The recent “Unified Data Dictionary Lab Release” quietly delivered an important change to the MySQL server with InnoDB engine: the “InnoDB System Tables” are now officially “decommissioned”. And InnoDB is now deriving its metadata from the new “Transactional Data Dictionary” delivered in 8.0.0 DMR. In this way, we are truly using a “Unified Data Dictionary” shared with other MySQL Storage Engines.
Although the old “InnoDB System Tables” are not yet completely removed from the database, they are only playing a passive and verification role. All InnoDB metadata is now linked with the new “Transactional Data Dictionary”.
There were two earlier posts by Geir and Staale explained the motivation and previous work for the overall project. I will focus on the work done in this Lab Release:
1. Removal the dependency on InnoDB System Tables
As you can see from the following graph, the major achievement for the Lab Release is InnoDB’s “In-Memory Metadata” is now derived its data from server “In-Memory Metadata” instead of InnoDB’s own System tables.
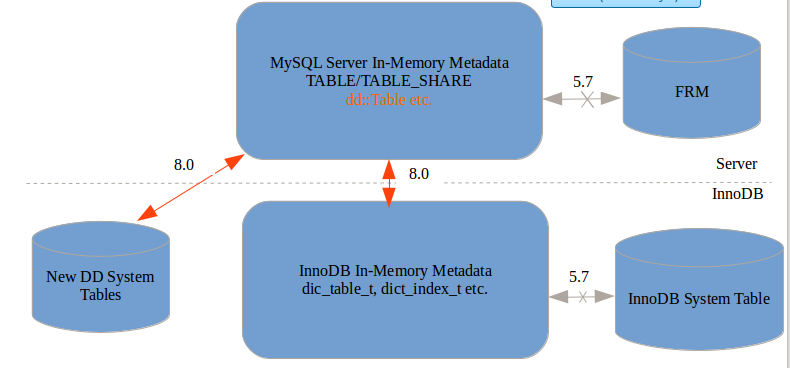
In another word, the persisting of metadata is now coordinated by MySQL server, rather than InnoDB.
There are a few benefits for this change:
1) Simpler to maintain
In 5.7 and earlier releases, MySQL server with InnoDB engine have both “.frm” and “InnoDB System Tables” maintaining 2 sets of metadata for the same objects. This results difficulty in maintaining absolute consistency between the two. With previous “Transactional Data Dictionary” changes, the frm is removed, replaced by a new set of “DD Dictionary Tables” stored in InnoDB Engine. And now, with this LAB release, InnoDB removes the dependency of its own system tables, leaves the single/unified Dictioinary Tables in charge (as shown in above graph).
2) Making atomic DDL possible
Because we have single set of Transactional Data Dictionary(DD) Tables, it makes Atomic DDL (or later transactional DDL) possible. Once the DD table changes are tied along with physical file changes, we will have Atomic DDL.
3) Improved concurrency
InnoDB used to have a set of “coarce” global mutex/latches to maintain the correctness of it own metadata. In addition, to update the old InnoDB System Tables, InnoDB uses its own parser, which is “non-reentrant”, and uses a global mutex to guard the update. This means at a time, only one session can update the system tables. This greatly reduces the concurrency of DDL, and also could impact on other InnoDB background activity, such as InnoDB Purge, statistics updates etc. Now, along with the removal the dependency of InnoDB system tables, it paves way for us to remove/reduce the usage of such global mutex/latches, thus improves concurrency.
2. All data dictionary tables are put in a single tablespaces.
Another change in this LAB release is that all the “new data dictionary tables” are put in a single data dictionary tablespace named as “mysql”:
CREATE TABLESPACE mysql ADD DATAFILE ‘mysql.ibd’;
Since all dictionary tables are in the same tablespace, all root pages for all Dictionary Tables are hard coded, so easy to load them up (note the hard code page number value could differ for different pagesize server).
3. InnoDB specific metadata are updated and persisted through “se_private_data” field in Data Dictionary Tables.
As mentioned, the “new Data Dictionary Tables” now persist metadata for all MySQL Storage Engines. But there are some Storage Engine specific data that cannot be generalized across. For these data, they will be persisted through a Text column called “se_private_data” in each major Data Dictionary Tables. For example, the InnoDB internal Index ID, Index Root Page No, Index modification trx_id are all stored in se_private_data of “mysql.indexes”. Following section will discuss more about how and when this engine specific data is filled and fetched in InnoDB
4. Metadata Interfaces between InnoDB and Server objects:
Although the old InnoDB System Tables are “taken out of action”, the InnoDB in-memory metadata (such as dict_table_t etc.) is kept largely unchanged. This allows us to keep the overall change in InnoDB to minimum.
The InnoDB in-memory metadata objects used to be instantiated by reading their content from InnoDB System Tables. With the removal of InnoDB System Tables, InnoDB creates its in-memory metadata by interpretting information from server in-memory metadata, more specifically, the dd::Table, dd::Index, dd::Partition classes as well the traditional TABLE etc.. For example, the InnoDB dict_table_t derive its data from following sources:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
dict_table_t: dict_table_t::id <== dd::Table::se_private_id() dict_table_t::n_cols <== TABLE_SHARE::fields dict_table_t::cols <== TABLE::field[] dict_table_t::flags <== TABLE_SHARE::row_type, TABLE_SHARE::key_block_size and TABLE_SHARE::key_block_size dict_table_t::flags2 DICT_TF2_TEMPORARY <== dd::Table::is_persistent() DICT_HAS_DOC_ID <== Look for FTS_DOC_ID in with dd_find_column() in dd::TABLE, and check if it is hidden DICT_TF2_FTS <== Look for Fulltext index in dd::TABLE (dd::Index::type() == dd::Index::IT_FULLTEXT) DICT_TF2_DISCARD <== dd::Table::se_private_data (dd_table_discard) DICT_TF2_ENCRYPTION<== dd::Table::options("encrypt_type") dict_table_t::data_dir_path <== dd::Table::se_private_data (data_directory to indicate if there is a user specified data directory) dict_table_t::space <== dd::Tablespace::se_praivate_data dict_table_t::autoinc <== dd::Table::se_private_data (autoinc) |
The similar mapping is done for all other InnoDB in-memory metadata structures.
Of course, the metadata information flow is not always from server to SE, there is also information that SE feeds back to server to persist, mostly during the DDL operations, and for the se_private_data field. The “communication bridge” is server objects such as dd::Table objects etc. For example, a create table is can include following actions:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
Create table 1) After successfully creating the table, start to write back the metadata 2) Check in which tablespace the table resides 2.1) If it's innodb-file-per-table, create the dd::Tablespace object, exclusively lock the tablespace mdl; write back the tablespace metadata to dd::Tablespace::se_private_data, fill in the dd::Tablespace_files with the tablespace file name 2.2) If the table resides in innodb_system tablespace, just mark the global tablespace_id with the one of innodb_system id (1). 2.3) If the table resides in a shared tablespace, it's possible to get the tablespace and verify it exists, throw error if not exists 3) Write back dict_table_t::id to dd::Table::se_private_id 4) Write back dd::Table::options(), by getting data from dict_table_t object 5) Write back dd::Table::se_private_data and dd::Index::se_private_data, by getting data from dict_table_t and dict_index_t objects |
Above is done similarly for each index and other Data structures. So as you can see, the InnoDB specific metadata generated during DDL will be uploaded to server through “dd::*” objects. And server will then presist these info to new Data Dictionary Tables.
5. MDL lock table by InnoDB
MDL stands for “MetaData Locking”. It is a table level lock used by MySQL server to synchronize DDLs and DMLs. For table manipulating DDLs, server will take exclusive MDL, and for DMLs, server will take shared MDL lock. This is to prevent table being dropped or changed while a DML is going on.
The MDL used to be acquired and released by MySQL server layer. So it does not cover table DML operations performed by InnoDB with its background threads for purge etc. Thus, InnoDB needs to use elaborated scheme and global latches to prevent table being changed/dropped. With this LAB release, InnoDB can now also request MDL locks. This allows InnoDB to eliminate the need to use its global latches for synchronization.
Since MDL is table specific, it is a great improvement over InnoDB global latches in terms of concurrency. Global latch and mutex could block DDLs for all tables. But After we switch to table specific MDL, only the DDL on the affected table is affected, and all other DDL and create tables can proceed as usual, thus greatly improve the concurrency.
We did not remove the “dict_operation _lock” completely yet, since the MDL for FK tables are still work in progress. So we would see a even great improve in DDL concurrency once global latches like dict_operation_lock are either removed or reduced in usage in the foreseeable future.
6. InnoDB hidden columns, hidden indexes and hidden tables
InnoDB traditionally adds hidden columns to its table, such as DB_ROW_ID, DB_TRX_ID etc.. These columns used to be stored in InnoDB only, now they are stored in Data Dictionary tables such as”mysql.columns”. Thus, it is now “aware” by server and be visible to user through “show extended columns” clause:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
mysql> create table test.test1(a int); Query OK, 0 rows affected (0.06 sec) mysql> show extended columns in test.test1; +-------------+---------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------------+---------+------+-----+---------+-------+ | a | int(11) | YES | | NULL | | | DB_ROW_ID | | NO | | NULL | | | DB_TRX_ID | | NO | | NULL | | | DB_ROLL_PTR | | NO | | NULL | | +-------------+---------+------+-----+---------+-------+ 4 rows in set (0.01 sec) |
Similarly the “hidden” index (such as the default Primary Index created on table) is also stored in mysql.indexes and can be seen in “show extended index” call:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
mysql> create table test.test1(a int); Query OK, 0 rows affected (0.06 sec) mysql> show extended index in test.test1; +-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | +-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+ | test1 | 0 | PRIMARY | 1 | DB_ROW_ID | A | NULL | NULL | NULL | | BTREE | | | YES | | test1 | 0 | PRIMARY | 2 | DB_TRX_ID | A | NULL | NULL | NULL | | BTREE | | | YES | | test1 | 0 | PRIMARY | 3 | DB_ROLL_PTR | A | NULL | NULL | NULL | | BTREE | | | YES | | test1 | 0 | PRIMARY | 4 | a | A | NULL | NULL | NULL | YES | BTREE | | | YES | +-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+ 4 rows in set (0.01 sec) mysql> show index in test.test1; Empty set (0.01 sec) |
InnoDB also has hidden tables for Fulltext Indexes. In general, it is still largely hidden from user, but their information are stored in Dictionary Tables as well and can be made visible in the future if needed:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
mysql> create table test.test2(a text, fulltext index(a)); Query OK, 0 rows affected (0.06 sec) mysql> select name from mysql.tables where name like -> "fts_%"; +-----------------------------------------------+ | name | +-----------------------------------------------+ | fts_000000000000004f_0000000000000095_index_1 | | fts_000000000000004f_0000000000000095_index_2 | | fts_000000000000004f_0000000000000095_index_3 | | fts_000000000000004f_0000000000000095_index_4 | | fts_000000000000004f_0000000000000095_index_5 | | fts_000000000000004f_0000000000000095_index_6 | | fts_000000000000004f_being_deleted | | fts_000000000000004f_being_deleted_cache | | fts_000000000000004f_config | | fts_000000000000004f_deleted | | fts_000000000000004f_deleted_cache | +-----------------------------------------------+ 11 rows in set (0.01 sec) |
So in another word, these “hidden” columns, indexes and tables’ metadata are now all stored in new Data Dictionary Tables. This gains them the capablility of being visible if needed, especially some FTS AUX tables, we could allow them to be “selectable” and making dumping a specific FTS index possible.
7. Partition Table changes
In this LAB release, we also take the chance to move InnoDB partition table further in its road to be truly “native” to InnoDB. Before, there are some DDL operations on the partitioned tables are not managed by InnoDB, instead, they were done by server. These DDL operations like ‘ALTER TABLE … PARTITION …’ include:
1) ADD PARTITION
2) DROP PARTITION(RANGE/LIST PARITTION only)
3) COALESCE PARTITION(HASH/KEY PARTITION only)
4) REORGANIZE PARTITION
5) REBUILD PARTITION
6) EXCHANGE PARTITION
With this LAB release, InnoDB partitioning is truely “native” to InnoDB and all these DDL operations are performed by InnoDB storage engine through the handler APIs. No more dependency on server any more. However, there are no functional changes other than making them “native”, so these DDL are still not online. However, InnoDB now can manipulate all the affected partitions itself and this paves the way for the future improvement, such as online partition DDL and fast rows reorganization between partitions, etc.
Another change is that now ‘ALGORITHM = …, LOCK = …’ is supported for above 1) to 5) operations. Following combinations are supported:
1. ALGORITHM=COPY, LOCK=DEFAULT/SHARED/LOCK.
2. ALGORITHM=INPLACE, LOCK=DEFAULT/SHARED/LOCK, this is for operations which require copying data between partitions, like ‘REORGANIZE PARTITION’, ‘ADD PARTITION’ for HASH and KEY partitions, ‘COALESCE PARTITION’ and ‘REBUILD PARTITION’.
3. ALGORITHM=INPLACE, LOCK=NONE, this is for ‘ADD PARTITION’ for RANGE and LIST partitions, and ‘DROP PARTITION’.
Any invalid combination would result in the same error messages as normal ALTER TABLE operations. For example, ALGORITHM=COPY, LOCK=NONE is not allowed, and ‘LOCK=NONE is not supported. Reason: COPY algorithm requires a lock. Try LOCK=SHARED.’
8. Upgrade
This LAB release supports upgrading MySQL databases created in 5.7.Eventually, we will support upgrade all MySQL databases created in any release, the prerequisite would be they upgrade to latest 5.7 first.
During upgrade, the new Data Dictionary tablespace and tables will be created. And Server creates the tables based on .frm in old 5.7 server. Then it scans old InnoDB system tables and uploads InnoDB special metadata to “se_private_data” field of each new Data Dictionary Table, as well as creating proper tablespace info for these tables.
9. What is coming:
a) Completely remove all InnoDB System Tables
Although the InnoDB system tables are put out of actions, they are still present, recording any DDL operations, simply for the verification purpose. In order to make the DDL atomic, we will cut this last link to them and remove once for all.
b) Support Atomic DDL
As discussed in earlier section, the 5.7 metadta can often get out of sync between server and InnoDB if there is crash during DDL. Now, with single transactional persisted Data Dictionary tables, it is possible to make all DDL atomic. This means we need to link the Data Dictionary table updates along with any file and actual data operation (delete ibd, drop index etc.). With this additional linkage, we would be able to support truly atomic DDLs.
c) MDL on FK tables
Also as we mentioned above, DDL and DML synchronization are now using Metadata locking (MDL), with one exception, the FK related tables. For FK tables with cascading update/delete relations, an update or delete on one table could cascade to parent table. In this way, the update/delete of the child table should not only MDL lock the child table but also the parent table. This feature is not included in ths LAB release but work is underway.
d) Simplified metadata synchronization
With above a) and c), several InnoDB global latches and mutexes (dict_operation_lock or dict_sys mutex) could either be elminated or reduce their scope of usage. Thus improve the DDL concurrency, and possible have positive impact on DML concurrency as well.
Summary:
This LAB release is a big step forward for the overall Transactional Data Dictionary project. We officially cut our reliance on InnoDB System Tables for the metadata management, and start to use a “unified Data Dictionary”. This also paves way for additional nicer features such as Atomic DDL etc. and we are looking forward to them.