In 8.0 we have introduced another bunch of parser refactoring worklogs:
- WL#8067 (me): “Refactoring of the CREATE TABLE statement” with its subtasks:
- WL#8907 (me): Parser refactoring: merge all SELECT rules into one.
- WL#8083 (Martin Hansson): Introduce <query expression> parser rule.
As usual, the first goal of that refactoring is a simplification and deduplication of parser grammar rules.
In the current turn we concentrated on the deduplication of grammar parts related to the SELECT statement, unions and subqueries in all kinds of statements.
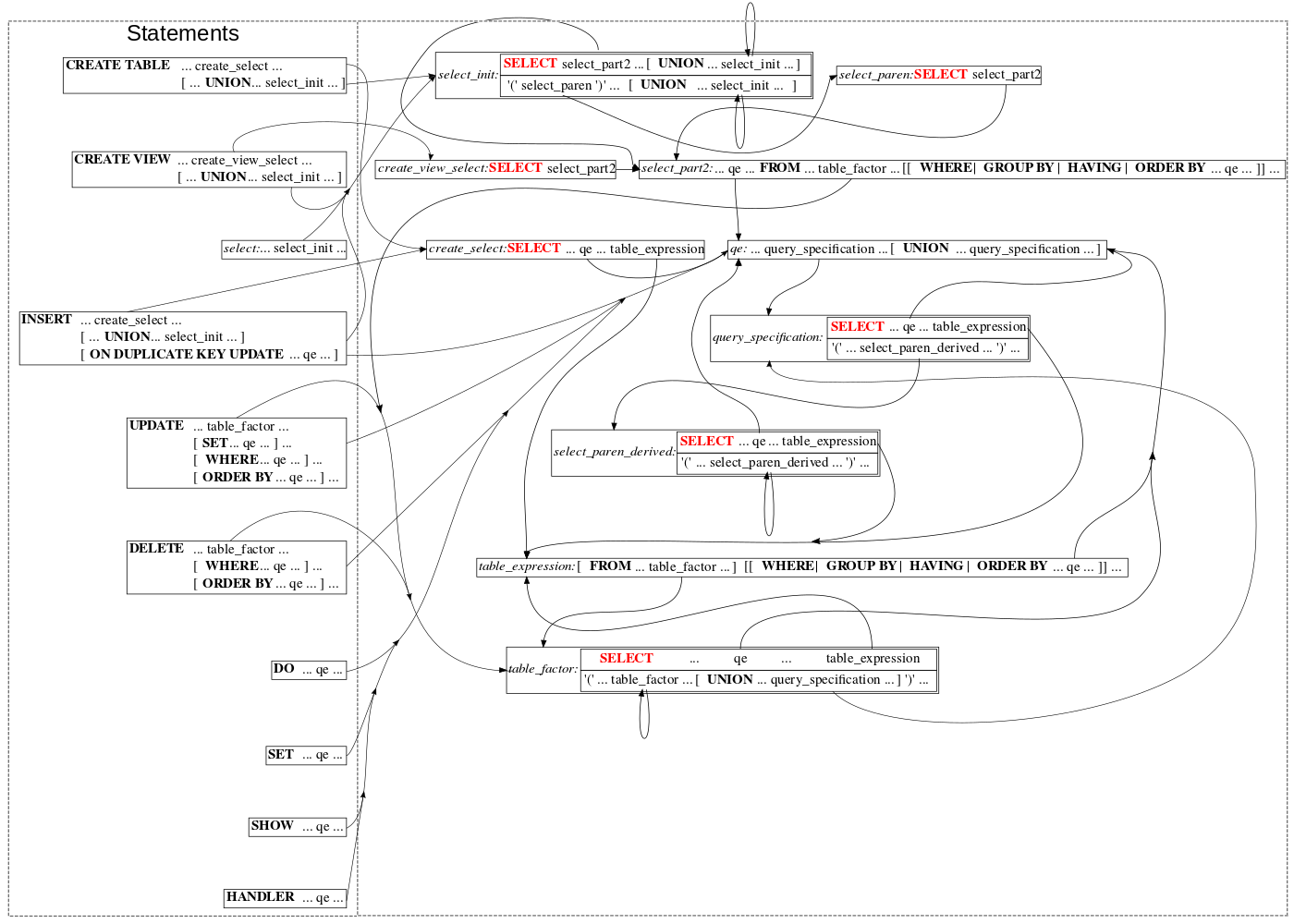
In the original parser, before this refactoring, we had a few different grammar rules:
- one rule for the topmost SELECT in the CREATE TABLE … SELECT statement,
- one unique SELECT for the topmost SELECT in CREATE VIEW,
- a different one for the topmost SELECT in regular SELECT statements,
- another one for some SELECT instances in parentheses, not including:
- one for derived tables,
- a separate one for subqueries in expressions: single-row subqueries and subqueries in ALL/ANY/IN/EXISTS expressions,
and there were varieties of combinations of these things in different contexts, and those combinations were out of sync.
In other words, we had a dozen different implementations of query specification (“SELECT”) and query expression (“UNION”) grammars! So, all the time we had a lot of fun with major and minor incompatibilities:
- incompatible syntax or partial support for unions in different parts of different statements,
- partial support for SELECT in parentheses,
- partial support for the reduced form of SELECT FROM DUAL in some statements etc.
Mentioned worklogs did a big consolidation and harmonization: now we use only one rule for all kinds of query specifications and only one rule for all kinds of query expressions in all use cases.
BEFORE:
AFTER:
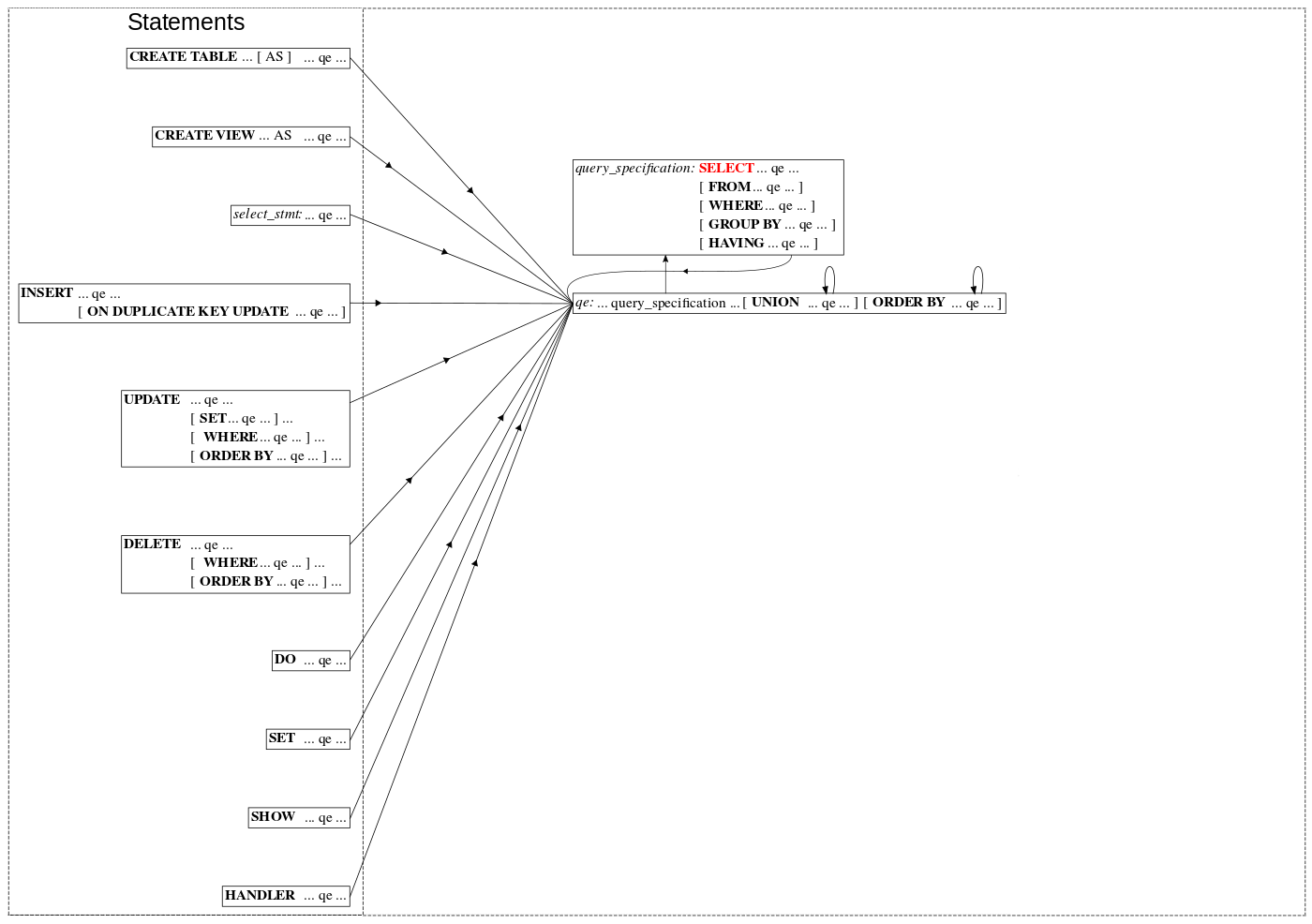
Many thanks to Martin Hansson and Roy Lyseng for a work on WL#8083 — a big part of
the grammar deduplication, and to Roy for reviewing the rest!
Benefits of the current refactoring:
- a uniform query specification & query expression syntax in any context: this helped to close old bug reports
- smaller grammar to support and extend
- less ambiguities (shift/reduce conflicts) in the grammar
- less use of a parse-time intermediate data
Below there are some details about the last two benefits.
Some statistics about grammar conflicts
This is interesting that the early MySQL 3.32 grammar had only 24 shift/reduce conflicts.
However, 4.0 has introduced even more: 95 shift/reduce in total. And even worse, there were 4 reduce/reduce conflicts — in practice the reduce/reduce ambiguity means that some rule exists in the grammar but there is no way to reach it (dead code).
These reduce/reduce conflicts were eliminated in 4.1, but that release introduced a huge number of new shift/reduce conflicts instead: 366 s/r in total!
5.0 was the fist branch where the number of ambiguities started to decrease: finally there are 240 expected s/r in total, good job!
Obviously, this is much easier to introduce new ambiguities than remove existent ones without compatibility issues, so after 5.0 the conflict removal progress was not so notable. OTOH in 8.0 we have removed 3 times more than in all 5.1 … 5.7 together (most of the conflicts in 8.0-labs were removed by Martin’s work on WL#8083):
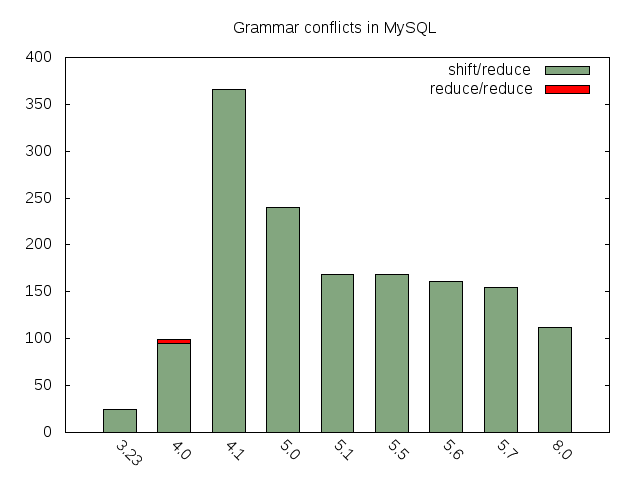
In other words, we are doing our best to reject any new ambiguities, and the refactoring helps us to lower the number of existent ones.
Lesser usage of intermediate data in LEX
The root object of our AST (Abstract Syntax Tree) is an object of the LEX class. Historically, that class consists of many fields, and almost all of them are just intermediate parse-time variables.
Generally speaking, this is not good to have so many temporary parse-time things in the executor’s AST. However, there is something worse than the memory bloating there: the usage of most of fields belong to very limited subsets of grammar rules, and those fields are meaningless for the rest of the grammar. Moreover, often the initialization and cleanup of those fields is a responsibility of some rule in the depth of the grammar — sometimes we keep up unnatural empty grammar rules to reset such field values in between parts of the SQL statement text. This is really easy to forget and miss a cleanup there, so those fields were always sources of bugs in the past.
The situation was aggravated by the fact that some field could be shared between unrelated groups of grammar rules in non-obvious ways: it’s easy to break something if you reuse an existent part of the grammar in a new context.
To drop that historical practice, we are trying to make a new part of LEX fields local to their grammar rules in every new parser refactoring worklog. WL#8067 is no exception to this rule, it moves out a dozen of LEX fields:
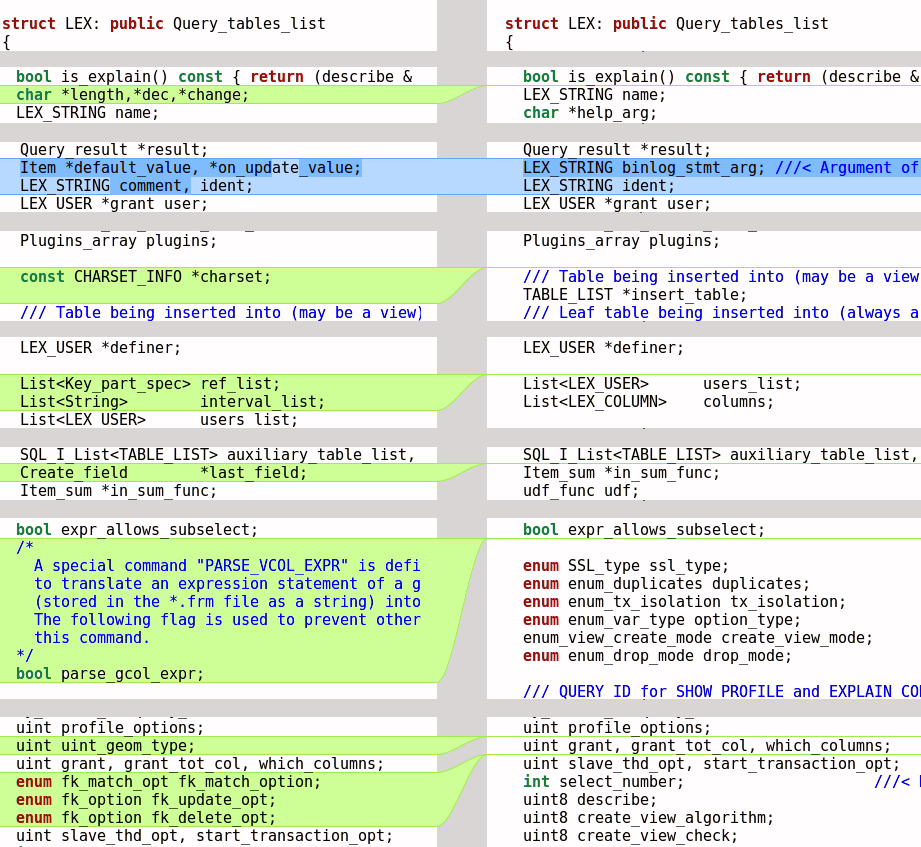
Conclusion
Please try out these changes in the MySQL 8.0.0 milestone release, and let us know your feedback. Thank you for using MySQL!