The first preview release of MySQL Group Replication, a MySQL plugin that brings multi-master update everywhere to MySQL, is available on labs. This plugin ties together concepts and technologies from distributed systems, such as group communication, with traditional database replication. The ultimate result is a seamlessly distributed and replicated database over a set of MySQL servers cooperating together to keep the replicated state strongly consistent.
Introduction
Before diving into the details of MySQL Group Replication, lets first introduce some background concepts and an overview of how things work. These will provide some context to help understand what this is all about and what are the differences between traditional MySQL replication and the one implemented in this new plugin.
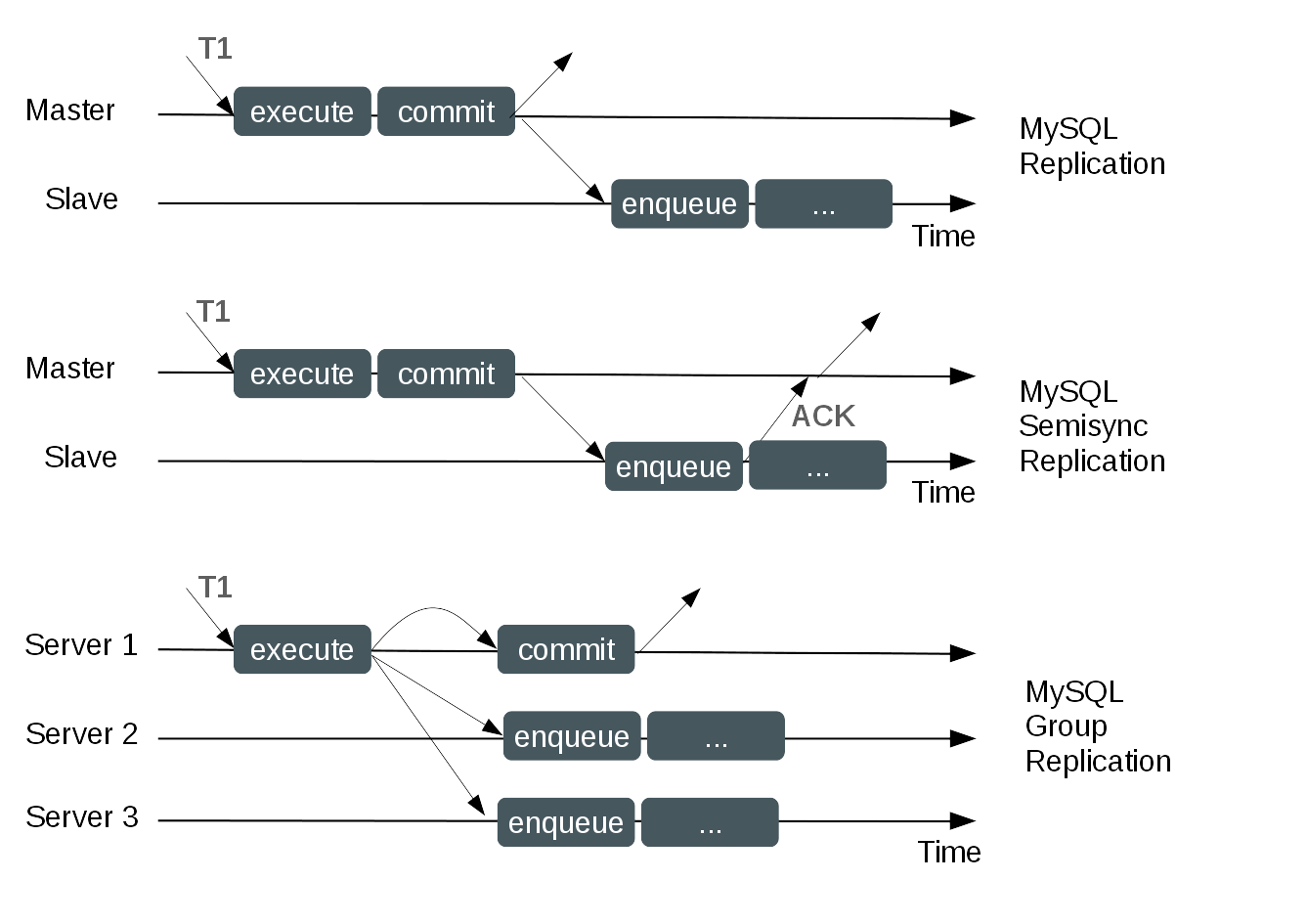
Primary-Backup Replication
Native MySQL Replication protocol’s nature lies within the realm of a simple Primary-Backup approach to replication. There is a primary (master) and there is one or more backups (slaves). The primary executes transactions, commits them and then they are later (thus asynchronously) sent to the backups to be either re-executed (in statement-based replication) or applied (in row-based replication). It is a shared-nothing system, where all servers have a full copy of the data by default.
There is also a variant implemented as a plugin, called semisync replication, which adds one synchronization step to the protocol, between the primary and the backup, whereas the backup has to inform the primary that it has received the transaction before the primary is allowed to proceed (commit – if the server is configured to wait before commit, or just release the session, if the server is configured to wait after the commit).
You can see a diagram of the protocol (and its semi-synchronous variant) in Figure 1.
Group Replication
Group-based replication is a technique that can be used to implement fault-tolerant systems. The replication group is a set of servers that interact with each other through message passing. The communication layer provides a set of guarantees such as atomic message delivery and total ordering of messages. These are powerful primitives and abstractions that allow building more advanced database replication solutions.
MySQL Group Replication builds on such concepts and implements a multi-master update everywhere replication protocol. In a nutshell, a replication group is formed by multiple servers. Each server in the group may execute transactions independently, but a RW transaction only commits after that operation is coordinated within the group. Thence, when a transaction is ready to commit, the server atomically broadcasts the write values (row events) and write set (unique identifiers of the rows that were updated). This establishes a global total order for that transaction. Ultimately, this means that all servers receive the same set of transactions in the same order. As a consequence, all servers apply the same set of changes in the same order, therefore they remain consistent within the group.
However, there may be conflicts between transactions that execute concurrently at different servers. Such conflicts are detected by inspecting the write sets of two different and concurrent transactions. If two concurrent transactions, that executed at different servers, update the same row, then there is a conflict. The end result is that the transaction that was ordered first will commit on all servers, whereas the other transaction will abort, thus rolled back on the server it had originally executed and dropped by the other servers in the group.
Finally, this is a shared-nothing replication scheme where each server has its own entire copy of the data. Figure 1 depicts MySQL Group Replication protocol and just by comparing it to the MySQL Replication (or even MySQL Semi-synchronous replication) you can already figure out some differences.
This is, to some extent, similar to the database state machine approach to replication (DBSM) [1].
The MySQL Group Replication Details
MySQL Group replication is an implementation of a multi-master update everywhere replication protocol using group communication. It is implemented as a MySQL plugin and is an extension to the existing replication framework. It uses the binary log caching infrastructure, Global Transaction Identifiers framework and Row-based replication. Apart from this, it requires data to be stored in InnoDB, and also an external component for the messaging and group membership parts, Corosync. Moreover, it implements an automatic and distributed recovery mechanism for servers that are added dynamically to an existing group, so that they are able to catch up and be brought online.
Self-healing, Elasticity, Redundancy : The Group
In MySQL Group Replication, a set of replicated servers forms a group. A group has a name, which currently takes the form of a UUID. The group is dynamic and servers can leave (either voluntarily or involuntarily) and join it at any time. The group itself will
self-adjust without human intervention, very much autonomically. If a server joins the group, it will automatically bring itself up to date by copying state from an existing server. In fact, state is transferred by means of regular MySQL replication, so there is nothing new or overly complex happening behind the scenes. This means that the overall look and feel does not change much from what MySQL users are used to.
In the event that a server leaves the group, for instance it was taken down for maintenance, the remaining servers shall notice that it has left and will reconfigure the group automatically.
So, the group is elastic so to speak!
Update Everywhere
Since there are no primary servers (masters) for any particular data set, every server in the group is allowed to execute transactions at any time, even transactions that change state (RW transactions).
As explained above, any server may execute a transaction optimistically and later when finishing the transaction, it will coordinate the commit within the group. This coordination serves two purposes: (i) check whether the transaction should commit or not; (ii) and propagate the changes so that other servers can apply the transaction as well if they all decided to commit.
Since a transaction is sent through an atomic broadcast, either all servers in the group receive the transaction or none will. If they do receive, then they all receive it in the same order w.r.t. other transactions that were sent before. Conflict detection is done by inspecting and comparing write sets of transactions. Thence, they are detected at row level. Conflict resolution follows the first writer wins rule. If t2 precedes t1, both changed the same row on different servers and when t2 executed t1 was not yet applied on t2‘s server, then t1 wins the conflict and t2 shall abort. t2 was attempting to change stale data!
TIP: If there are transactions that are bound to conflict more often than not, then it is a good practice to start them on the same server. Then they have a chance to synchronize on the local lock manager instead of aborting later in the replication protocol.
Monitoring and Inspecting the System Through Performance_Schema
After introducing the concept of Group and the update everywhere nature of this replication plugin, lets just briefly see how the user can look at what’s happening behind the scenes.
The entire state of the system (including the composition of the group, conflict statistics and service states) can be consulted by querying a set of performance_schema tables. In fact, even though this is a totally distributed replication protocol, the user may monitor it by connecting to just one server in the group, no matter which, and query such tables.
For example, the user can connect to one server and check which are the members of the group and their status:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
member1> SELECT * FROM performance_schema.replication_group_members\G *************************** 1. row *************************** CHANNEL_NAME: group_replication_applier MEMBER_ID: 597dbb72-3e2c-11e4-9d9d-ecf4bb227f3b MEMBER_HOST: nightfury MEMBER_PORT: 13000 MEMBER_STATE: ONLINE *************************** 2. row *************************** CHANNEL_NAME: group_replication_applier MEMBER_ID: 59efb8a1-3e2c-11e4-9d9d-ecf4bb227f3b MEMBER_HOST: nightfury MEMBER_PORT: 13001 MEMBER_STATE: ONLINE *************************** 3. row *************************** CHANNEL_NAME: group_replication_applier MEMBER_ID: 5a706f6b-3e2c-11e4-9d9d-ecf4bb227f3b MEMBER_HOST: nightfury MEMBER_PORT: 13002 MEMBER_STATE: RECOVERING |
The user can also connect to a server and find out statistics about the replication protocol. For instance, how many transactions are in queue and conflicts detected:
|
1
2
3
4
5
6
7
8
9
10
11
|
member1> SELECT * FROM performance_schema.replication_group_member_stats\G *************************** 1. row *************************** CHANNEL_NAME: group_replication_applier VIEW_ID: 1428497631:1 MEMBER_ID: e38fdea8-dded-11e4-b211-e8b1fc3848de COUNT_TRANSACTIONS_IN_QUEUE: 0 COUNT_TRANSACTIONS_CHECKED: 12 COUNT_CONFLICTS_DETECTED: 5 COUNT_TRANSACTIONS_VALIDATING: 6 TRANSACTIONS_COMMITTED_ALL_MEMBERS: 8a84f397-aaa4-18df-89ab-c70aa9823561:1-7 LAST_CONFLICT_FREE_TRANSACTION: 8a84f397-aaa4-18df-89ab-c70aa9823561:7 |
Sneak Peek at the Architecture
Lets look briefly at the architecture of the system. A lot of the existing infrastructure has been reused. Some parts of the code were considerably refactored or modularized and interfaces were created that the plugin can use.

The plugin itself is very much integrated with the server and the current replication layer. It makes use of the binary log caches, slave applier infrastructure, global transaction identifiers, relay log infrastructure, existing replication threads, etc. So the look and
feel to the MySQL end user is not that different from what he is used to. Nonetheless, this had to be very well played together, through proper interfaces, so that modularization of the many components that form this plugin could take place and everything fit together in the end. Figure 2 presents a block diagram depicting the architecture of MySQL Group Replication.
Starting from the top, there is a set of APIs that rule how the plugin interacts with the server. There are interfaces to pass information from the server to the plugin and vice versa. Such interfaces isolate the server core from the plugin and are mostly hooks placed in the transaction execution pipeline. In one direction, from server to the plugin, we have notifications such as server is starting, server is recovering, server is ready to accept connections, server is about to commit a transaction, … In the other direction, there is the
plugin instructing the server to commit/abort ongoing transactions, queue transactions in the relay-log, etc.
Below the API block, there is a set of components that react when a notification is routed to them. The capture component is responsible for keeping track of context related to transactions that are executing. The applier component is responsible for installing remote transactions into the database. The recovery component manages distributed recovery and is responsible for getting a server up to date or even donate state to new servers in the group.
Continuing down the stack, the replication protocol module contains the specific logics of the replication protocol. It handles conflict detection, receives and propagates transactions to the group.
Finally, the last orange box, is the Group Communication API. It is a high level API abstracting the messaging toolkit. Thence it decouples the messaging layer from the rest of the plugin. As mentioned before, the MySQL Group Replication plugin contains a binding of such interface to corosync, thus there is an implicit mapping of our
interface into corosync’s own client API.
The purple boxes are components external to the plugin. Since they make up the rest of the stack and are shown here for completion.
This architecture has some similarities to existing architectures, noticeable with the one proposed by the project Open Replication of Databases (GORDA) [2].
High-Availability With MySQL Group Replication
Typically, fault-tolerant systems resort to redundancy, using replication, to copy the system state throughout a set of servers that may fail independently. Consequently, even if some of the servers fail but not all, the system is still available (may be degraded, performance or scalability-wise, but still available).
MySQL Group Replication fits very nicely into this classification. Server failures are isolated and independent. They are tracked by a group membership service which relies on a distributed failure detector that is able to figure out which are the servers that go down. There is a distributed recovery procedure to ensure that servers get up to date automatically when they join the group. There is no need for server fail-over. Given its multi-master update everywhere nature, not even updates are blocked in the event of a single server failure. Thus, MySQL Group Replication, guarantees that the database service is continuously up.
Mind you that even if the database service is up, in the event of a server crash, those clients connected to it must be redirected/failed over to a different server. This is not something this plugin tries to resolve. The connector, load balancer, or even MySQL Fabric are the more suitable to deal with this issue.
Moreover, adding servers to the group requires at least one round of the distributed recovery procedure to run. This includes a state transfer operation and synchronization. Thence, it is a good practice that when adding a server to the group, one provisions the server beforehand. This makes recovery much faster, since only the missing state is transferred.
In a nutshell, MySQL Group Replication alone provides a highly available, highly elastic, dependable MySQL service.
Examples of Use Case Scenarios
There are use cases where MySQL Group Replication comes in handy:
- Elastic Replication – Environments that require a very fluid replication infrastructure, where the number of servers has to grow or shrink dynamically and with as little pain as possible. For instance, database services for the cloud.
- Highly Available Shards – Sharding is a popular approach to achieve write scale-out. Users can use MySQL Group Replication to implement highly available shards. Each shard can map into a Replication Group.
- Alternative to Master-Slave replication – It may be that a singe master server makes it a single point of contention. Writing to an entire group may prove more scalable under certain circumstances.
Apart from these scenarios, the user may just choose to deploy MySQL Group Replication for the sake of the automation alone that is built into the replication protocol.
Where to Go From Here?
Expect a series of blog posts with more technical details about this plugin and also more details about how the user shall make the best out of this new plugin.
In the meantime, you can go and try this new plugin by downloading from labs.mysql.com.
Limitations
Let me also highlight known limitations and extra features:
- Bugs – It is very likely that people find bugs. In fact, if you do so, we kindly ask you to let us know about them. File bugs on the bugs db.
- DDL Support – The current preview has limited DDL support. If DDL is executed concurrently with DML there will be problems.
- Supported Platforms – The plugin is limited to the platforms that corosync supports.
Very Special Acknowledgement
We would like to acknowledge and thank the contribution from our dear late friend and colleague Astha Pareek. We miss her kindness and cheerful mood everyday.
References
[1] – Fernando Pedone, Rachid Guerraoui, and Andre Schiper. The
database state machine approach, 1999.