In the first part of this series you learned how to setup an InnoDB cluster using Oracle Cloud. In this second part, you are going to learn how and when to use some of the advanced functions available in MySQL Shell.
Validating Instances
Before doing anything else, you may want to verify that a specific MySQL Server instance is prepared to be part of an InnoDB cluster. To accomplish this, you simply use the dba.checkInstanceConfiguration() function:
|
1 |
mysql-js> dba.checkInstanceConfiguration('root@ic01-mysql-1:3306'); |
You will see one of the three following final status results.
1. The instance is already part of a cluster
The following instance is already part of a cluster:

2. The instance is not ready for InnoDB cluster usage
The instance is not configuration to participate in an InnoDB cluster. You will see a list of the unmet requirements displayed:
|
1 |
mysql-js> dba.checkInstanceConfiguration('root@localhost:3306'); |

3. The instance is ready for InnoDB cluster usage
The following instance meets all of the requirements to be part of an InnoDB cluster:
|
1 |
mysql-js> dba.checkInstanceConfiguration('root@localhost:3306'); |

Note: As you can see, both a remote host and local host were validated using the same function.
Rejoin Instances Manually
If an instance is not configured to auto-rejoin the replica set / cluster — which can be done by executing dba.configureLocalInstance() on the given instance — then whenever the instance leaves the replica set / cluster for any reason, you will need to manually rejoin it.
To manually rejoin an instance to its cluster, you can either connect to one specific host that is a configured part of the InnoDB cluster, or preferably you connect to a MySQL Router instance that’s configured for the cluster — this way you will be sure to connect to a currently ONLINE R/W member of the cluster — as shown below:
|
1
2
|
mysqlsh shell.connect('root@localhost:6446'); |
Then, run the following commands to rejoin the instance manually:
|
1
2
|
mysql-js> var cluster = dba.getcluster('mycluster'); mysql-js> cluster.rejoinInstance('root@ic01-mysql-1:3306'); |
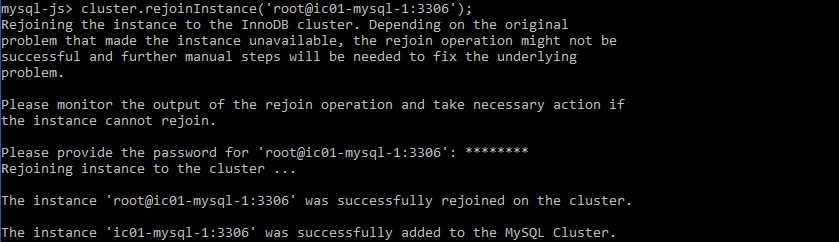
Once the instance is added back to the cluster you can verify that is again ONLINE:
|
1 |
mysql-js> cluster.status(); |

Restoring a Cluster from Quorum Loss
When the majority of the instances in your replica set become UNREACHABLE, the replica set will no longer have a quorum to perform any membership changes or execute R/W user transactions. During this time you will only be able to execute read-only queries in order to keep the system consistent and your data safe.
In the following screenshot you can see a cluster that has lost its quorum:
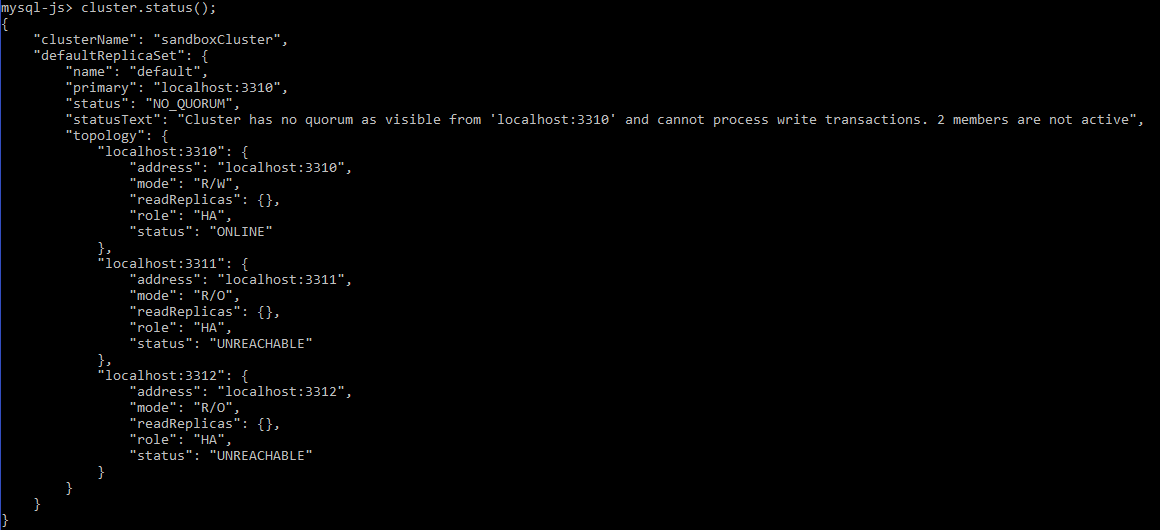
Executing the following function to add an instance gives an error due to the lack of quorum:
![]()
To deal with this situation you can using the cluster.forceQuorumUsingPartitionOf() API call, but before using it make sure that the all the UNREACHABLE instances are really OFFLINE in order to avoid creating a split-brain scenario, on which you will have two groups that receive updates separately.
|
1 |
mysql-js> cluster.forceQuorumUsingPartitionOf('root@localhost:3310'); |

Once the force quorum function is complete, you can check the status of the cluster:
|
1 |
mysql-js> cluster.status(); |
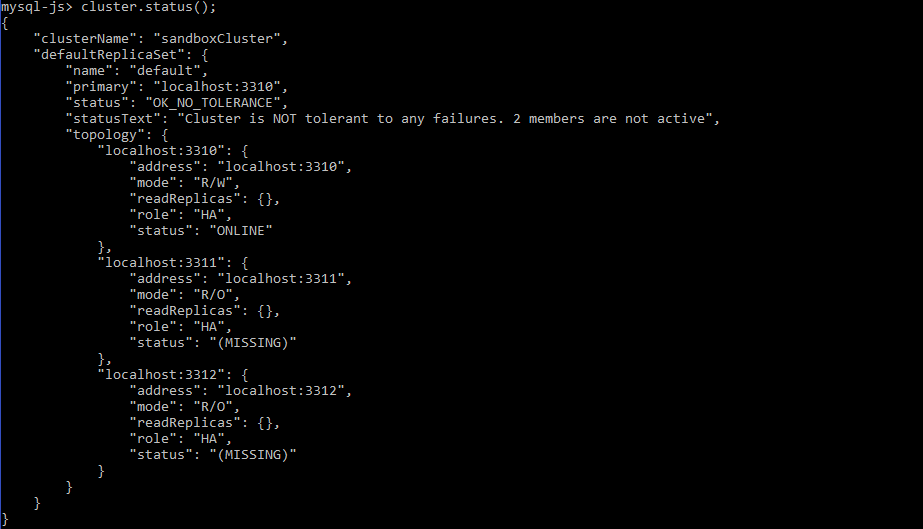
As you can see, the instances changed their status from UNREACHABLE to MISSING, and now the cluster can perform write operations. You can now add a new instance, for example:
|
1 |
mysql-js> cluster.addInstance('root@localhost:3313'); |

Checking the cluster status again you will notice that the new instance was added to the cluster:
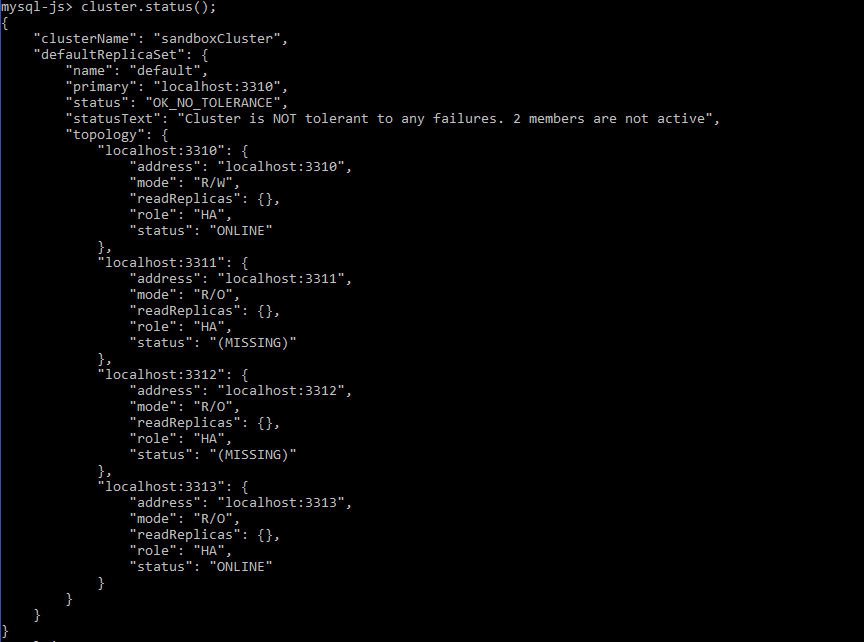
Once you know that the (MISSING) instances are back ONLINE, you can rejoin them manually to the cluster in the case that the instances do not have a persistent configuration to automatically rejoin the cluster:
|
1 |
mysql-js> cluster.rejoinInstance('root@localhost:3311'); |
|
1 |
mysql-js> cluster.rejoinInstance('root@localhost:3312'); |
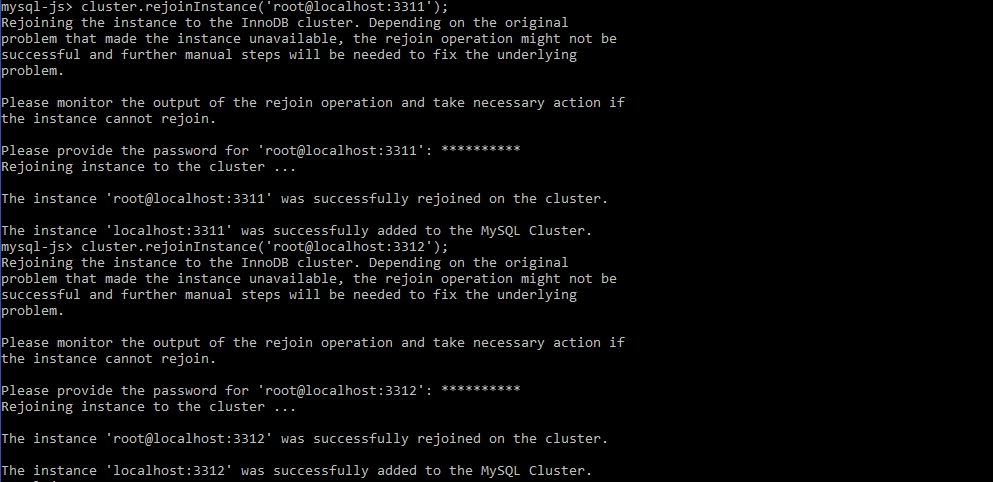
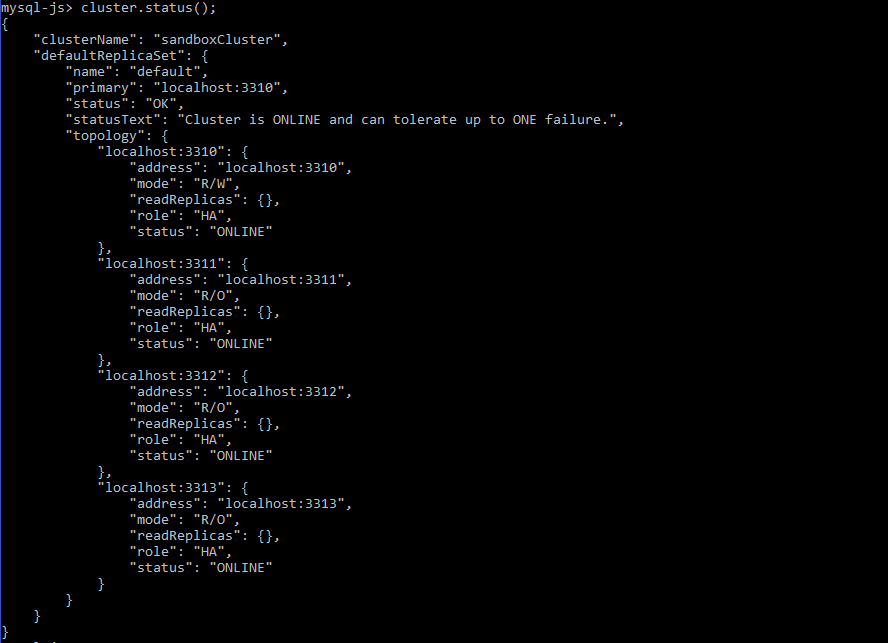
Now all the instances are ONLINE in the cluster:
|
1
2
|
mysql-js> cluster.status(); |
Recovering a cluster with all members OFFLINE
When all the members of your cluster go OFFLINE for some reason, there is only one way to recover the cluster: “bootstrap” it again and rejoin the rest of the nodes. Bootstrapping a cluster implies selecting an initial bootstrap/seed instance for the cluster and restoring it based on the previous state recorded in the cluster metadata.
To accomplish this, you need to open a connection to the (preferably) last RW / PRIMARY member of the group (as that instance should be guaranteed to have a GTID superset within the group) and execute the command dba.rebootClusterFromCompleteOutage().
If you try to get the cluster status at this point by connecting to the bootstrap instance and executing the dba.getCluster() command, you will get an error saying that the function is not available for a standalone instance:
|
1
2
|
mysql-js> shell.connect('root@localhost:3310'); mysql-js> cluster = dba.getCluster(); |

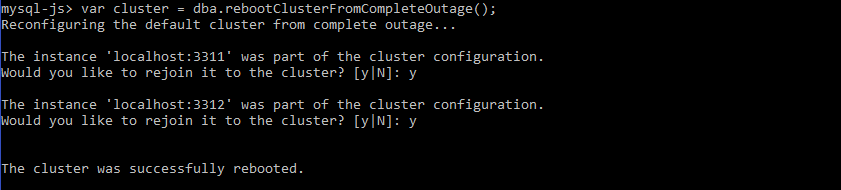
So this is now when you would use the API call to reboot the cluster. You will be prompted with interactive messages to auto-rejoin the instances that are part of the cluster. Answer “y” to add them automatically:
|
1 |
mysql-js> var cluster = dba.rebootClusterFromCompleteOutage(); |
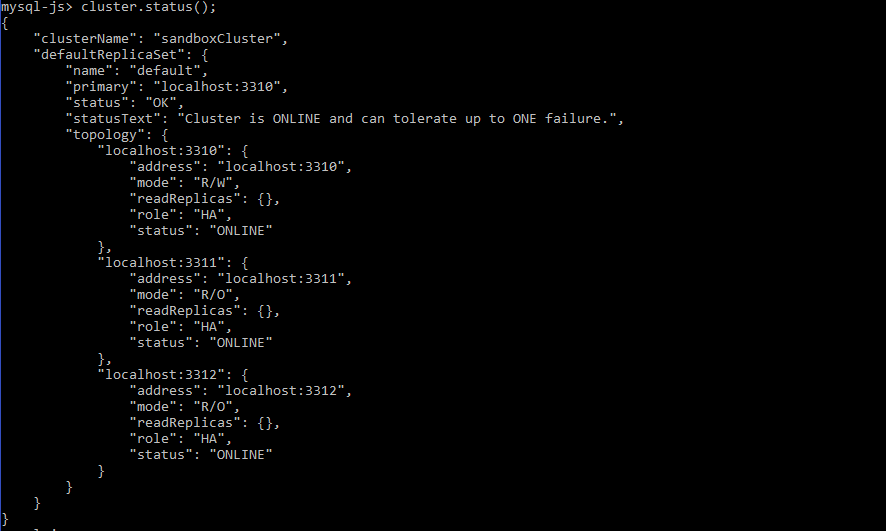
Once the group is restored, verify the status of the cluster:
|
1 |
mysql-js> cluster.status(); |
Conclusion
You have now acquired the knowledge needed to recover from situations where a single instance or a complete cluster suffers an outage. As you can see, the functions are easy to use, intuitive, and designed to cover the primary scenarios that can cause issues in a high-availability context.
If you have any questions about the basic setup described here, please let us know here in the comments. As always, thank you for using MySQL!