the end of each one, you won't # go over the limit while ($number new( traits => [qw/API::RESTv1_1/], consumer_key => "$consumer_key", consumer_secret => "$consumer_secret", access_token => "$access_token", access_token_secret => "access_token_secret", apiurl => 'http://api.twitter.com/1.1', ssl => 1 ); open(OUT, ">dumper_out.txt") || die "Can't redirect stdout"; $dbh = ConnectToMySql($Database); $query = "select follower_id, user_to_find_followers FROM follows_other_users where looked_up_info IS NULL limit 100"; # run to see if you can debug why some users get an error #$query = "select follower_id, user_to_find_followers FROM follows_other_users where looked_up_info = 'err' limit 100"; $sth = $dbh->prepare($query); $sth->execute(); print "\n$query\n"; $count_users = 0; # print "name | friends_count | followers_count | statuses_count | percent_follow\% |$time_zone | description | creation_datetime\n"; # loop through our results - one tweet at a time while (@data = $sth->fetchrow_array()) { print "$data[0] "; $user_id = $data[0]; $user_to_find_followers = $data[1]; if (length($data[0]) 0) { $users_to_get = "$users_to_get, $user_id"; push(@data2, "$user_id"); } else { $users_to_get = "$user_id"; push(@data2, "$user_id"); } $count_users++; # end - while (@data = $sth->fetchrow_array()) { } #print "$users_to_get\n"; $count = 1; #while (@data2) { print "--------------------------------------------------------------------------------------------------\n"; eval { my $user_info = $nt->lookup_users({ user_id => [ "$users_to_get" ] }); print OUT "---DUMPER START---\n"; print OUT Dumper $user_info; print OUT "---DUMPER END---\n\n"; if ( my $err = $@ ) { die $@ unless blessed $err && $err->isa('Net::Twitter::Lite::Error'); warn "\n - HTTP Response Code: ", $err->code, "\n", "\n - HTTP Message......: ", $err->message, "\n", "\n - Twitter error.....: ", $err->error, "\n"; } for my $status ( @$user_info ) { if (length($status->{name}) {name}; $name =~ s/[^[:ascii:]]//g; $name =~ s/[^!-~\s]//g; $name = decode_utf8( $name ); $name =~ s/\'/\^/g; print "Working on $name - "; $user_id = $status->{id}; $following_count = $status->{friends_count}; $followers_count = $status->{followers_count}; $statuses_count = $status->{statuses_count}; $time_zone = $status->{time_zone}; $screen_name = $status->{screen_name}; $screen_name =~ s/[^[:ascii:]]//g; $screen_name = decode_utf8( $screen_name ); $screen_name =~ s/[^a-zA-Z0-9 _^-]//g; $screen_name =~ s/[^!-~\s]//g; $description = $status->{description}; if (length($description) 'Wed Nov 09 19:38:46 +0000 2011', $created_at = $status->{created_at}; @creation_date_array = split(" ",$created_at); $creation_date_month = $creation_date_array[1]; if ($creation_date_month =~ "Jan") { $creation_date_month = "01"} if ($creation_date_month =~ "Feb") { $creation_date_month = "02"} if ($creation_date_month =~ "Mar") { $creation_date_month = "03"} if ($creation_date_month =~ "Apr") { $creation_date_month = "04"} if ($creation_date_month =~ "May") { $creation_date_month = "05"} if ($creation_date_month =~ "Jun") { $creation_date_month = "06"} if ($creation_date_month =~ "Jul") { $creation_date_month = "07"} if ($creation_date_month =~ "Aug") { $creation_date_month = "08"} if ($creation_date_month =~ "Sep") { $creation_date_month = "09"} if ($creation_date_month =~ "Oct") { $creation_date_month = "10"} if ($creation_date_month =~ "Nov") { $creation_date_month = "11"} if ($creation_date_month =~ "Dec") { $creation_date_month = "12"} $creation_date_day_of_month = $creation_date_array[2]; $creation_date_year = $creation_date_array[5]; $creation_date_time = $creation_date_array[3]; $creation_datetime = "$creation_date_year-$creation_date_month-$creation_date_day_of_month $creation_date_time"; # had to add this as the percentage formula below would fail if ($following_count < 1) { $following_count = 1; } if ($followers_count prepare($query); $sth->execute(); $dbh2 = ConnectToMySql($Database); $query2 = "update follows_other_users set looked_up_info = 'yes' where follower_id = '$user_id'"; #print " $count ---- $query2\n"; print "--------------------------------------------------------------------------------------------------\n"; $sth2 = $dbh2->prepare($query2); $sth2->execute(); #sleep 1; $count++; } # end - eval }; #599 $number++; # if we didn't grab all 100 users, change the last user's status to error #print "Count $count\n"; if ($count prepare($query3); $sth3->execute(); exit; } # if there aren't any more users, quit if (length($data[0]) fetchrow_array()) { #} #---------------------------------------------------------------------- sub ConnectToMySql { #---------------------------------------------------------------------- my ($db) = @_; open(PW, "<..\/accessTweets") || die "Can't access login credentials"; my $db= ; my $host= ; my $userid= ; my $passwd= ; chomp($db); chomp($host); chomp($userid); chomp($passwd); my $connectionInfo="dbi:mysql:$db;$host:3306"; close(PW); # make connection to database my $l_dbh = DBI->connect($connectionInfo,$userid,$passwd); return $l_dbh; } close(OUT); exit; |
follow_user.pl
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
|
#!/usr/bin/perl # Updated 2015-10-25 use Net::Twitter::Lite::WithAPIv1_1; use DBI; use DBD::mysql; use Data::Dumper; use Scalar::Util 'blessed'; # ---------------------------------------------------------------------------- # follow users from database # ---------------------------------------------------------------------------- # Credentials for your twitter application - blog my $nt = Net::Twitter::Lite::WithAPIv1_1->new( traits => [qw/API::RESTv1_1/], consumer_key => "$consumer_key", consumer_secret => "$consumer_secret", access_token => "$access_token", access_token_secret => "access_token_secret", apiurl => 'http://api.twitter.com/1.1', ssl => 1 ); # find the stats and info for the following users $limit = 250; $percent_follow_minimum = 80; $percent_follow_maximum = 140; $statuses_count_minimum = 30; $dbh = ConnectToMySql($Database); $query = "select user_id FROM twitter_users where sent_follow_request IS NULL and percent_follow > $percent_follow_minimum and percent_follow $statuses_count_minimum limit $limit"; $sth = $dbh->prepare($query); $sth->execute(); print "\n$query\n\n"; $count_users = 1; # 107 following 114 followers # loop through our results - one tweet at a time while (@data = $sth->fetchrow_array()) { # ---------------------------------------------------------------------------------- # this has to be near the top - as other parts of the script rely on these figures # ---------------------------------------------------------------------------------- my ($sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst) = localtime time; $year = $year + 1900; $mon = $mon + 1; # add a zero if the value is less than 10 if ($sec < 10) { $sec = "0$sec"; } if ($min < 10) { $min = "0$min"; } if ($hour < 10) { $hour = "0$hour"; } if ($mday < 10) { $mday = "0$mday"; } if ($mon < 10) { $mon = "0$mon"; } if ($year < 10) { $year = "0$year"; } if ($wday < 10) { $wday = "0$wday"; } if ($yday < 10) { $yday = "0$yday"; } if ($isdst create_friend({ user_id => "$user_id" }); # print "---DUMPER START---\n"; # print Dumper $friend; # print "---DUMPER END---\n\n"; if ( my $err = $@ ) { die $@ unless blessed $err && $err->isa('Net::Twitter::Lite::Error'); warn "\n - HTTP Response Code: ", $err->code, "\n", "\n - HTTP Message......: ", $err->message, "\n", "\n - Twitter error.....: ", $err->error, "\n"; # end if }; # end - eval }; $dbh2 = ConnectToMySql($Database); $query2 = "update twitter_users SET sent_follow_request = 'yes', sent_request_datetime = '$DateTime' where user_id = '$user_id'"; #print " $query2\n"; #print " database updated.\n" $sth2 = $dbh2->prepare($query2); $sth2->execute(); # pause for a random time so twitter doesn't think you are a robot # minimum and maximum time in seconds to sleep $minimum = 360; $maximum = 720; $random_sleep = int($minimum + rand($maximum - $minimum)); print " - sleeping for $random_sleep seconds\n"; sleep $random_sleep; $count_users++; # end - while (@data = $sth->fetchrow_array()) }; exit; #---------------------------------------------------------------------- sub ConnectToMySql { #---------------------------------------------------------------------- my ($db) = @_; open(PW, "<..\/accessTweets") || die "Can't access login credentials"; my $db= ; my $host= ; my $userid= ; my $passwd= ; chomp($db); chomp($host); chomp($userid); chomp($passwd); my $connectionInfo="dbi:mysql:$db;$host:3306"; close(PW); # make connection to database my $l_dbh = DBI->connect($connectionInfo,$userid,$passwd); return $l_dbh; } exit; |
friends_follow_check.pl
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
|
#!/usr/bin/perl # Updated 2015-10-25 use Net::Twitter::Lite::WithAPIv1_1; use DBI; use DBD::mysql; use Data::Dumper; use Scalar::Util 'blessed'; # ---------------------------------------------------------------------------- # see if a user follows me and/or if i follow them # ---------------------------------------------------------------------------- # Credentials for your twitter application - blog my $nt = Net::Twitter::Lite::WithAPIv1_1->new( traits => [qw/API::RESTv1_1/], consumer_key => "$consumer_key", consumer_secret => "$consumer_secret", access_token => "$access_token", access_token_secret => "access_token_secret", apiurl => 'http://api.twitter.com/1.1', ssl => 1 ); # limit must be 100 or less $limit = 100; # how many days do you want to wait until you unfriend someone? $date_to_delete = "2015-10-21"; # find the stats and info for the following users $dbh = ConnectToMySql($Database); $query = "select user_id, sent_request_datetime FROM twitter_users where sent_follow_request = 'yes' and sent_request_datetime prepare($query); $sth->execute(); print "\n$query\n\n\n"; $count_users = 0; $count = 0; # loop through our results - one tweet at a time while (@data = $sth->fetchrow_array()) { $user_id = $data[0]; $sent_request_datetime{$user_id} = $data[1]; if ($count_users > 0) { $users_to_get = "$users_to_get, $user_id"; push(@data2, "$user_id"); } else { $users_to_get = "$user_id"; push(@data2, "$user_id"); } $count_users++; # end - while } print "$users_to_get\n\n"; #exit; eval { my $friend = $nt->lookup_friendships({ user_id => "$users_to_get" }); # print "---DUMPER START---\n"; # print Dumper $friend; # print "---DUMPER END---\n\n"; if ( my $err = $@ ) { die $@ unless blessed $err && $err->isa('Net::Twitter::Lite::Error'); warn "\n - HTTP Response Code: ", $err->code, "\n", "\n - HTTP Message......: ", $err->message, "\n", "\n - Twitter error.....: ", $err->error, "\n"; # end if }; for $data_list ( @$friend ) { $count++; for $role ( keys %$data_list ) { if ($role =~ "id_str") { # since the connection info is an array, find the values $user_id_str = $data_list->{$role}; $user_id = $user_id_str; # get user_id #print "$user_id_str - "; # once you have the status of the connection and the user_id # you can check to see if they are following you or not if ($status_friend =~ "followed_by") { print "*************\nThis person $user_id_str follows you. - $sent_request_datetime"; print "Status: $status_connection1 $status_connection2\n*************\n"; $dbh2 = ConnectToMySql($Database); $query2 = "update twitter_users set followed_me = 'yes' where user_id = '$user_id_str'"; $sth2 = $dbh2->prepare($query2); $sth2->execute(); print "\n$query2\n"; print "########\n $count of $limit sleeping....\n########\n"; sleep 155; } else { print "This person $user_id_str DOES NOT follow you. - $sent_request_datetime{$user_id}\n"; print "Status: $status_connection1 $status_connection2\n"; eval { my $friend = $nt->destroy_friend({ user_id => "$user_id" }); # print "---DUMPER START---\n"; # print Dumper $friend; # print "---DUMPER END---\n\n"; if ( my $err = $@ ) { die $@ unless blessed $err && $err->isa('Net::Twitter::Lite::Error'); warn "\n - HTTP Response Code: ", $err->code, "\n", "\n - HTTP Message......: ", $err->message, "\n", "\n - Twitter error.....: ", $err->error, "\n"; # end if }; # end - eval }; $dbh3 = ConnectToMySql($Database); $query3 = "update twitter_users set followed_me = 'no' where user_id = '$user_id_str'"; $sth3 = $dbh3->prepare($query3); $sth3->execute(); print "\n$query3\n"; $dbh4 = ConnectToMySql($Database); $query4 = "update twitter_users set unfollowed_them = 'yes' where user_id = '$user_id_str'"; $sth4 = $dbh4->prepare($query4); $sth4->execute(); print "\n$query4\n"; print "########\n $count of $limit sleeping "; # pause for a random time so twitter doesn't think you are a robot # minimum and maximum time in seconds to sleep $minimum = 60; $maximum = 120; $random_sleep = int($minimum + rand($maximum - $minimum)); print " for $random_sleep seconds\n"; sleep $random_sleep; # unfollow this user } # end - if ($role =~ "id_str") } # check the status of the connection if ($role =~ "connections") { # since the connection info is an array, find the values $status_connection1 = $data_list->{$role}[0]; $status_connection2 = $data_list->{$role}[1]; $status_connection3 = $data_list->{$role}[2]; $status_friend = "$status_connection1 $status_connection2 $status_connection3"; # if ($role =~ "connections") } # for $role ( keys %$data_list ) { } # end - for $data_list ( @$friend ) { } # end - eval }; # end - while #} print "\n\n"; exit; #---------------------------------------------------------------------- sub ConnectToMySql { #---------------------------------------------------------------------- my ($db) = @_; open(PW, "<..\/accessTweets") || die "Can't access login credentials"; my $db= ; my $host= ; my $userid= ; my $passwd= ; chomp($db); chomp($host); chomp($userid); chomp($passwd); my $connectionInfo="dbi:mysql:$db;$host:3306"; close(PW); # make connection to database my $l_dbh = DBI->connect($connectionInfo,$userid,$passwd); return $l_dbh; } |
rate_limits.pl
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
#!/usr/bin/perl # Updated 2015-10-25 use Net::Twitter::Lite::WithAPIv1_1; use DBI; use DBD::mysql; use Data::Dumper; use Scalar::Util 'blessed'; #use Encode; use JSON; # ---------------------------------------------------------------------------- # get the relationship between my user name and another user name to see # if they are following me or if I am following them # ---------------------------------------------------------------------------- # Credentials for your twitter application - blog my $nt = Net::Twitter::Lite::WithAPIv1_1->new( traits => [qw/API::RESTv1_1/], consumer_key => "$consumer_key", consumer_secret => "$consumer_secret", access_token => "$access_token", access_token_secret => "access_token_secret", apiurl => 'http://api.twitter.com/1.1', ssl => 1 ); eval { my $user_info = $nt->rate_limit_status; # print "---DUMPER START---\n"; print Dumper $user_info; # print "---DUMPER END---\n\n"; if ( my $err = $@ ) { die $@ unless blessed $err && $err->isa('Net::Twitter::Lite::Error'); warn "\n - HTTP Response Code: ", $err->code, "\n", "\n - HTTP Message......: ", $err->message, "\n", "\n - Twitter error.....: ", $err->error, "\n"; # end if }; $friendships_show_remaining = $user_info=>{friendships}; print "friendships_show_remaining $friendships_show_remaining\n"; # print Dumper $friendships_show_remaining; for my $item( @{$user_info_data->{friendships}} ){ print $item->{'/friendships/show'} . "\n"; }; exit; |
I am not the best Perl programmer, nor am I an expert at the Twitter API, so there may be a better/easier way to do this. Good luck with the scripts and let me know how they work for you. And follow me on Twitter at ScriptingMySQL and TonyDarnell.
 |
Tony Darnell is a Principal Sales Consultant for MySQL, a division of Oracle, Inc. MySQL is the world’s most popular open-source database program. Tony may be reached at info [at] ScriptingMySQL.com and on LinkedIn. |
 |
Tony is the author of Twenty Forty-Four: The League of Patriots
Visit http://2044thebook.com for more information. |