MySQL’s multi-source replication allows you to replicate data from multiple databases into one database in parallel (at the same time). This post will explain and show you how to set up multi-source replication. (WARNING: This is a very long and detailed post. You might want to grab a sandwich and a drink.)
In most replication environments, you have one master database and one or more slave databases. This topology is used for high-availability scenarios, where the reads and writes are split between multiple servers. Your application sends the writes to the master, and reads data from the slaves. This is one way to scale MySQL horizontally for reads, as you can have more than one slave. Multi-source replication allows you to write to multiple MySQL instances, and then combine the data into one server.
Here is a quick overview of MySQL multi-source replication:
MySQL Multi-Source Replication enables a replication slave to receive transactions from multiple sources simultaneously. Multi-source replication can be used to back up multiple servers to a single server, to merge table shards, and consolidate data from multiple servers to a single server. Multi-source replication does not implement any conflict detection or resolution when applying the transactions, and those tasks are left to the application if required. In a multi-source replication topology, a slave creates a replication channel for each master that it should receive transactions from. (from https://dev.mysql.com/doc/refman/5.7/en/replication-multi-source-overview.html)
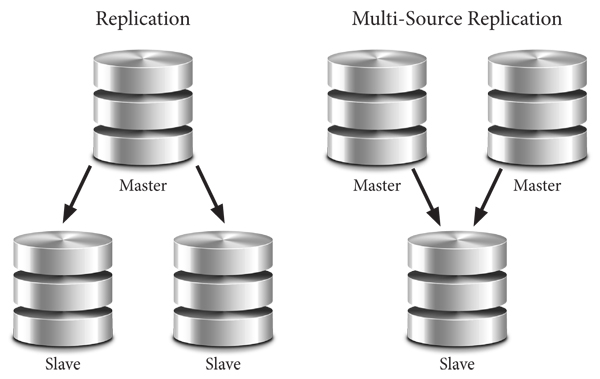
In this post, I will demonstrate how to setup multi-source replication with two masters and one slave (as shown in the right side of the above picture). This will involve a new installation of MySQL 5.7.10 for each server.
I am not going to explain how to install MySQL, but you do need to follow the post-installation instructions for your operating system. If you don’t run the mysqld initialize post-installation process for each install, you will run into a lot of problems (I will explain this later). I will start with what you need to do post-installation, after the server is up and running. In this example, I have turned off GTID’s, and I will enable GTID later in the process. I am going to assume you have some knowledge on how to setup replication, what GTID’s are, and how replication works. I will also show you some errors you may encounter.
Prior to installation, you will need to make sure the repositories on the slave are being stored in a table. I have this enabled on all three servers, but it is only required for the slave. If you don’t have this enabled, you can enable it via your configuration (my.cnf or my.ini) file:
|
1
2
3
|
[mysqld] master-info-repository=TABLE relay-log-info-repository=TABLE |
If you did not enable this earlier, you will want to modify your configuration file and restart MySQL. You can check to see if this is enabled via this command:
|
1
2
3
4
5
6
7
8
|
mysql> SHOW VARIABLES LIKE '%repository%'; +---------------------------+-------+ | Variable_name | Value | +---------------------------+-------+ | master_info_repository | TABLE | | relay_log_info_repository | TABLE | +---------------------------+-------+ 2 rows in set (0.00 sec) |
You will also need to modify your configuration files (my.cnf or my.ini) to make sure each server has a unique server_id. I use the last three digits of the IP address for each server as my server_id, as in this example:
|
1
2
|
[mysqld] server-id=141 |
To view the server_id for a given server, execute this command:
|
1
2
3
4
5
6
7
|
mysql> SHOW VARIABLES WHERE VARIABLE_NAME = 'server_id'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | server_id | 141 | +---------------+-------+ 1 row in set (0.00 sec) |
I will be using three servers, and each one has MySQL 5.7.10 installed:
Server #1 – Slave – IP 192.168.1.141
Server #2 – Master #1 – IP 192.168.1.142
Server #3 – Master #2 – IP 192.168.1.143
I will refer to each of these servers as either Slave, Master #1 or Master #2.
NOTE: With MySQL 5.7, if you use a GUI-installation, a password is generated for root during the install process, and it should appear in the installation GUI. If you don’t see the password, it will be in your error log file. Also, when you run the post-installation process, a new root password may be generated again, and this password will also be located in your error log file.
|
1
2
|
# grep root error.log 2015-12-09T05:34:01.639797Z 1 [Note] A temporary password is generated for root@localhost: T<e-hd0cgI!d |
You will need this password to continue using MySQL, and you will need to change it before issuing any other commands. Here is the command to change the password for root:
|
1 |
ALTER USER 'root'@'localhost' IDENTIFIED BY 'password';</font> |
The key to making multi-source replication work is to ensure you don’t have the same primary keys on your two masters. This is true especially if you are using AUTO_INCREMENT columns. If both masters have the same primary key for two different records, the data could be corrupted once it reaches the slave. I will show you one way to setup alternating key values using AUTO_INCREMENT. Of course, there are other ways to do this, including having your application generate the value for the keys.
If you don’t turn off GTID’s (via your configuration file) prior to running the post-installation steps, you will encounter a problem in that GTID’s will be created for the mysqld initialize process, and these transactions will be replicated to the slave. Let’s assume you enabled GTID’s from the start, before you ran the post-installation steps, and then you attempted to start replication on the slave. When you run the SHOW MASTER STATUS command, you will see something like this, showing you the 138 transactions which were executed on the master, and would now be replicated to the slave:
|
1
2
3
4
5
6
7
8
|
mysql> SHOW MASTER STATUS\G *************************** 1. row *************************** File: mysql-bin.000002 Position: 1286 Binlog_Do_DB: Binlog_Ignore_DB: Executed_Gtid_Set: 73fdfd2a-9e36-11e5-8592-00a64151d129:1-138 1 row in set (0.00 sec) |
On the slave, you would see an error in the SHOW SLAVE STATUS:
|
1 |
Last_Error: Error 'Can't create database 'mysql'; database exists' on query. Default database: 'mysql'. Query: 'CREATE DATABASE mysql; |
And the RETRIEVED GTID SET would look like this, showing you the 138 transactions which have already been copied to the slave.
|
1
2
3
4
|
mysql> SHOW SLAVE STATUS\G ... Retrieved_Gtid_Set: 73fdfd2a-9e36-11e5-8592-00a64151d129:1-138 ... |
You can attempt to skip these transactions, but it is much easier to wait and enable GTID’s later.
After the post-installation steps, you will get the same results on all three servers for a SHOW MASTER STATUS command:
|
1
2
3
4
5
6
7
8
|
mysql> SHOW MASTER STATUS\G *************************** 1. row *************************** File: mysql-bin.000002 Position: 398 Binlog_Do_DB: Binlog_Ignore_DB: Executed_Gtid_Set: 1 row in set (0.00 sec) |
Next, you will need to create the replication user on each of the master servers (where 192.168.1.141 is the IP address of your slave).
|
1
2
3
4
5
|
mysql> CREATE USER 'replicate'@'192.168.1.141' IDENTIFIED BY 'password'; Query OK, 0 rows affected (0.05 sec) mysql> GRANT REPLICATION SLAVE ON *.* TO 'replicate'@'192.168.1.141'; Query OK, 0 rows affected (0.01 sec) |
After, you can see the additional changes (from creating the user and granting permissions) to the binary log via the SHOW MASTER STATUS command:
|
1
2
3
4
5
6
7
8
|
mysql> show master status\G *************************** 1. row *************************** File: mysql-bin.000002 Position: 873 Binlog_Do_DB: Binlog_Ignore_DB: Executed_Gtid_Set: 1 row in set (0.00 sec) |
Now we are ready to create our schemas on the slave and the master servers. For this example, I have created a small table to be used for storing information about a comic book collection. Here are the CREATE DATABASE and CREATE TABLE commands:
Slave
|
1
2
3
4
5
6
7
8
9
10
|
CREATE DATABASE `comicbookdb`; use comicbookdb; CREATE TABLE `comics` ( `comic_id` int(9) NOT NULL AUTO_INCREMENT, `comic_title` varchar(60) NOT NULL, `issue_number` decimal(9,0) NOT NULL, `pub_year` varchar(60) NOT NULL, `pub_month` varchar(60) NOT NULL, PRIMARY KEY (`comic_id`) ) ENGINE=InnoDB AUTO_INCREMENT=1; |
You can use the same SQL to create tables on the slave as you do on the master. Since we will using AUTO_INCREMENT values on the master, you might think you would not want to use AUTO_INCREMENT in the CREATE TABLE statement on the slave. But, since we will not be doing any writes to the slave, you can use the same CREATE TABLE statement as you use on a master. You will only need to modify the CREATE TABLE statements for the masters to create alternate primary keys values. (More on this later)
When the data replicates to the slave from the master, replication will handle the AUTO_INCREMENT columns.
Here is what happens when you create the comics table on the slave without specifying the AUTO_INCREMENT for the comic_id column, and then you start replication. From the SHOW SLAVE STATUS\G command:
|
1
2
3
|
mysql> SHOW SLAVE STATUS\G... Last_SQL_Error: Error 'Field 'comic_id' doesn't have a default value' on query. Default database: 'comicbookdb'. Query: 'INSERT INTO COMICS (comic_title, issue_number, pub_year, pub_month) VALUES('Fly Man','5','2014','03')' ... |
We now need to find a way to create different and alternating values for our primary key column – comic_id. You could have your application do this, but an easy way is to use the auto_increment_increment variable. In your configuration file (my.cnf or my.ini), you will want to add this for both master databases:
|
1
2
|
[mysqld] auto_increment_increment = 2 |
Adding this variable will require a reboot of MySQL. But, you can set it during the mysql session if you don’t want to reboot. Just make sure to add it to your configuration file (my.cnf or my.ini), or it won’t take effect after the session ends.
|
1
2
|
mysql> SET @@auto_increment_increment=2; Query OK, 0 rows affected (0.00 sec) |
You can verify to see if this variable is enabled with this command:
|
1
2
3
4
5
6
7
|
mysql> SHOW VARIABLES WHERE VARIABLES_NAME = 'auto_increment_increment'; +-----------------------------+-------+ | Variable_name | Value | +-----------------------------+-------+ | auto_increment_increment | 2 | +-----------------------------+-------+ 1 row in set (0.00 sec) |
The auto_increment_increment variable will increment the AUTO_INCREMENT value by two (2) for each new primary key value. We will also need to use different initial primary key values for each master. You can’t simply use 0 (zero) and 1 (one) for the AUTO_INCREMENT value, as when you use the value of 0 (zero), it defaults back to a value of 1 (one). It is easier to set the AUTO_INCREMENT values to a higher number, with the last digits being 0 (zero) and 1 (one) for each master. Here are the CREATE DATABASE and CREATE TABLE commands for each master:
Master #1
|
1
2
3
4
5
6
7
8
9
10
|
CREATE DATABASE `comicbookdb`; use comicbookdb; CREATE TABLE `comics` ( `comic_id` int(9) NOT NULL AUTO_INCREMENT, `comic_title` varchar(60) NOT NULL, `issue_number` decimal(9,0) NOT NULL, `pub_year` varchar(60) NOT NULL, `pub_month` varchar(60) NOT NULL, PRIMARY KEY (`comic_id`) ) ENGINE=InnoDB AUTO_INCREMENT=100000; |
Master #2
|
1
2
3
4
5
6
7
8
9
10
|
CREATE DATABASE `comicbookdb`; use comicbookdb; CREATE TABLE `comics` ( `comic_id` int(9) NOT NULL AUTO_INCREMENT, `comic_title` varchar(60) NOT NULL, `issue_number` decimal(9,0) NOT NULL, `pub_year` varchar(60) NOT NULL, `pub_month` varchar(60) NOT NULL, PRIMARY KEY (`comic_id`) ) ENGINE=InnoDB AUTO_INCREMENT=100001; |
Now that we have all of our tables and users created, we can implement GTID’s on the master servers. I also implemented GTID’s on the slave, in case I wanted to add another slave to this slave. To enable GTID’s, I put the following my the configuration file (my.cnf or my.ini), and restarted MySQL. I added these variable below the auto_increment_increment variable.
|
1
2
3
4
|
[mysqld] auto_increment_increment = 2 gtid-mode = on enforce-gtid-consistency = 1 |
After you have restarted each server, you can take a look at the MASTER STATUS for each server, and the status should be the same:
|
1
2
3
4
5
6
7
8
|
mysql> SHOW MASTER STATUS\G *************************** 1. row *************************** File: mysql-bin.000005 Position: 154 Binlog_Do_DB: Binlog_Ignore_DB: Executed_Gtid_Set: 1 row in set (0.00 sec) |
You don’t have to do this, but I like to reset the master status on both masters and the slave. Resetting the master deletes all binary log files listed in the index file, resets the binary log index file to be empty, and creates a new binary log file. On each server (both masters and slave servers), I ran this:
|
1
2
3
4
5
6
7
8
9
10
11
|
mysql> RESET MASTER; Query OK, 0 rows affected (0.00 sec) mysql> SHOW MASTER STATUS\G *************************** 1. row *************************** File: mysql-bin.000001 Position: 154 Binlog_Do_DB: Binlog_Ignore_DB: Executed_Gtid_Set: 1 row in set (0.00 sec) |
You can see the new binary log (mysql-bin.000001), and the beginning position in the binary log (154). Let’s insert some data into one of the master databases, and then check the master’s status again. (And yes, we haven’t turned on replication yet).
Master #1
|
1
2
3
4
5
6
7
8
9
10
11
|
mysql> INSERT INTO COMICS (comic_title, issue_number, pub_year, pub_month) VALUES('Fly Man','1','2014','01'); Query OK, 1 row affected (0.02 sec) mysql> SHOW MASTER STATUS\G *************************** 1. row *************************** File: mysql-bin.000001 Position: 574 Binlog_Do_DB: Binlog_Ignore_DB: Executed_Gtid_Set: 63a7971c-b48c-11e5-87cf-f7b6a723ba3d:1 1 row in set (0.00 sec) |
You can see the GTID created for the INSERT statement – 63a7971c-b48c-11e5-87cf-f7b6a723ba3d:1. The first part of the GTID (63a7971c-b48c-11e5-87cf-f7b6a723ba3d) is the UUID of the master. The UUID information can be found in the auto.cnf file, located in the data directory.
Master #1
|
1
2
3
|
# cat auto.cnf [auto] server-uuid=63a7971c-b48c-11e5-87cf-f7b6a723ba3d |
Let’s insert another row of data, check the master status, and then look at the entries of the comics table:
Master #1
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
mysql> INSERT INTO COMICS (comic_title, issue_number, pub_year, pub_month) VALUES('Fly Man','2','2014','02'); Query OK, 1 row affected (0.05 sec) mysql> show master status\G *************************** 1. row *************************** File: mysql-bin.000001 Position: 994 Binlog_Do_DB: Binlog_Ignore_DB: Executed_Gtid_Set: 63a7971c-b48c-11e5-87cf-f7b6a723ba3d:1-2 1 row in set (0.00 sec) mysql> select * from comics; +----------+-------------+--------------+----------+-----------+ | comic_id | comic_title | issue_number | pub_year | pub_month | +----------+-------------+--------------+----------+-----------+ | 100001 | Fly Man | 1 | 2014 | 01 | | 100003 | Fly Man | 2 | 2014 | 02 | +----------+-------------+--------------+----------+-----------+ 2 rows in set (0.00 sec) |
You can see how the values for the comic_id table are now incremented by two (2). Now we can insert two lines of data into the second master, look at the master’s status, and look at the entries in the comics database:
Master #2
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
mysql> INSERT INTO COMICS (comic_title, issue_number, pub_year, pub_month) VALUES('Fly Man','3','2014','03'); mysql> INSERT INTO COMICS (comic_title, issue_number, pub_year, pub_month) VALUES('Fly Man','4','2014','04'); mysql> show master status\G *************************** 1. row *************************** File: mysql-bin.000005 Position: 974 Binlog_Do_DB: Binlog_Ignore_DB: Executed_Gtid_Set: 75e2e1dc-b48e-11e5-83bb-1438deb0d51e:1-2 1 row in set (0.00 sec) mysql> select * from comics; +----------+-------------+--------------+----------+-----------+ | comic_id | comic_title | issue_number | pub_year | pub_month | +----------+-------------+--------------+----------+-----------+ | 100002 | Fly Man | 3 | 2014 | 03 | | 100004 | Fly Man | 4 | 2014 | 04 | +----------+-------------+--------------+----------+-----------+ 2 rows in set (0.00 sec) |
The second master has a different UUID than the first master, and that is how we can tell what GTID’s belong to which master. We now have two sets of GTID’s to replicate over to the slave. Of course, the slave will have it’s own UUID as well.
Master #1 and Master #2 GTID sets:
|
1
2
|
63a7971c-b48c-11e5-87cf-f7b6a723ba3d:1-2 75e2e1dc-b48e-11e5-83bb-1438deb0d51e:1-2 |
I always check to make sure the slave isn’t running before I do anything:
Slave
|
1
2
|
mysql> show slave status\G Empty set (0.00 sec) |
Unlike regular replication, in multi-source replication, you have to create a CHANNEL specific to each master. You will need to also name this channel, and I simply named the channels “master-142” and “master-143” to match their server_id‘s (as well as their IP addresses). Here is how you start replication for Master #1 (server_id=142).
Slave
|
1
2
|
mysql> CHANGE MASTER TO MASTER_HOST='192.168.1.142', MASTER_USER='replicate', MASTER_PASSWORD='password', MASTER_AUTO_POSITION = 1 FOR CHANNEL 'master-142'; Query OK, 0 rows affected, 2 warnings (0.23 sec) |
This statement produced two warnings, but they can be ignored. I am following the same instructions on the MySQL Manual Page.
Slave
|
1
2
3
4
5
6
7
8
9
10
|
mysql> SHOW WARNINGS\G *************************** 1. row *************************** Level: Note Code: 1759 Message: Sending passwords in plain text without SSL/TLS is extremely insecure. *************************** 2. row *************************** Level: Note Code: 1760 Message: Storing MySQL user name or password information in the master info repository is not secure and is therefore not recommended. Please consider using the USER and PASSWORD connection options for START SLAVE; see the 'START SLAVE Syntax' in the MySQL Manual for more information. 2 rows in set (0.00 sec) |
Now we can start the slave for channel ‘master-142‘:
Slave
|
1
2
|
mysql> START SLAVE FOR CHANNEL 'master-142'; Query OK, 0 rows affected (0.03 sec) |
This command is the same as starting the SQL_THREAD and the IO_THREAD at the same time. There may be times when you will want to stop and stop either of these threads, so here is the syntax – as you have to specify which channel you want to modify:
|
1
2
|
START SLAVE SQL_THREAD FOR CHANNEL 'master-142'; START SLAVE IO_THREAD FOR CHANNEL 'master-142'; |
You can also issue a simple START SLAVE command, and it will start both threads for all currently configured replication channels. The slave has been started, and we should see the GTID’s from Master #1 already retrieved and applied to the database. (I am not going to display the entire SHOW SLAVE STATUS output, as it very long)
Slave
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
mysql> SHOW SLAVE STATUS FOR CHANNEL 'master-142'\G *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 192.168.1.142 ... Master_UUID: 63a7971c-b48c-11e5-87cf-f7b6a723ba3d ... Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates ... Retrieved_Gtid_Set: 63a7971c-b48c-11e5-87cf-f7b6a723ba3d:1-2 Executed_Gtid_Set: 63a7971c-b48c-11e5-87cf-f7b6a723ba3d:1-2 Auto_Position: 1 ... Channel_Name: master-142 |
We can take a look at the comics table, and see the two entries from the Master #1 database (channel master-142):
Slave
|
1
2
3
4
5
6
7
8
|
mysql> select * from comics; +----------+-------------+--------------+----------+-----------+ | comic_id | comic_title | issue_number | pub_year | pub_month | +----------+-------------+--------------+----------+-----------+ | 100001 | Fly Man | 1 | 2014 | 01 | | 100003 | Fly Man | 2 | 2014 | 02 | +----------+-------------+--------------+----------+-----------+ 2 rows in set (0.00 sec) |
Since we have the first master up and running with replication, let’s start replication for the second master:
|
1 |
CHANGE MASTER TO MASTER_HOST='192.168.1.143', MASTER_USER='replicate', MASTER_PASSWORD='password', MASTER_AUTO_POSITION = 1 FOR CHANNEL 'master-143'; |
And we can check the SLAVE STATUS for this master: (Again, not all of the results are displayed below)
Slave
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
mysql> SHOW SLAVE STATUS FOR CHANNEL 'master-143'\G *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 192.168.1.143 ... Master_UUID: 75e2e1dc-b48e-11e5-83bb-1438deb0d51e ... Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates ... Retrieved_Gtid_Set: 75e2e1dc-b48e-11e5-83bb-1438deb0d51e:1-2 Executed_Gtid_Set: 63a7971c-b48c-11e5-87cf-f7b6a723ba3d:1-2, 75e2e1dc-b48e-11e5-83bb-1438deb0d51e:1-2, Auto_Position: 1 ... Channel_Name: master-143 |
We can see the slave has retrieved the two GTID’s (75e2e1dc-b48e-11e5-83bb-1438deb0d51e:1-2) and executed them as well. Looking at the comics table, we can see all four comics have been transferred from two different masters:
Slave
|
1
2
3
4
5
6
7
8
9
10
|
mysql> select * from comics; +----------+-------------+--------------+----------+-----------+ | comic_id | comic_title | issue_number | pub_year | pub_month | +----------+-------------+--------------+----------+-----------+ | 100001 | Fly Man | 1 | 2014 | 01 | | 100002 | Fly Man | 3 | 2014 | 03 | | 100003 | Fly Man | 2 | 2014 | 02 | | 100004 | Fly Man | 4 | 2014 | 04 | +----------+-------------+--------------+----------+-----------+ 4 rows in set (0.01 sec) |
Replication took care of the AUTO_INCREMENT values. However, if you were able to see the SQL statements which were being replicated, you would have seen the original INSERT statements:
|
1
2
3
4
|
INSERT INTO COMICS (comic_title, issue_number, pub_year, pub_month) VALUES('Fly Man','1','2014','01') INSERT INTO COMICS (comic_title, issue_number, pub_year, pub_month) VALUES('Fly Man','2','2014','02'); INSERT INTO COMICS (comic_title, issue_number, pub_year, pub_month) VALUES('Fly Man','3','2014','03'); INSERT INTO COMICS (comic_title, issue_number, pub_year, pub_month) VALUES('Fly Man','4','2014','04'); |
The way replication handles the different AUTO_INCREMENT values is by sending over (from the master to the slave via the IO thread), the value for the comic_id column (which uses AUTO_INCREMENT). The value for this column (generated by the master) is transmitted along with the statement. We can take a look at the binary log on the master to see the SET INSERT_ID=100001 information, which is the value for the comic_id column, being transmitted to the slave along with the original SQL statement:
Slave
|
1
2
3
4
5
6
7
8
9
10
11
|
# mysqlbinlog mysql-bin.000001 ... # at 349 #160106 21:08:01 server id 142 end_log_pos 349 CRC32 0x48fb16a2 Intvar SET INSERT_ID=100001/*!*/; #160106 21:08:01 server id 142 end_log_pos 543 CRC32 0xbaf55210 Query thread_id=1exec_time=0 error_code=0 use `comicbookdb`/*!*/; SET TIMESTAMP=1452132481/*!*/; INSERT INTO COMICS (comic_title, issue_number, pub_year, pub_month) VALUES('Fly Man','1','2014','01') /*!*/; ... |
You now have two master MySQL databases replicating data to a single MySQL slave database. Let me know if you have any problems following this tutorial. And follow me on Twitter at ScriptingMySQL and TonyDarnell.
 |
Tony Darnell is a Principal Sales Consultant for MySQL, a division of Oracle, Inc. MySQL is the world’s most popular open-source database program. Tony may be reached at info [at] ScriptingMySQL.com and on LinkedIn. |