This blog explains how relay log recovery happens in a scenario where an applier thread (SQL_Thread) is starting for the first time and its starting position is not available for relay log recovery operations. If you are using GTIDs with MASTER_AUTO_POSITION then the following is more or less irrelevant since we then employ a more resilient repositioning scheme. The potential issue described here will also not occur if you have employed crash-safe replication settings, including --sync_master_info=1. With those disclaimers out of the way, let’s proceed.
Background
A crash-safe slave in MySQL 5.6 guarantees that replication progress information is always in sync with what has actually been applied to the local database instance. But there can still potentially be a few cases where the synchronization is not 100% guaranteed, for example in the case of DDL statements (which are not yet transactional).
In order to achieve crash-safe replication you must do the following:
- Set relay-log-info-repository to TABLE
- Set relay-log-recovery to 1
- Use a transactional storage engine
Crash safe replication ensures that the applier thread saves its relevant state information at transaction commit time. During recovery—when relay-log-recovery=1—any existing relay logs are discarded and new ones are created. The receiver thread (IO_Thread) then starts fetching events from the master’s binary log that the applier thread(s) (SQL_Thread) had previously applied on the slave. In other words, the receiver thread’s Read_Master_Log_Pos is set to applier thread’s Exec_Master_Log_Pos. (You can learn more about what those positions mean here). So in practice the receiver thread copies the applied position from the applier thread and starts pulling the master binary log events from that point forward. The applier thread’s Relay_Log_File and Relay_Log_Pos values are then set to new relay log file and position.
In MySQL 5.6.22, we made this procedure even smarter. In the case that an applier thread does not report any position at all (e.g., it had not been started yet when the crash happened), then the slave still tries to mine the relay logs for the first rotate event from the master and then sets the slave’s file and position info based on that event instead.
Problem
The relay log recovery process explained above is entirely dependent on an applier thread’s position. There could, however, be a scenario where an applier thread was never started whereas the receiver thread was. In that case a receiver thread may have download events from the master’s binary log and appended them to slave’s relay log(s). If a crash happens in this scenario and the server is restarted, then even when crash safe settings are enabled the automatic recovery could still fail. This is because the recovery process expects Relay_Master_Log_File to be set in order to start the recovery process. If that value is not set, then the recovery process will finish without doing any recovery work.
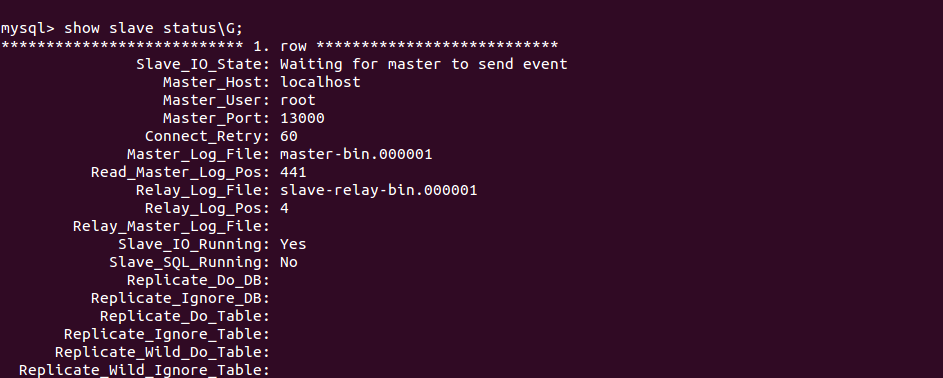
Crash safe replication ensures that the applier thread’s state is saved at transaction commit time, whereas the same is not guaranteed for the receiver thread’s state. That means that the receiver thread’s position info is not updated with each event as they are pulled from the master. Hence the slave_master_info table could potentially be out-of-date. This could then cause the events to be fetched once again and appended (for a second time) to the slave’s relay log(s). When the applier thread is then started post-recovery this could result in duplicate key errors on the slave. This issue was reported as Bug#73039 (fixed in MySQL 5.6.22).
Solution
The solution (implemented in MySQL 5.6.22) to this issue then is that during the recovery process the Relay_Master_Log_File and the correct position should be identified properly even when applier thread has not been started.
The following steps are taken in order to achieve this:
- Locate the first rotate event that was received from the master in the local relay logs.
- Open the first local relay log and begin reading all relay log events from there onwards.
- Looking for a rotate event from the master.
- If a rotate event is not found in the first relay log then move to the second relay log and so-on until we reach the last available relay log. (Ignoring the Format description event, Previous_gtid log event, and other Ignorable events within the relay log.)
- When a rotate event is found, check to see if it is a rotate event that originated from the master or not, based on the server_id.
- If the rotate event is from a slave or if it is a fake rotate event, then ignore it.
- If any other events are encountered apart from the above events, then generate an error.
- From the found rotate event, extract the master’s binary log name and position info and use that for the subsequent relay log recovery steps.
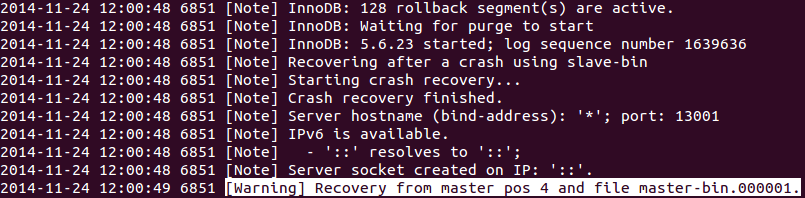
The recovery process will then start as shown below:
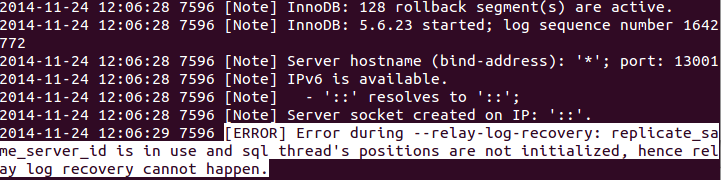
One potential problem with this method of recovery is if the replicate_same_server_id option is used then it will not be possible to use this method for the recovery. In this case an error would be generated as shown below:
Summary
This fix is available in MySQL 5.6.22 and ensures that relay log recovery will happen smoothly even when the applier thread was not previously started and thus the Relay_Master_Log_File value is not available. Now we can locate the first rotate event from the master in the existing local relay log files and then extract the master log file name and position info from there and then use those values for the recovery process. If we’re unable to locate the first rotate event, then an appropriate and helpful error message is generated.
We hope that this improvement helps to make MySQL replication even more robust and easy to use! If you have any questions please feel free to post them here on the blog post or in a support ticket. If you feel that you encountered any related bugs, please let us know via a comment here, a bug report, or a support ticket.
As always, THANK YOU for using MySQL!