An important thing to know when managing an InnoDB cluster are the states that the cluster can be in, especially to know how to interpret the reported status of the cluster and specifically what to do to recover from failure various scenarios.
Group Replication Member States
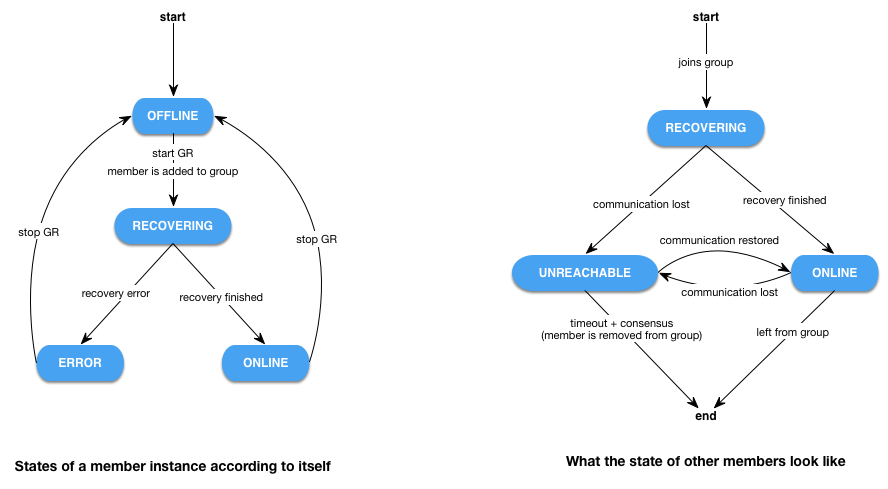
The state that a group member can be in depends on whether you’re querying the member directly or indirectly through other members.
States as visible to the member itself:
OFFLINERECOVERINGERRORONLINE
States as visible to other members:
RECOVERINGUNREACHABLEONLINE
When an instance is running but has not yet joined any group, it’s in the OFFLINE state. Once you join a group, it will switch to RECOVERING as the instance syncs up with the rest of the group.
Once the distributed recovery is done, it finally switches to ONLINE. If the distributed recovery fails for some reason, it switches to ERROR.
If an ONLINE member stops responding to the other members (because it has crashed, networking problems, extreme high load, timeout etc.), its state will be switched to UNREACHABLE. If the UNREACHABLE member doesn’t return before a timeout, it will be removed from the group by the remaining members, and thus will appear as (MISSING) in the cluster.status() command output. That process of expelling a member is done through a vote, so it will only happen if there are enough members available for a quorum.
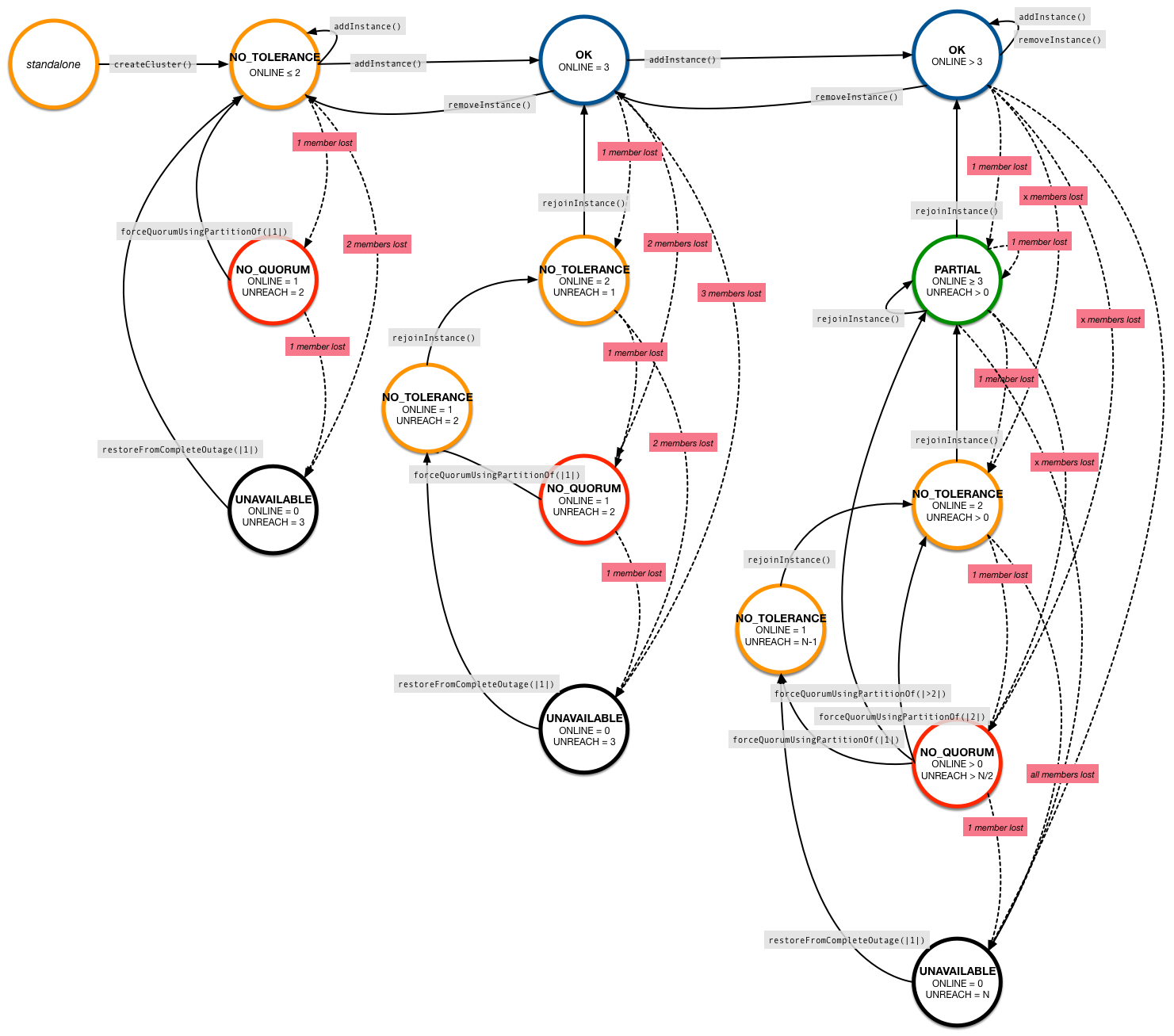
Group or Replica Set States
The following diagram gives an overview of the possible states that a group can assume and how state transitions occur.
Solid transition lines show MySQL Shell commands that you can execute in each state, while dashed lines are events triggered outside of our control.
Some possibilities are omitted from the diagram for the sake of reducing clutter. For example, you can execute most commands, like addInstance() or rejoinInstance(), in any state as long as there is a quorum.
The group states shown by the cluster.status() command are:
-
OK– is shown when all members belonging areONLINEand there is enough redundancy to tolerate at least one failure. -
OK_PARTIAL– when one or more members are unavailable, but there’s still enough redundancy to tolerate at least one failure. -
OK_NO_TOLERANCE– when there are enoughONLINEmembers for a quorum to be available, but there’s no redundancy. A two member group has no tolerance, because if one of them becomesUNREACHABLE, the other member can’t form a majority by itself; which means you will have a database outage. But unlike in a single member group, at least your data will still be safe on at least one of the nodes. -
NO_QUORUM– one or more members may still beONLINE, but cannot form a quorum. In this state, your cluster is unavailable for writes, since transactions cannot be executed. However, read-only queries can still be executed and your data is intact and safe. -
UNKNOWN– this state is shown if you’re executing thestatus()command from an instance that is notONLINEorRECOVERING. In that case, try connecting to a different member. -
UNAVAILABLE– this state is shown in the diagram but will not be displayed by thecluster.status()command. In this state, ALL members of the group areOFFLINE. They may still be running, but they’re not part of the group anymore. This can happen if all members restart without rejoining, for example.
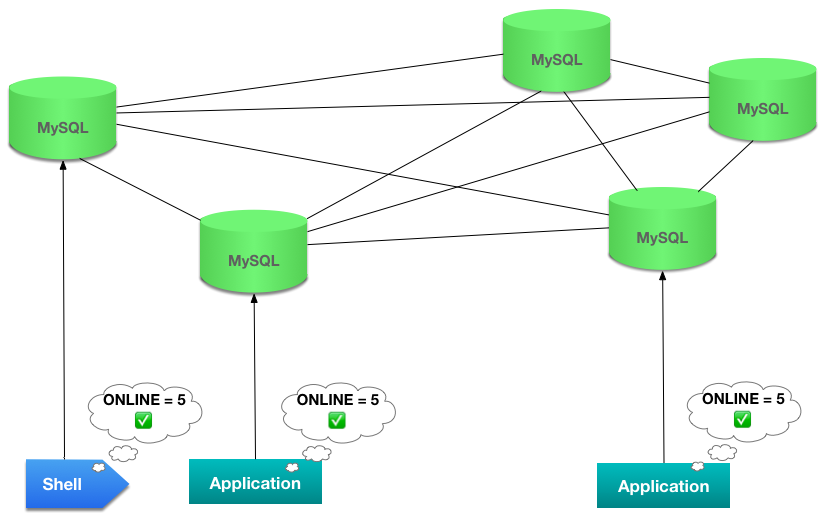
Group Partitions
One exceptional scenario that although rare can be confusing and sometimes dangerous is a group partition, when members of a group are virtually broken down into 2 or more sub-groups. That can happen if, for example, you have members in different networks and the communication between them is disrupted. In that case, all members can be ONLINE, but the members of one group will be seen as UNREACHABLE by the other and vice-versa. Because of the requirement for a majority, only one partition (at most) will be able to receive updates, preserving consistency of the database.
But when using the cluster.forceQuorumUsingPartitionOf(), which is explained below, you must be careful that you’re not in such a situation. If that is the case, you could be creating 2 separate groups that receive updates separately, which would cause your database to process transactions independently and leave it in an inconsistent state.
ONLINE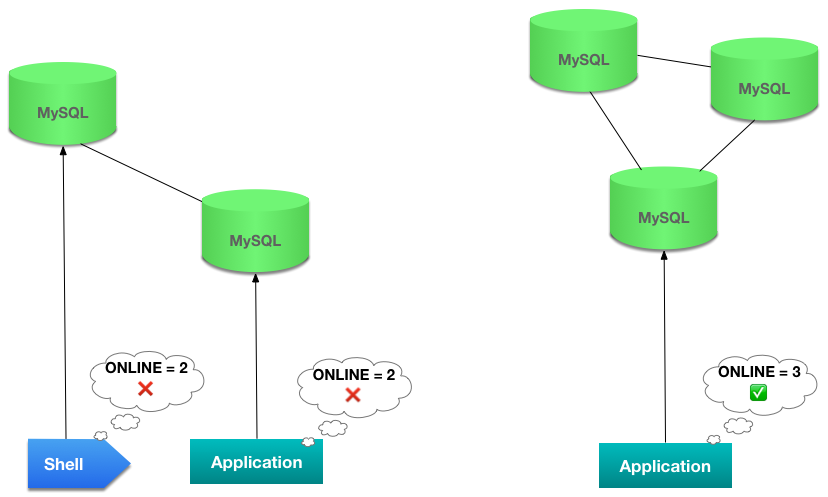
Recovering from Failures
The following scenarios are some of the most common situations you can encounter in the event of a failure. We explain how to identify them and how to recover from them using the InnoDB cluster API in the MySQL Shell.
Server Restarted
If mysqld restarts for any reason (crash, expected restart, reconfiguration etc), it will NOT be in the group anymore when it comes back up. It needs to rejoin it, which may have to be done manually in some cases. For that, you can use the cluster.rejoinInstance() command to bring it an instance back to the group. The parameter it takes is the URI of the instance.
Example: cluster.rejoinInstance("root@192.168.1.50")
Loss of Quorum
If so many members of your replica set become UNREACHABLE that it doesn’t have a majority anymore, it will no longer have a quorum and can’t take decisions on any changes. That includes user transactions, but also changes to the group’s topology. That means that even if a member that became UNREACHABLE returns, it will be unable to rejoin the group for as long as the group is blocked.
To recover from that scenario, we must first unblock the group, by reconfiguring it to only consider the currently ONLINE members and ignore all others. To do that, use the cluster.forceQuorumUsingPartitionOf() command, by passing the URI of one of the ONLINE members of your replica set. All members that are visible as ONLINE from that member will be added to the redefined group.
Note that this is a dangerous command. As explained above, if you happen to have a partition in your group, you could be accidentally be creating a split-brain, which will lead to an inconsistent database. Make sure that any members that are UNREACHABLE are really OFFLINE before using this command.
Example: cluster.forceQuorumUsingPartitionOf("root@192.168.1.30")
All Members OFFLINE
The cluster.forceQuorumUsingPartitionOf() command requires at least one instance to be still ONLINE and part of the group. If somehow all your members are now OFFLINE, you can only recover the group if you “bootstrap” the group again, out of a single seed member. To perform that, you need to use the dba.restoreFromCompleteOutage() command on a designed seed instance, and then rejoinInstance() on the remaining members until you have your cluster fully restored.
Note: this command will be available starting from MySQL Shell 1.0.7
Conclusion
MySQL InnoDB cluster aims to make High Availability accessible to MySQL users of all levels of knowledge and experience. While the cluster.status() command lets you monitor the state of your cluster at a glance, it’s very important to know how to interpret it, so that you know when action is required from you and what you should do to ensure that your MySQL databases remain functioning optimally.
To learn more about MySQL InnoDB cluster, please read the announcement and to get started with InnoDB Cluster, please see the updated tutorial.