The MySQL Development Team is very excited and proud to announce a new 8.0 Maintenance Release of InnoDB Cluster – 8.0.17!
In addition to important bug fixes and improvements, 8.0.17 brings a game-changer feature!
This blog post will cover MySQL Shell and the AdminAPI, for detailed information of what’s new in MySQL Router stay tuned for an upcoming blog post!
MySQL Shell AdminAPI
For this release, we have focused on extending the AdminAPI and the whole InnoDB cluster with an extremely important and desired feature – Automatic Node Provisioning!
On top of that, we have remodelled and improved the AdminAPI handling of internal accounts, and we’ve extended it to provide better monitoring capabilities and handling of cross-version policies. Finally, quality has been greatly improved with many bugs fixed.
Here are the highlights of this release:
- Automatic Node Provisioning
- Improved and simplified internal recovery accounts management
- Automatic handling of cross-version policies
- Improved cluster status information
Automatic Node Provisioning
The AdminAPI provides an easy and straightforward way to manage a cluster topology in order to add or remove instances from it. However, to successfully accept a new member in a cluster, Group Replication requires that all are synchronized, i.e. the joining member has processed the same set of transactions as the other group members, which happens during the distributed recovery phase.
Distributed recovery
Group Replication implements a mechanism that allows a server to get missing transactions from a cluster so it can successfully join it. This mechanism is called distributed recovery and in MySQL 8.0.16 and earlier was only capable of establishing a regular asynchronous replication channel between the joining instance and a cluster member, behaving as a donor.
Commonly, binary logs are purged over time to save storage space, thus the asynchronous replication channels on which distributed recovery solely relied on are not able to replicate the data from the donor to the receiver. On top of that, large data sets may take a considerable amount of time to be replicated, meaning an instance would not be available as an ONLINE member of the cluster for quite some time.
Summarizing, distributed recovery based on asynchronous replication won’t be enough for some common scenarios…
But with MySQL 8.0.17 that has finally changed! With the introduction of built-in Clone support in MySQL and its integration by Group Replication, we could finally overcome such limitations and move towards the complete out-of-the-box HA solution.
The Clone Plugin, in general terms, allows taking physical snapshots of databases and transfer them over the network to provision servers. Thus enabling remote cloning without any external tooling.
Note: Clone completely overwrites the state of
the receiver with a physical snapshot of the donor.
To accomplish transparent handling and management of the automatic node provisioning provided by the Clone Plugin and Group Replication, we have extended the AdminAPI with three main aspects:
- Built-in checks and prompts to guide the users on corner-case scenarios through the most convenient and ideal path to accomplish their needs.
- Ability to choose which data transfer mechanism shall be used during Group Replication’s distributed recovery.
- Monitoring of the provisioning process with dynamic progress information.
On top of that, all handling of recovery accounts and any necessary step to use the built-in clone support is automatically and transparently managed by the AdminAPI.
Details on how this has been achieved will be described in a series of articles, starting with this blog post that starts with a screencast of automatic node provisioning in the AdminAPI!
Worth mentioning in this blog post, are the API changes and extensions.
dba.checkInstanceState()
This command can determine whether an instance will successfully join a cluster or not depending on its GTID-set state in comparison with the cluster. We have greatly improved the checks, to be more precise but also to consider that clone may be available on the target instance.

dba.createCluster()
The AdminAPI will, by default, ensure that the clone plugin is installed (if available) whenever creating a cluster.
However, a new option was added to dba.createCluster() to allow disabling the clone usage for a cluster:
disableClone
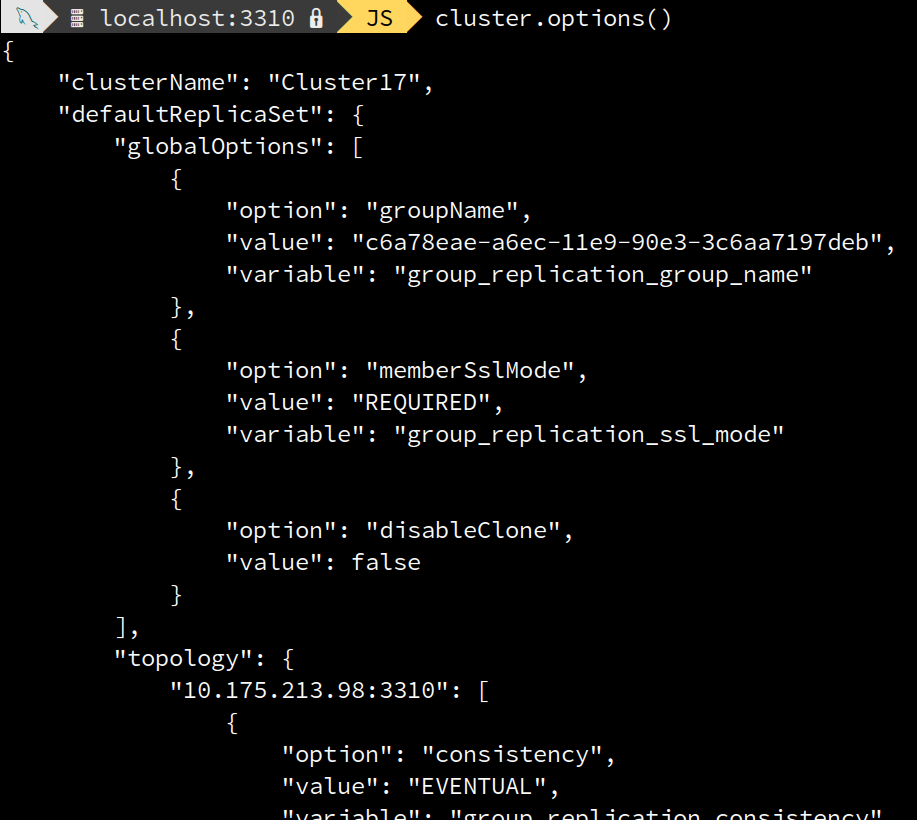
<Cluster>.setOption() and <Cluster>.options()
As a consequence, <Cluster>.setOption() was extended to allow changing the value of disableClone for a running cluster. Thus it is possible to disable the clone usage at any time or even to enable it in case it wasn’t.
On top of that <Cluster>.options() was extended to display as well the value of disableClone.
<Cluster>.addInstance()
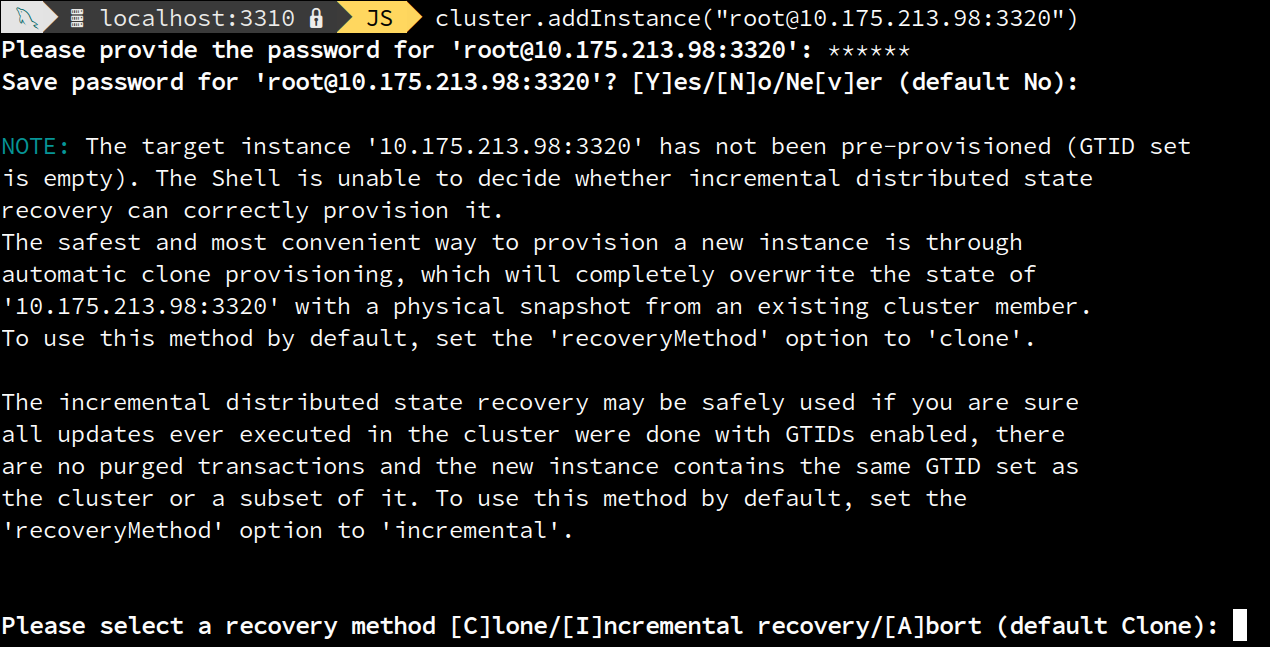
Regarding the distributed recovery mechanism to transfer data used in <Cluster>.addInstance(), the AdminAPI handles it and guides the user accordingly by default, but there’s also the possibility of explicitly setting which one shall be used. For that reason, the command has been extended with a new option named 'recoveryMethod' that accepts the following values:
- incremental: uses asynchronous replication channels to recover and apply missing transactions copied from another cluster member. Clone will be disabled.
- clone: uses built-in MySQL clone support, which completely replaces the state of the target instance with a full snapshot of another cluster member. Requires MySQL 8.0.17 or newer.
- auto: let Group Replication choose whether or not a full snapshot has to be taken, based on what the target server supports and the group_replication_clone_threshold sysvar. This is the default value. A prompt will be shown if not possible to automatically determine a convenient way forward. If the interaction is disabled, the operation will be cancelled instead.
Progress Monitoring
Full detailed monitoring of the recovery progress has been added to <Cluster>.addInstance(). The pace of clone based recovery is now monitorable with progress information.
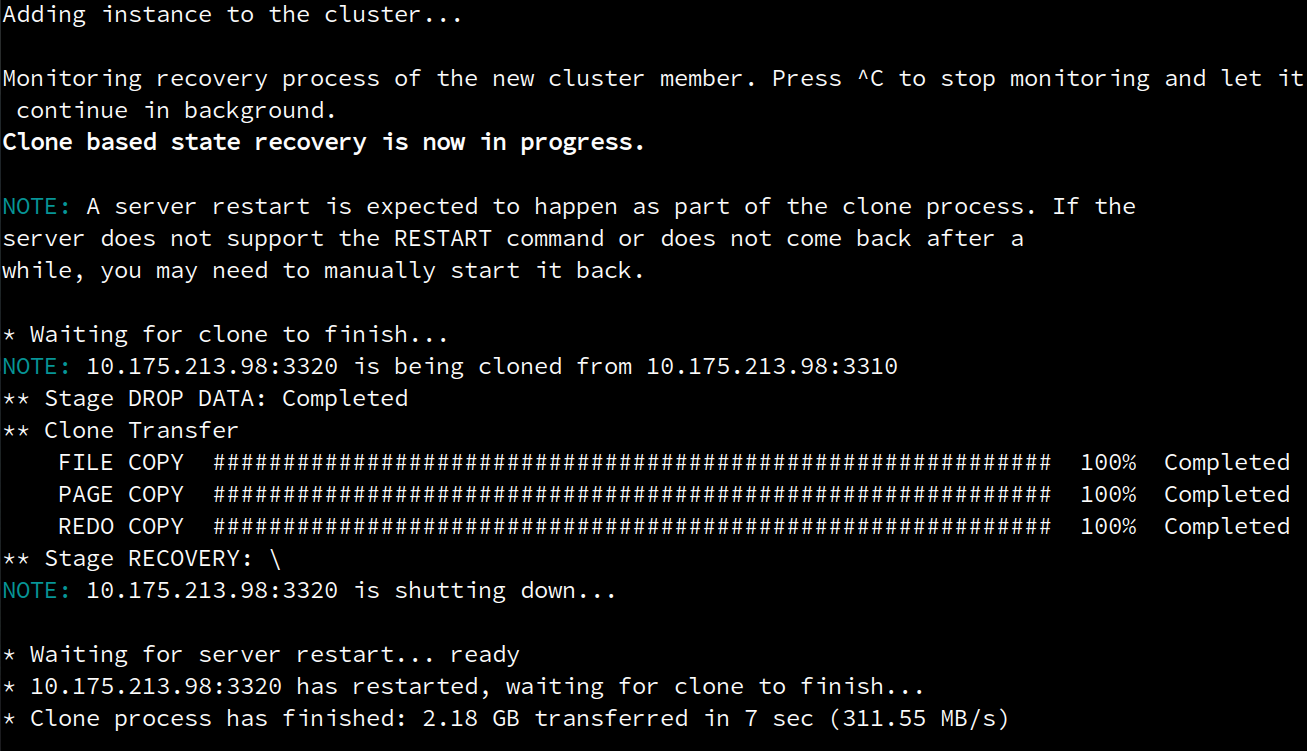
A very noticeable changed introduced in 8.0.17 is that <Cluster>.addInstance(), by default, waits until the distributed recovery process has finished and the instance is ONLINE in the cluster before returning to the user.
The progress monitoring happens asynchronously and can be safely interrupted at any time in the Shell by pressing ctrl-c. The recovery process will continue normally even if you exit the shell.
Control over monitoring behavior
To control the behavior of the monitoring in <Cluster>.addInstance(), a new option was added named 'waitRecovery'. The option can take the following values:
- 0: do not wait and let the recovery process to finish in the background.
- 1: block until the recovery process to finishes.
- 2: block until the recovery process finishes and show progress information.
- 3: block until the recovery process finishes and show progress using progress bars.
The old non-blocking behaviour where <Cluster>.addInstance() returns even when recovery hasn’t finished, can be enabled by setting the 'waitRecovery' option to '0'.
Example: cluster.addInstance(“clusterAdmin@10.276.2.10:3306”, {waitRecovery: 0})
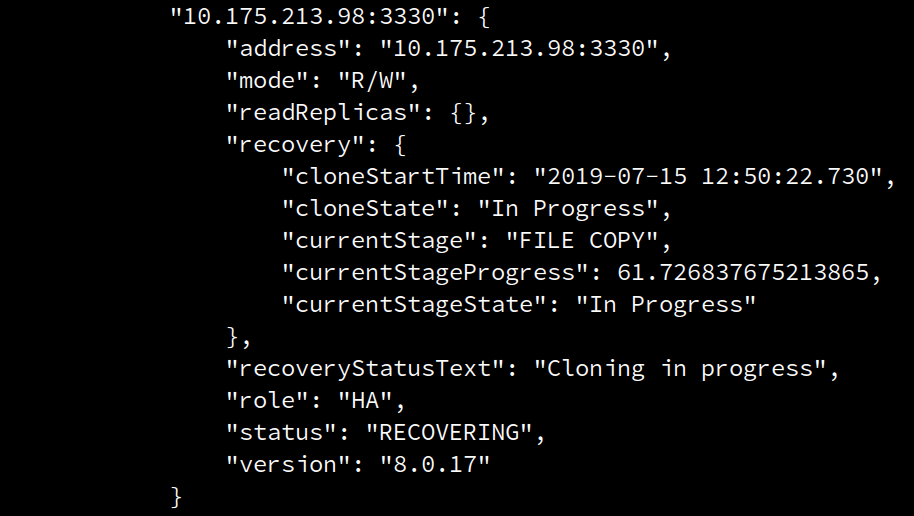
<Cluster>.status()
At any moment, progress information can be checked with the regular means, that is using <Cluster>.status()
The following screenshot shows a snippet of the output of the command whenever clone-based recovery is taking place.
Simplification of internal recovery accounts
Distributed recovery, regardless if uses the clone-based mechanism to transfer data or an asynchronous replication channel, requires a so-called recovery account. Shell automatically and securely creates and manages those accounts.
For security reasons, the Shell does not store credentials for those internal accounts and instead, created a new account with a unique generated password for each new joining member, following a naming schema of mysql_innodb_cluster_r[10_numbers].
The hostname used was both the wildcard '%', allowing access from every host and also 'localhost'. If IP whitelisting was used, for each address in the ipWhitelist list an internal used would be created. As for the password, it would be a randomly generated secure value.
Even though this allowed transparent and automatic handling of replication accounts, there were some drawbacks. In some cases, multiple such accounts were created for each instance, one for each possible connecting host. On top of that, removing an instance from a cluster did not imply that its recovery account was removed from the cluster itself. An InnoDB cluster user that scales its application servers based on demand, on which servers are lost and re-created, would see an exponential growth of orphaned replication accounts.
Those particularities are certainly undesired, and for that reason, in 8.0.17 we have greatly improved the management of InnoDB cluster internal accounts.
This account handling has been changed in 8.0.17 having a goal in mind:
Each cluster member shall have a single replication account automatically managed for every cluster topology change.
To simplify that, one single account is now created whenever an instance joins a cluster, following a naming schema of mysql_innodb_cluster_[server_id]@%. Since instances in a cluster must have a unique @@server_id, this allows simpler management of recovery accounts.
Finally, <Cluster>.removeInstance() removes the recovery account of the instance being removed on the primary member of the cluster.
Summarizing, the handling of the accounts has been greatly improved to:
- Simplify the accounts naming
- Automatically create, re-use or remove accounts accordingly
- Remove the ipWhitelist handling
- Do not allow an exponential growth of the accounts number
Handling of cross-version policies
Ideally, all members of an InnoDB cluster should run the same MySQL Server version for optimal performance and compatibility. However, common scenarios such as upgrading or downgrading a cluster are desirable to be performed on online clusters, otherwise, availability would be lost. For that reason, InnoDB cluster supports mixing different MySQL versions in the same cluster. But, considering that new versions come with new features or even deprecations may happen, cluster members relying on such features would fail. Also, writing to cluster members running a newer version than the remaining members can cause issues if new functions are being used which are only supported in that new version.
To prevent such scenarios, there are cross-version policies in place that may not allow a particular set of versions to join a cluster and/or limit and enforce an instance role in a cluster.
Up to 8.0.16, those policies only considered the major version of the instances. But since MySQL’s release model allows a rapid and continuous improvement and introduction of features in patch versions, Group Replication has improved the policies to also consider patch versions. Doing so, we can ensure much better replication safety for mixed version clusters during regular operations, group reconfigurations and upgrade scenarios.
Such policies are handled by Group Replication internals, but to provide optimal usability, the AdminAPI should run those checks beforehand to properly inform the user of any error or warning due to cross-version policies.
In 8.0.17, we have extended the AdminAPI to support the compatibility policies. The <Cluster>.addInstance() operation now detects incompatibilities due to MySQL versions and in the event of an incompatibility aborts with an informative error or warning.

On the example above, the cluster consisted of instances running 8.0.15 and the joining instance had version 8.0.17. The cross-version policies mandate that the instance can join the cluster but will run in R/O mode regardless of the cluster topology-mode.
Improved cluster status information
The <Cluster>.status() output was changed to include new information, depending on the value of the 'extended' option:
- 0: disables the command verbosity (default)
- 1: includes information about the Group Protocol Version, Group name, cluster member UUIDs, cluster member roles and states as reported by Group Replication and the list of fenced system variables
- 2: includes information about transactions processed by connection and applier
- 3: includes more detailed stats about the replication machinery of each cluster member.
- Boolean: equivalent to assign either 0 or 1
Also, the <Cluster>.status() attribute 'mode' now considers the value of super_read_only and whether the cluster has quorum or not, i.e. when a cluster member has super_read_only enabled its ‘mode’ reflects the real mode of the instance, that is R/O. On top of that, when a cluster has lost its quorum, all cluster members are listed as R/O.
Finally, we added the following new attributes, whenever 'extended' is set to a value equal to or higher than 1:
- memberRole
Member Role as it is provided by Group Replication itself, i.e. from performance_schema.replication_group_members.MEMBER_ROLE
- memberState
Member State as it is provided by Group Replication itself, i.e. from performance_schema.replication_group_members.MEMBER_STATE
- fenceSysVars
List containing the name of the fence system variables which are enabled. The fence sysvars considered are read_only, super_read_only and offline_mode.
The previous example, on which we added an 8.0.17 instance to an 8.0.15 cluster and the cross-version policies enforced that the joining instance has to run in R/O mode is a good example to illustrate the changes in <Cluster>.status(). The following screenshot includes a snippet of the command output when setting the extended option to ‘1’:
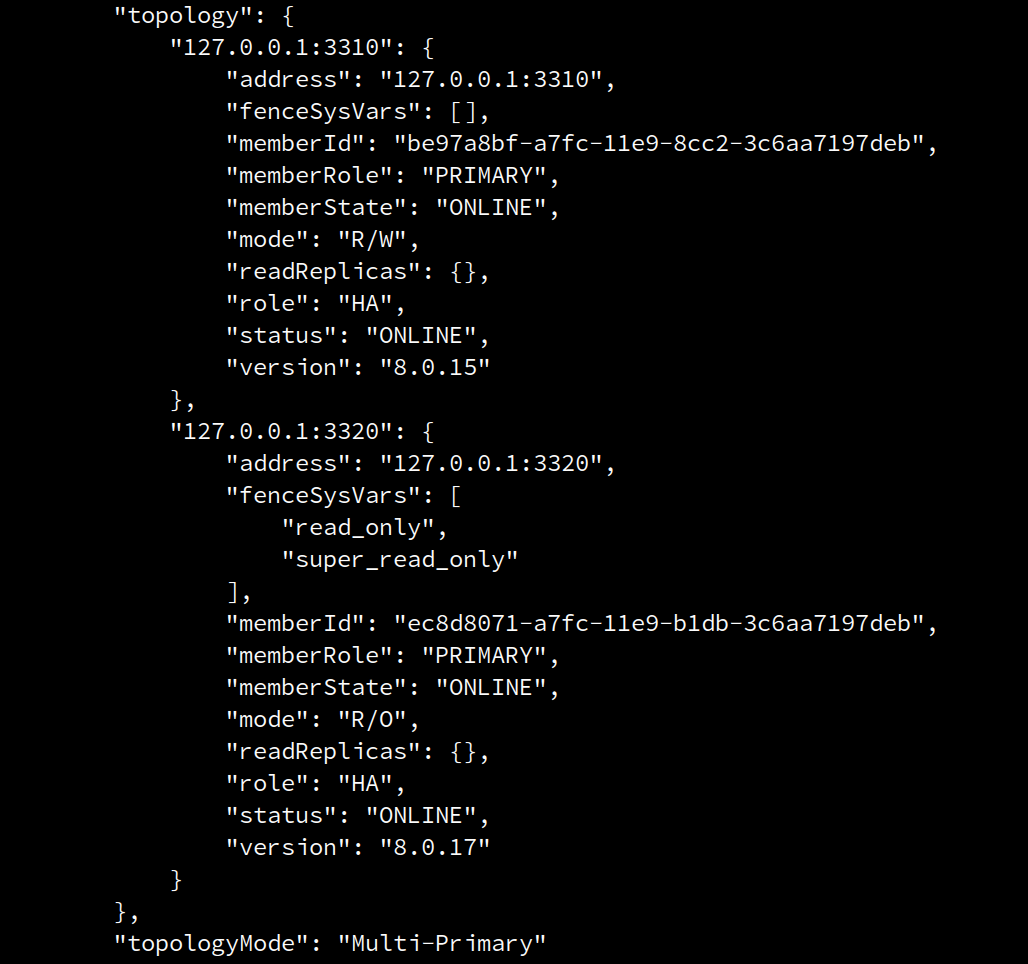
As you can see, the 8.0.17 instance’s role is “PRIMARY”, however, it’s mode is “R/O”. On top of that, a list of fence sysvars is presented being those: “super_read_only” and “read_only”.
Notable Bugs fixed
For the full list of bugs fixed in this release, please consult the changelog. However, there are some that deserve being mentioned.
BUG#28855764 – User Created By Shell Expires With Default_password_lifetime
The internal recovery accounts created by the AdminAPI could become unusable if a global password expiration policy was defined. This has been fixed by disabling the password expiration for those users as they do not need to be taken into consideration for password policies considering they are internal and securely handled.
BUG#29305551 – Adminapi Fails To Detect Instance Is Running Asynchronous Replication
To use an instance for InnoDB cluster, whether it is to create a cluster on it or add it to an existing cluster, requires that the instance is not already serving as a slave in asynchronous (master-slave) replication. Up to now, dba.checkInstanceConfiguration() was incorrectly reporting that the instance was valid for cluster usage. Consequently, dba.createCluster() and <Cluster>.addInstance() failed without informative errors.
This bug has been fixed by introducing a check to verify whether an instance is already configured as a slave using asynchronous replication and generating an informative error in that case.
BUG#29271400 – Createcluster() Should Not Be Allowed In Instance With Metadata
Scenarios of a complete outage can lead to the existence of instances that have a populated Metadata Schema but are not part of any running cluster. Up to now, it was possible to simply create a new cluster on that instance overriding the current Metadata, which was unexpected.
Now, in such a situation the dba.createCluster() throws an exception and you can choose to either drop the Metadata schema or reboot the cluster.
BUG#29559303 – Removeinstance(), Rejoininstance() Shouldn’t Drop All Accounts
<Cluster>.removeInstance() dropped all accounts locally in the instance being removed. Also, <Cluster>.rejoinInstance() did that before re-creating its own recovery account.
So if for some reason an instance is removed from a cluster but then added back, it will be missing accounts needed for recovery of other members through that instance.
This has been fixed with the simplification of the recovery accounts handling mentioned above and also with the right removal of the accounts in <Cluster>.removeInstance(). The recovery account of the instance being removed on the primary and the process waits for the changes to be replicated before actually removing the instance from the group.
BUG#29756457 – Replication Filter Should Be Blocked Just Like Binlog Filters
InnoDB clusters do not support instances that have binary log filters
configured, but replication filters were being allowed. Now, instances with
replication filters are also blocked from InnoDB cluster usage.
Try it now and send us your feedback
MySQL Shell 8.0.17 GA is available for download from the following links:
- MySQL Community Downloads website: https://dev.mysql.com/downloads/shell/
- MySQL Shell is also available on GitHub: https://github.com/mysql/mysql-shell
And as always, we are eager to listen to the community feedback! So please let us know your thoughts here in the comments, via a bug report, or a support ticket.
You can also reach us at #shell and #router in Slack: https://mysqlcommunity.slack.com/
The documentation of MySQL Shell can be found in https://dev.mysql.com/doc/mysql-shell/8.0/en/ and the official documentation of InnoDB cluster can be found in the MySQL InnoDB Cluster User Guide.
The full list of changes and bug fixes can be found in the 8.0.17 Shell Release Notes.
Enjoy, and Thank you for using MySQL!