In this blog post, we will describe our Paxos-based solution, named eXtended COMmunications, or simply XCOM, which is a key component in the MySQL Group Replication.
XCOM is responsible for disseminating transactions to MySQL instances that are members in a group and for managing their membership. Its key functionalities are:
- Ordered Delivery: Guarantees that messages (i.e. transactions) are delivered by the same order at all members
- Dynamic Membership: Provides functionalities to manage the set of MySQL Server instances belonging to the group
- Failure Detection: Along with Dynamic Membership, decides upon the fate of failed members
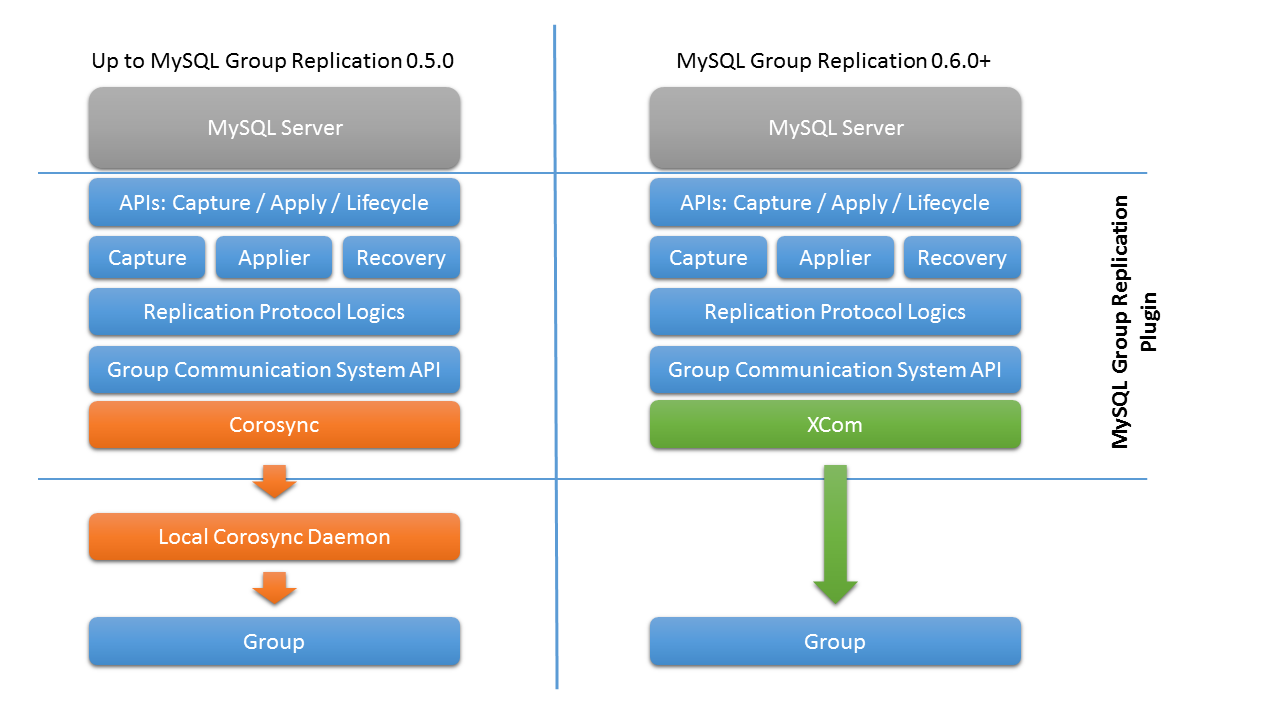
In the beginning of the MySQL Group Replication project, we used Corosync as our group communication system but soon decided to switch to our own solution as described in this blog post: Order from Chaos: Member Coordination in Group Replication.
In what follows, we will present some background information on Group Replication and Consensus, then we will describe our design decisions behind XCOM.
1. Background
MySQL Group Replication is based on the Database State Machine. Update transactions are started and executed at a member without requiring any coordination with remote members. Upon commit, transaction’s changes are disseminated to all members in the group and delivered everywhere by the same order. Then a certification process checks whether there are conflicts among concurrent transactions, verifying if any other transaction has tried to update a record that had been already updated before. If there is no conflict, the transaction is committed at all members. Otherwise, it is aborted.
See further details on this process at MySQL Group Replication – Transaction life cycle explained.
Behind this solution there is a group communication system which manages the membership and guarantees that messages carrying out transactions’ changes are totally ordered. Membership management and totally ordered message delivery are instances of a fundamental concept in distributed system know as consensus:
In our case, MySQL Server instances reach an agreement on whether a new MySQL Server instance shall be added to the group or an old instance shall be removed from it or which transaction’s change shall be the next one to be delivered.
Paxos is probably the most well known consensus protocol and works in two phases.

Classic Paxos is a leader-oriented algorithm. As such, the first phase is called Prepare or Leader Election phase, in which a member sends a message tagged with a ballot number to all members suggesting that it wants to become a leader. Members that have not promised to anybody that they already accepted a request from another member with a higher ballot number will reply to the request. If the member gets replies from a majority of members in the group, it will become the new leader. Otherwise, the member will simply try to win the election with a higher ballot number after a timeout until it succeeds.
Note that this phase is only necessary if the current leader has been suspected to have failed. Otherwise, only the second phase of the protocol is executed. See Good Leaders are game changes: Paxos & Raft for a discussion on leader election, ballot numbers, etc.
During the second phase, the leader proposes a value which is considered accepted when it gets a reply from a majority of members. Messages are tagged with the leader’s ballot number and a member will only reply to the leader saying that it accepts the proposal if nobody else has tried to take over the leadership with a higher ballot number.
When the leader finds out that a proposal has been accepted, it sends a learn message to all members in the group saying that they can deliver the message to the Group Communication System Layer which will eventually deliver it to MySQL Group Replication. Usually, the learn message is piggybacked onto or batched along with other messages.
In practice, agreement is reached over a sequence of values and this protocol is known as Multi-Paxos.

Note that with classic or standard Multi-Paxos, any member has to send the transaction’s changes to the leader which then guarantees a total ordered message delivery. If the transaction was executed at the same member that was elected as Paxos leader, there is no problem. Otherwise, there will be an extra communication step and usually the leader will become a bottleneck:
2. XCOM
MySQL Group Replication is a multi-master update everywhere solution and transaction’s changes may be originated at any member in the group. Having a leader-based protocol would clearly harm scalability as all updates would have to go through the leader which then would be responsible for disseminating them. So our first goal was to overcome the possible bottleneck with a single leader approach and we created a multi-leader or more precisely a multi-proposer solution. This approach has some similarities to Mencius, for example uses skip messages, but the overall design is closer to the original Paxos.

In this protocol, every member has an associated unique number and a reserved slot in the stream of totally ordered messages. For example, with three members:
- member 0 will get slots: 0, 3, 6, … 3 * n + 0
- member 1 will get slots: 1, 4, 7, … 3 * n + 1
- member 2 will get slots: 2, 5, 8, … 3 * n + 2
In a group with 'g' members, the next slot available to a member is given by the formula: g * n + member's number where ‘n’ is a monotonic counter kept by each member and incremented every time a proposal is sent.
So there is no leader election and each member is a leader of its own slots in the stream of messages. Members can propose messages for their slots without having to wait for other members, although there is a limit on how far they can get as we will describe in the next section.
2.1 Handling Gaps
If members may propose messages to their own slots without any coordination, it is likely that there may be gaps in the message stream. For example, member 1 and 2 may have got an agreement on messages 1 and 2, respectively, but member 0 may have not proposed or got an agreement on message 0 yet, whatever the reason is.
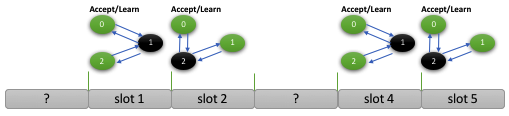
In this case, members cannot deliver the slot’s content in 1 and 2 without agreeing on and eventually delivering the slot’s content in 0 first. Otherwise, the totally ordered message delivered property would be violated. So all members have to wait until they learn what lies in slot 0 to deliver 0, 1, 2 and so forth.
So gaps in the message stream may harm performance and the system has to deal with them very carefully. Member 0 may have not filled in slot 0 yet because it may not have anything to propose, has died or is simply slow.
If member 0 has nothing to propose, it will send a skip message to all members in the group saying that it does not have anything to propose and they can fill in its current slot with a “noop”. The skip message will be sent if there is no data message to be sent out to the group on that member or after it has noticed that there may be other members that are waiting for its proposal to make progress. This will happen when it learns the decision for a slot that it is ahead of its current slot.
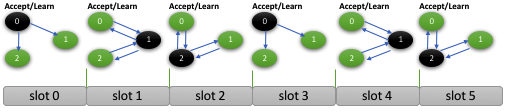
The skip message does not have to go through the regular Paxos protocol (i.e. prepare, accept and learn messages). It is a learn message which informs all the other members that they have to fill in a slot with a “noop”. This optimization is only possible because members that are not slots’ owners can only propose a “noop” for such slots and have to execute all the phases in the Paxos protocol (i.e. prepare and propose phases). In other words, if member 1 wants to propose something to fill in slot 0 in order to be able to deliver messages 1 and 2 in the example, it has to propose a “noop”.
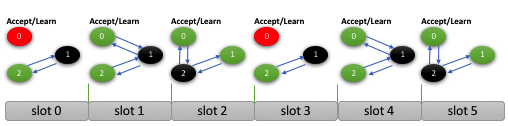
Note that one of the goals of the prepare phase is to find out whether another message has been decided or proposed for a slot. In such case, the message will be sent out by the member that is acting on behalf of the slot’s owner. Using the two phases in the Paxos protocol, the member will guarantee that there will be no inconsistency. In order to avoid having several members trying to propose a “noop” on behalf of another member, something that would slow down the overall system, the alive member with lowest unique number is responsible for this task. However, there is no formal leader election as the member will not become responsible for other members’ slots. It will just step in whenever it is necessary in order to allow the system to make progress.
2.2 Implemented Optimizations
Messages can be batched together to fill in just one single slot thus reducing the number of communication steps. Besides, members can propose new messages without having to wait for a decision on its previous proposals.
Batching and pipelining are two optimizations that can increase performance and we implemented them. However,
Their effectiveness depends significantly on the system properties, mainly network latency and bandwidth, but also on the CPU speed and properties of the application.
See Tuning Paxos for high-throughput with batching and pipelining for further details on the subject.
We also transmit the application data only once in the accept phase to avoid going back and forth with huge amounts of data. According to Vitor, this optimization alone was responsible for (roughly) 20% boost in performance.
3. Current Limitations
The current version available as part of MySQL Server 5.7.17 does not allow users to tune the size of the pipeline and the number of bundled proposals.
The current version does not allow either to configure the roles that a member will have in the protocol: proposer, acceptor and learner. This means that all members are proposers and it is simple to see that a slow member may harm the overall system performance. Slowness may be caused by constraints or issues in the network such as high latency or constraints or issues in the machine where the member is running such as an overloaded machine.
5. Conclusion
Download MySQL Group Replication at https://dev.mysql.com/downloads/mysql/ and find instructions on how to set up in the manual. Please, take it for a spin and if you do encounter any issue, please file a bug report under the ‘MySQL Server: Group Replication’ category so that we can be informed about the issue and can investigate it further.