To support the new feature Partial Update of JSON documents, InnoDB changed the way it stored the large objects (LOBs) in MySQL 8.0. This is because InnoDB does not have a separate JSON data type and stores JSON documents as large objects. This also means that at InnoDB level, partial update of any BLOB or TEXT column is supported. But, as of now, the end users cannot take advantage of this because there is no syntax to access this generically for BLOB or TEXT columns. Currently this feature is available only for JSON documents via the json_set() and json_replace() functions.
In this article, I’ll present the new storage format of the uncompressed LOB. I’ll write about compressed LOB in a subsequent article. Refer to my previous article Externally Stored Fields in InnoDB, about some basic information about LOBs in InnoDB.
Old Format of Uncompressed LOB
Let us look at the old format briefly in this section. Refer to the following figure.
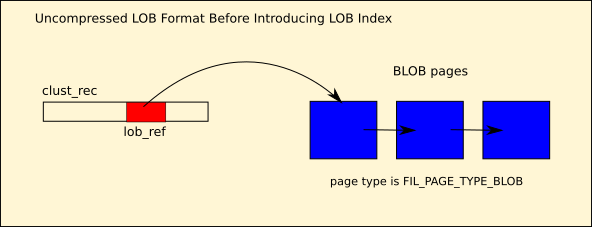
The above figure pictorially presents the older storage format of BLOBs in InnoDB. The clustered index record will contain 0, 1 or more number of LOB references. Each LOB reference will point to the first page of the LOB. The first page of a LOB will contain a reference to the second page of LOB, the second page of LOB will contain a reference to the third page of LOB and so on. This forms a singly linked list of LOB data pages. The page type of these LOB data pages is FIL_PAGE_TYPE_BLOB. The complete LOB is made up of a single type of data pages.
The limitation in this format was that the various offsets within the LOB are to be accessed only sequentially. For example, if we have to access a portion of LOB that falls within the 3rd page of the LOB, then this portion can be accessed only by first accessing the first page of LOB, and then visiting the 2nd page of LOB and then only the 3rd page can be accessed. Of course, the various offsets within a single LOB data page can be accessed randomly, but this is not good enough. If the LOB is bigger containing 20 pages, then the overhead of accessing a small portion in the last page of LOB is much higher. The problem keeps getting worse, as the size of LOB gets bigger.
We needed a more efficient way to randomly access various portions of an LOB, irrespective of its size. Hence the need to change the storage format of LOBs. What we did was to introduce an LOB index to help access different parts of an LOB more efficiently.
New Format of Uncompressed LOB
Previously, LOB data pages were singly linked list of data pages. The various offsets of a LOB could be accessed only by sequentially reading the LOB pages. The new format introduces the LOB index, which helps to provide random access to the JSON document.
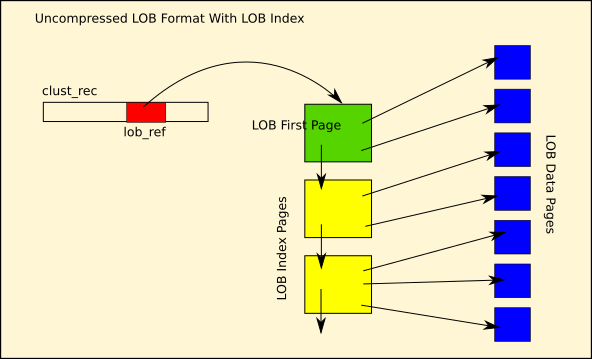
As can be seen from the figure, the clustered index record contains an LOB reference. But the LOB reference points to a new type of page called the LOB first page, and from there we have a list of LOB index pages. These two types of pages constitute the LOB index, and this LOB index contains references to the LOB data pages.
LOB Index
The LOB index is newly introduced to provide a more random access to the LOB. The LOB index is a doubly linked list implemented by making use of the file based list utility flst_base_node_t and flst_node_t. Each entry of an LOB index is a file list node representing one LOB data page. The LOB index entry contains the following information:
- Pointer to the previous index entry.
- Pointer to the next index entry.
- Pointer to the list of old versions for this index entry.
- The creator transaction identifier.
- The modifier transaction identifier
- The undo number of creator transaction.
- The undo number of modifier transaction.
- The page number of LOB data page.
- The amount of LOB data it contains in bytes.
- The LOB version number to which this index entry belongs.
For the sake of completeness, I listed out all the contents of a single LOB index entry. In this article, we will only look at the following → pointer to the next index entry, the page number of the LOB data page, and the amount of LOB data it contains. I hope to explain the use of other information stored in a separate article.
An Example
It is easier to populate data using an mtr test case and look at the LOB index. The following mtr test case can be used to print the LOB index into the server error log file.
|
1 2 3 4 5 6 |
--source include/have_debug.inc CREATE TABLE t(j1 longblob); set debug='+d,innodb_lob_print'; INSERT INTO t VALUES (repeat('x', 81920)); set debug='-d,innodb_lob_print'; drop table t; |
In the server error log you will find the LOB index printed. The LOB size used above is 81920 (16K * 5). The number of index entries is 6. Their details are given below:
| S. No. | Previous Index Entry | Next Index Entry | LOB Data Page Number | Data Available (in bytes) |
|---|---|---|---|---|
| 1 | page=4294967295, boffset=0 | page=5, boffset=156 | 5 | 15680 |
| 2 | page=5, boffset=96 | page=5, boffset=216 | 6 | 16327 |
| 3 | page=5, boffset=156 | page=5, boffset=276 | 7 | 16327 |
| 4 | page=5, boffset=216 | page=5, boffset=336 | 8 | 16327 |
| 5 | page=5, boffset=276 | page=5, boffset=396 | 9 | 16327 |
| 6 | page=5, boffset=336 | page=4294967295, boffset=0 | 10 | 932 |
The LOB reference contained the following information [space_id=2, page_no=5, length=81920]. So the first page of LOB is page number 5. The first page of an LOB is special in the sense that it contains both LOB index and LOB data and this is the page referenced in the LOB reference object in the clustered index record. In this example, we can see that all the LOB index entries are available in the first page itself. The following figure presents this data for your easy understanding.
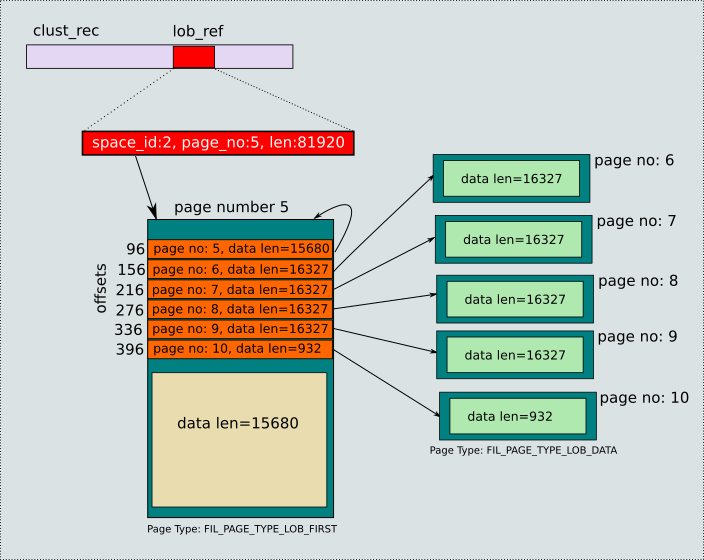
Here are some observations in this example:
- A total number of 6 pages are used. The total number of LOB index entries are 6.
- There is 1 LOB first page of type FIL_PAGE_TYPE_LOB_FIRST and 5 LOB data pages of type FIL_PAGE_TYPE_LOB_DATA. In this example, no page type of FIL_PAGE_TYPE_LOB_INDEX is used because the LOB is not big enough.
- No explicit offset information is stored in the LOB index, but it can be calculated based on the amount of data stored in each of the LOB data page.
- The order of the LOB index entries is important. The data represented by the first index entry comes first in the total LOB, the data represented by the second index entry comes immediately after the first and so on.
New Page Types
There are now 3 different page types in an LOB. They are listed below:
| Page Type | Description |
|---|---|
| FIL_PAGE_TYPE_LOB_FIRST | The first page of an uncompressed LOB. It contains both LOB index entries and LOB data. This is the page number mentioned in the LOB reference stored in clustered index record. The next page (FIL_PAGE_NEXT) of the first page is an LOB index page. |
| FIL_PAGE_TYPE_LOB_INDEX | These LOB pages hold only index entries. It will contain as many index entries as possible. All these index pages are linked to each other via the FIL_PAGE_NEXT page header field. |
| FIL_PAGE_TYPE_LOB_DATA | These are the pages that hold LOB data. Each LOB data page is pointed to by an index entry. The number of LOB data page is equal to the number of entries in the LOB index. |
Locating a Given Offset Within LOB
The primary purpose of the LOB index is to efficiently locate an offset within an LOB. Given the LOB and the offset, it should be efficient to calculate the page number in which that offset is located. Let us look at the algorithm to do the same.
The input given is the LOB reference and the offset. The output expected is the LOB index entry that represents the LOB data page containing the given offset. As I have mentioned earlier, each LOB index entry represents exactly one LOB data page and vice versa.
Traverse the list of LOB index entries and keep adding the data available in each of them. This also represents the start offset and end offset in each of the LOB data page. Using this it is easy to locate the LOB data page containing the given offset. For the given example, let us calculate the offsets for each of the LOB data pages.
| S.No | Next Index Entry | LOB Data Page Number | Data Available (in bytes) | Start Offset | |
|---|---|---|---|---|---|
| 1 | page=5, boffset=156 | 5 | 15680 | 0 | |
| 2 | page=5, boffset=216 | 6 | 16327 | 15680 | |
| 3 | page=5, boffset=276 | 7 | 16327 | 32007 | |
| 4 | page=5, boffset=336 | 8 | 16327 | 48334 | |
| 5 | page=5, boffset=396 | 9 | 16327 | 64661 | |
| 6 | page=4294967295, boffset=0 | 10 | 932 | 80988 |
The last column gives the start offset of the data in each of the LOB data pages. Its value is got by adding the available data in each of the data pages. Suppose the given offset is 66666, then we can easily see that the LOB data page that contains this offset is page number 9.
Goal Was Performance
The whole purpose of doing this LOB storage format change was to support the partial update of json documents feature, which is all about performance. Previously when a small portion of JSON document was updated with JSON_SET() or JSON_REPLACE(), the whole JSON document was modified, redo logged and bin logged. But with this feature, we reduce the redo log and bin log generation, making the whole operation much faster. To achieve this InnoDB has introduced the LOB index pages, which contains meta data about the LOB data pages. This new storage format was explained in this article. There is much more to explain (especially MVCC on LOB) which I’ll take it up in subsequent articles.
Here is an internal performance test report from our System QA team, which I would like to present here. They have run a modified version of sysbench — the JSON document size was adjusted so that they are big enough to demonstrate the benefit of partial update feature. I hope you can repeat tests and get the same performance benefits.
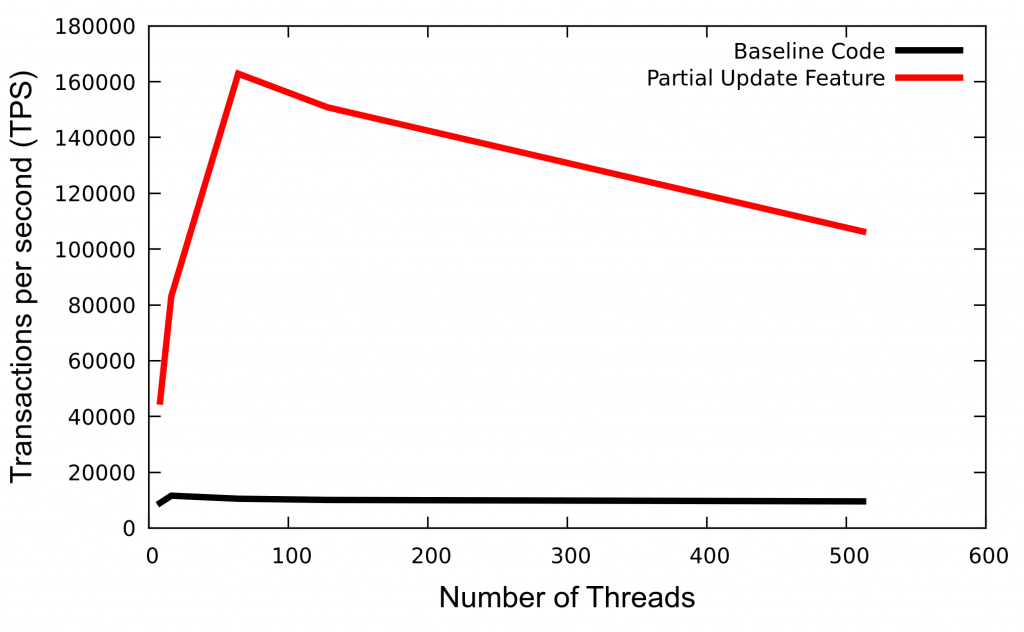
The black line was the baseline and the red line is the performance gain from this feature.
| Threads | Average TPS with the baseline code | Average TPS with Partial Update of BLOBs feature | Percentage Improvement |
|---|---|---|---|
| 8 | 9007.593 | 45368.317 | 403.67% |
| 16 | 11627.067 | 83082.127 | 614.56% |
| 64 | 10524.580 | 162884.660 | 1,447.66% |
| 128 | 10093.880 | 150841.183 | 1,394.38% |
| 512 | 9576.630 | 106293.767 | 1,009.93% |
The gain is seen from 403.67% to 1,009.93%. The sysbench was modified to use a bigger JSON document and the UPDATE statements were made to use JSON_SET() and JSON_REPLACE() whenever possible. Hopefully this is a common use case scenario, and if it is, everybody gets to benefit.
Conclusion
In this article we looked at the new storage format of large objects in InnoDB. This new format was needed to support the partial update feature of JSON documents. The basic idea was to introduce an LOB index for each of the large objects, which helps to do random access of various parts of LOBs more efficiently. And since the goal was performance, the results of an internal performance testing has been presented here.
If you found this useful, kindly leave a comment!
Thank you for using MySQL !