With MySQL 8.0, the version of MySQL Database Service aka MDS, the default character set has changed from latin1 to ut8mb4. The default collation is utf8mb4_0900_ai_ci but what does that mean ? and why are the utf8mb4_0900_* the recommended ones ?
Collations like utf8mb4_unicode_520_ci and utf8mb4_0900_ai_ci are based on Unicode Collation Algorithm (UCA). The number in the collation defines the UCA version:
- UCA 9.0.0 (recommended)
- example: utf8mb4_0900_ai_ci - UCA 5.2.0 (not recommended, see problems below)
- example: utf8mb4_unicode_520_ci
The default collation in MySQL 8.0 is utf8mb4_0900_ai_ci
Now let's have a look at what those collations are used for. We start with creating a table like this:
CREATE TABLEcollation_exid0900_ai_ci varchar(50) CHARACTER SET utf8mb4 0900_ai_ciCOLLATE utf8mb4_0900_ai_ci DEFAULT NULL, unicode_520_ci varchar(50) CHARACTER SET utf8mb4 unicode_520_ciCOLLATE utf8mb4_unicode_520_ci DEFAULT NULL, general_ci varchar(50) CHARACTER SET utf8mb4 general_ciCOLLATE utf8mb4_general_ci DEFAULT NULL,id(collation_exid0900_ai_ci varchar(50) CHARACTER SET utf8mb4 0900_ai_ciCOLLATE utf8mb4_0900_ai_ci DEFAULT NULL, unicode_520_ci varchar(50) CHARACTER SET utf8mb4 unicode_520_ciCOLLATE utf8mb4_unicode_520_ci DEFAULT NULL, general_ci varchar(50) CHARACTER SET utf8mb4 general_ciCOLLATE utf8mb4_general_ci DEFAULT NULL,idint NOT NULL AUTO_INCREMENT,collation_exid0900_ai_ci varchar(50) CHARACTER SET utf8mb4 0900_ai_ciCOLLATE utf8mb4_0900_ai_ci DEFAULT NULL, unicode_520_ci varchar(50) CHARACTER SET utf8mb4 unicode_520_ciCOLLATE utf8mb4_unicode_520_ci DEFAULT NULL, general_ci varchar(50) CHARACTER SET utf8mb4 general_ciCOLLATE utf8mb4_general_ci DEFAULT NULL,idcollation_exid0900_ai_ci varchar(50) CHARACTER SET utf8mb4 0900_ai_ciCOLLATE utf8mb4_0900_ai_ci DEFAULT NULL, unicode_520_ci varchar(50) CHARACTER SET utf8mb4 unicode_520_ciCOLLATE utf8mb4_unicode_520_ci DEFAULT NULL, general_ci varchar(50) CHARACTER SET utf8mb4 general_ciCOLLATE utf8mb4_general_ci DEFAULT NULL,idcollation_exid0900_ai_ci varchar(50) CHARACTER SET utf8mb4 0900_ai_ciCOLLATE utf8mb4_0900_ai_ci DEFAULT NULL, unicode_520_ci varchar(50) CHARACTER SET utf8mb4 unicode_520_ciCOLLATE utf8mb4_unicode_520_ci DEFAULT NULL, general_ci varchar(50) CHARACTER SET utf8mb4 general_ciCOLLATE utf8mb4_general_ci DEFAULT NULL,idcollation_exid0900_ai_ci varchar(50) CHARACTER SET utf8mb4 0900_ai_ciCOLLATE utf8mb4_0900_ai_ci DEFAULT NULL, unicode_520_ci varchar(50) CHARACTER SET utf8mb4 unicode_520_ciCOLLATE utf8mb4_unicode_520_ci DEFAULT NULL, general_ci varchar(50) CHARACTER SET utf8mb4 general_ciCOLLATE utf8mb4_general_ci DEFAULT NULL,idPRIMARY KEY (collation_exid0900_ai_ci varchar(50) CHARACTER SET utf8mb4 0900_ai_ciCOLLATE utf8mb4_0900_ai_ci DEFAULT NULL, unicode_520_ci varchar(50) CHARACTER SET utf8mb4 unicode_520_ciCOLLATE utf8mb4_unicode_520_ci DEFAULT NULL, general_ci varchar(50) CHARACTER SET utf8mb4 general_ciCOLLATE utf8mb4_general_ci DEFAULT NULL,id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
We can see that we have 3 varchar columns using different collations where the first 2 are UCA compliant (even if the second is less).
Let's see the content of that table:
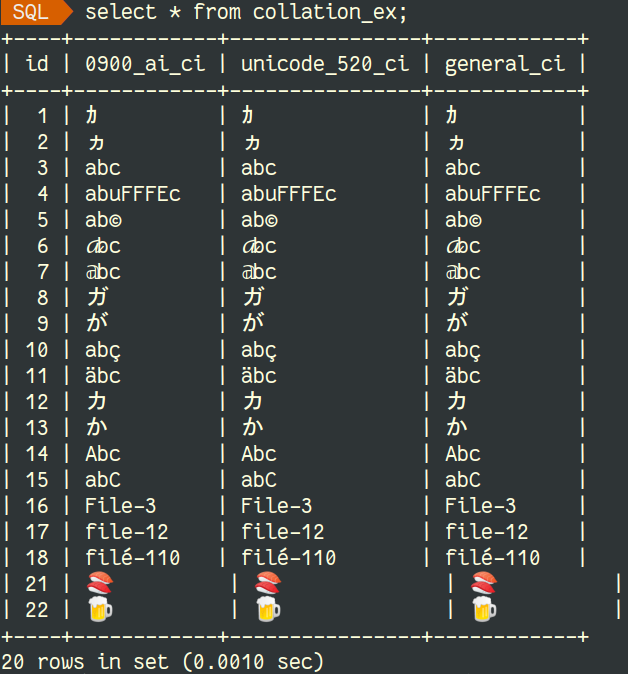
Now let's see the difference when we sort them using those varchar columns:
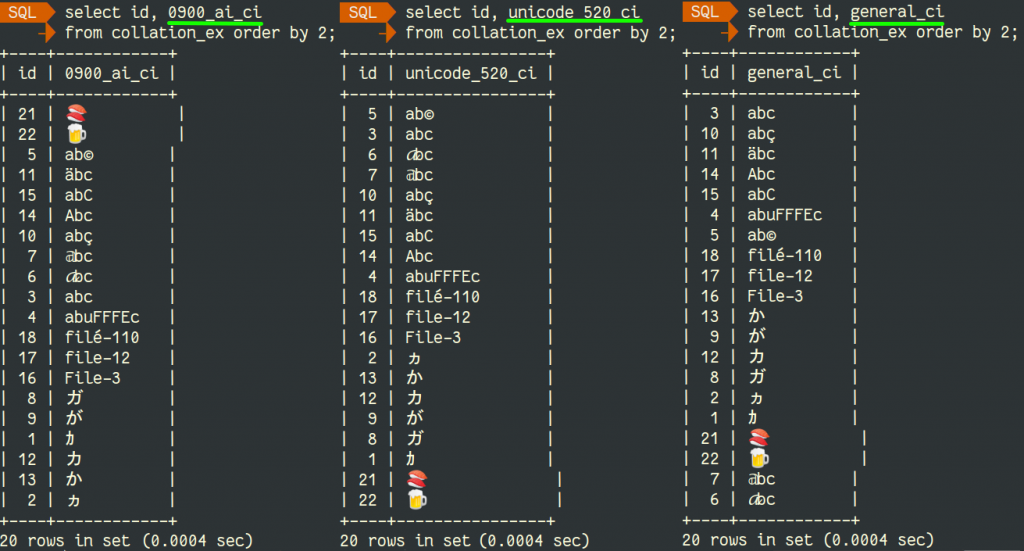
We can see the difference and notice that the sorting using the default MySQL 8.0 collation (utf8mb4_0900_ai_ci, on the first column) is the one giving the correct result. This UCA compliant collation is sorting the different 'a' as 'a'. We can also notice difference in ordering the Japanese characters.
For more information about UCA support in MySQL and why the correct results are important take a look at those previous post by my colleagues in the engineering team:
- Sushi = Beer ?! An introduction of UTF8 support in MySQL 8.0
- MySQL 8.0 Collations: The devil is in the details
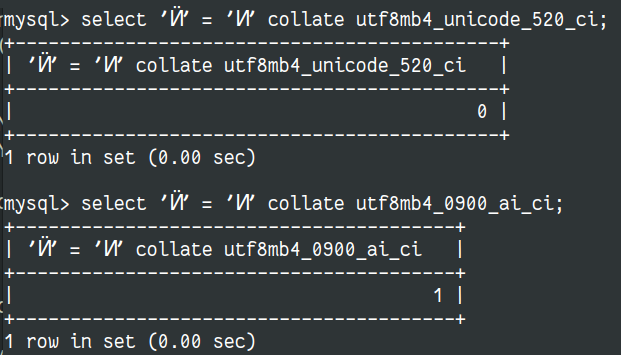
Let's have a look at another example with Cyrillic characters to illustrate the difference between the Unicode 5.2 and 9.0:
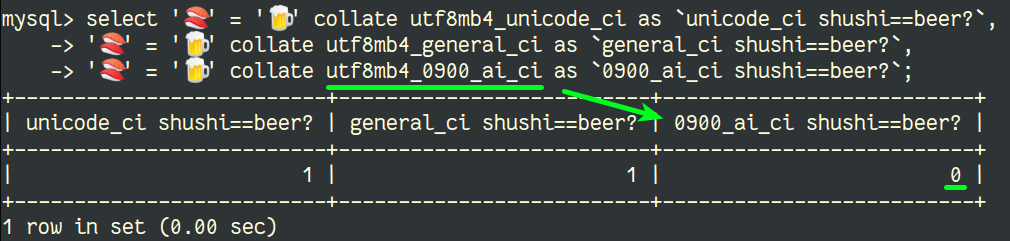
Of course I could not write a blog post on Charsets and Collations without showing the famous Shushi = Beer example:
If you don't remember what _as and _ci mean in the collation name, this means accent sensitive and case insensitive.
The accent sensitivity over Unicode charsets can be illustrated for example with some Japanese words where it takes all its importance:
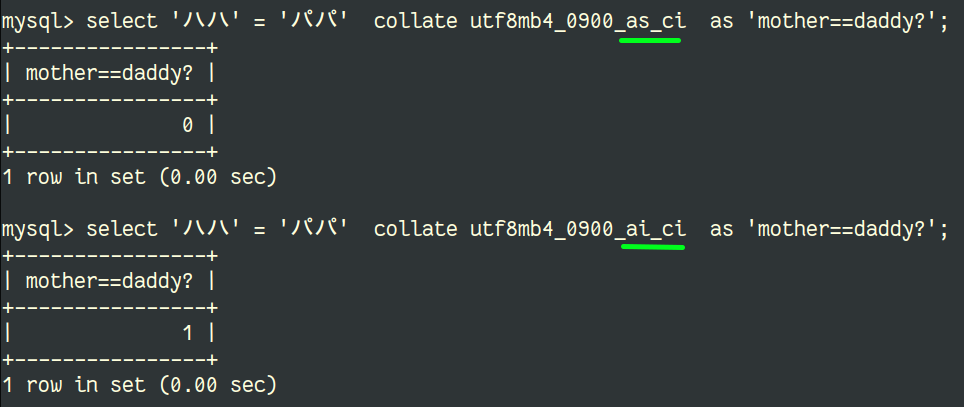
I hope this clarifies a bit why using UCA compliant collations (default in MySQL 8.0) is important and why we are focusing on those and not anymore on old utf8 collations that are not UCA compliant.
Currently MySQL 8.0 support 49 utf8mb4 collations compatible with UCA 9.0.0. To get the list just run the following statement:
mysql> show collation like 'u%900%';Thank you for using MySQL !
In summary:
we recommend using:
- utf8mb4_0900_*
- utf8mb4_binplease do not use:
- utf8_* (no support for Emoji, missing CJK characters, etc)
- utf8mb3 (no support for Emoji, missing CJK characters, etc)
- utf8mb4_general_ci (have problems like the Sushi-Beer explained above)
- utf8mb4_unicode_ci (have problems like the Sushi-Beer explained above)
- utf8mb4_unicode_520_ci: (have problems like Mother-Daddy issue, for Japanese as if it matches characters of p sound and b sound and cannot be resolved)