On March 10, 2015, we released MySQL-5.7.6 and among many other things it includes multi-source replication which provides the ability for a MySQL slave server to replicate from more than one MySQL master. We have been very careful with multi-source replication in terms of what exactly our users want and we have tried our best to incorporate as much feedback as possible. In the process, we released the feature twice under MySQL Labs asking users to try it out and tell us:
- If this caters to all their use cases,
- Plays well with the existing applications using single source replication so our users don’t have to change their old scripts at all if they do not intend to use multi-source and instead stick to single source replication.
- The user interface is in sync with our naming conventions to date, easy to understand and intuitive etc.
Note that the look and feel changed as we moved from one lab release to another and finally to the latest version as MySQL-5.7.6. In this post, I aim to introduce the released feature, the commands and how you can monitor the multi-source replication internals. Let’s start with the following figure that best illustrates the core of multi-source replication.
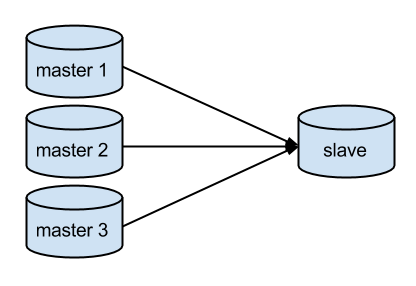
In the figure above we have three MySQL sources (independent MySQL servers- master 1, master 2 and master 3) replicating to the only slave acting as a sink to collect all the data from all the three sources.
The use cases of multi-source, as you have probably already guessed, are related to data aggregation. Note that there is no conflict detection or resolution built into multi-source replication. We expect the application to make sure that data coming from different sources are non-conflicting. A typical setup could be something like this:
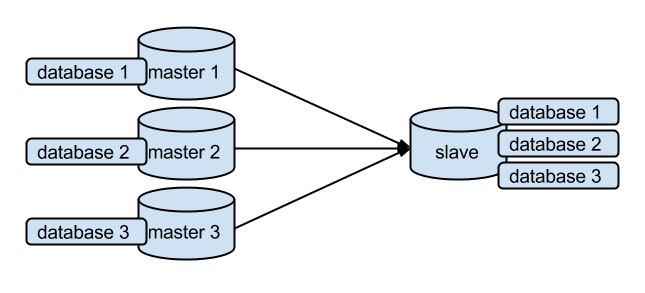
The same concept could be extended to shards (instead of databases). So another use case of multi-source replication is to join shards and make a full table on the sink (aka slave). .
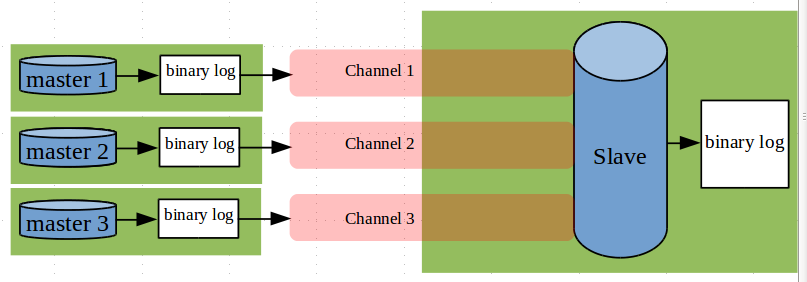
To understand how to configure and monitor multi-source replication, we introduced the notion of channels. A channel is an abstraction of the internals of MySQL replication’s finer details. It hides the machinery underneath while providing the level of detail that helps the user manage and understand multi-source replication. From a user perspective you can imagine a channel as a pipe between a master and a slave. If there are multiple masters, there are the same number of channels (or pipes) emerging out of the slave server as the number of sources as shown in the picture below:
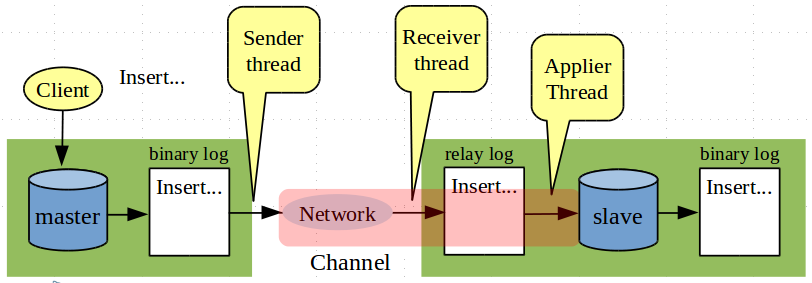
If you understand MySQL internals already and want to know exactly what constitutes a channel, look at the pink strip in the following picture. The replication channel documentation has all the details. But if you don’t know these details already, ignore this figure and move ahead. After all that is what we wanted to achieve with the concept of a channel.
With the concept of channels established, you can now follow steps described in the tutorial section of our official documentation to work with multi-source replication. Note how the FOR CHANNEL <channel_name> clause now allows you to take each master-slave instance individually and work with them as if you were working with a single source replication topology.
Having set up multi-source replication and making sure there are no conflicts you can expect it to just work out of the box. But if you want more details you could look at our monitoring interfaces to provide you the details on every channel. In MySQL-5.7.2, we introduced performance_schema tables to monitor replication, the good news is that these tables were always designed with multi-source replication in mind so they should work seamlessly with multi-source replication. All six replication performance schema tables now have a “channel_name” field added to them to individually access the configuration and status on each channel. As an example, we have described performance_schema.replication_connection status in our manual. Given that you are working with multiple channels, lets walk through this table again and see how it presents the internals. Try out the following query to look at the receiver module:

We can see quite a few things here:
- Which master does channel1 replicate from?
The one whose UUID is as given in the “source_uuid” column. - Which thread is responsible for receiving transaction through channel1?
Thread number 13. Note that this thread number is same as the one in performance_schema.threads table. You can use this information to now look into other performance_schema tables to mine more statistics using the joins. - Is the receiver module of channel1 active or down at the moment?
The channel is active and receiving transactions because its service state is ON. - What transactions have been received via channel1?
Transactions 1-4. See the global transaction identifiers in the field “received_transaction_set”. - What if there was an error?
The last three fields in each row give an idea of the error on that channel, if any.
See the example below where channel1 has lost connection:
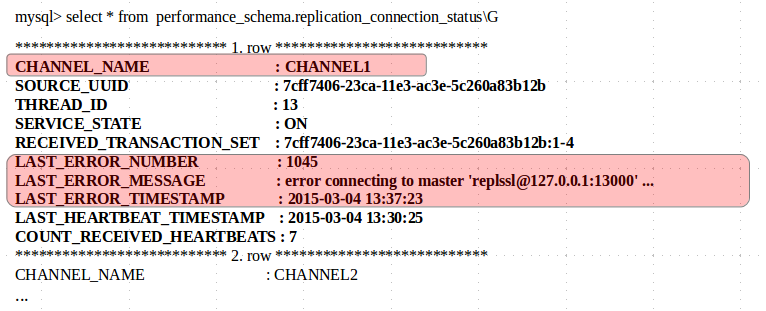
-
How about my network?
Look at the last two columns to get an idea of this. The last time a heartbeat signal was sent is shown in the “last_heartbeat_timestamp” column.
The “count_received_heartbeat” indicates how frequently heartbeats are being sent out. A big number here would mean that either the connection is not stable or this channel was idle having nothing to replicate.
Likewise there are more replication performance_schema tables that you can use to get to finer details. If there is anything else that you think should be available in these tables per channel, leave us a comment and we would be happy to take it forward. We truly believe in working with our users and look forward to your experience with this feature. There is a lot more to explore in multi-source replication so go try out the feature and if there is anything that you have suggestions for, please do leave a comment. Don’t forget that MySQL 5.7.6 is a development milestone release (DMR), and therefore not yet declared generally available.