First we will talk about some of the other internal users of the technology that underpins the InnoDB Clone. MySQL Enterprise Backup (MEB) is an enterprise offering that provides backup and recovery for MySQL. Among various types of backups available, the following two types are of interest to us:
-
Full Backup– A backup that backs up the entire MySQL instance – all the tables in each MySQL database.
-
Incremental Backup– A backup that contains only the data that has changed since the previous (full/incremental) backup.
To take incremental backups, MEB needs to know the list of all the modified pages since its previous backup to backup only these pages. But with InnoDB lacking the infrastructure to internally track the modified pages, MEB had to resort to a brute force method of scanning each page in each tablespace file to figure out the modified pages. This, as one can guess, is an expensive operation which had been a major pain point for the MEB product.
The Clone plugin (introduced in MySQL 8.0.17 to make cloning MySQL instances easier) introduced the infrastructure to track the modified pages within InnoDB. Since it was a bare minimum tracking facility, it was further extended to add the ability to track modified pages across restarts and crashes to make it into a full-fledged feature which MEB could use for its incremental backup. Additionally, an interface was introduced for MEB to interact with the feature to enable/disable tracking, and to fetch required page tracking data.
This blog is an attempt at explaining the design and the intricacies of this page tracking feature and how MEB utilises it to take incremental backups more efficiently.
InnoDB Background
Before we move to the details of the feature we must understand some of InnoDB’s internals related to the crash recovery mechanism to be in a better position to gauge the page tracking feature.
InnoDB, on a running server, maintains two copies of its pages – one in memory (buffer pool) for faster access and another on disk. Any changes to a page, before it’s written to the memory copy, is written to a buffer in memory called the redo log buffer. This buffer is periodically flushed to a log file called the redo log file, allowing InnoDB to reduce the non-sequential writes by flushing the memory copy of the page to the disk lazily as any data lost during a crash can be easily recovered from the redo log. This process of writing to the log file before the data file is called Write Ahead Logging (WAL).
An interesting concept that stems out of WAL is the Log Sequence Number (LSN). At any given time, the redo log system maintains an ever-increasing sequence number, called the LSN, to assign to a group of page changes that will be added to the redo log buffer atomically. This LSN associated with the page changes present in the redo log can be, in a loose sense, considered as a time metric which gives us an idea about the chronology of these changes.
Since they gives us an idea of the sequence of the changes, LSNs are used to track various operations inside InnoDB and depending on its usage are called by different names. Since there is a myriad of these, let’s focus on a subset of them.
System level LSNs
-
System LSN– This represents the LSN value assigned to the last atomic set of page changes and is, therefore, the max LSN of the database system at any given point in time.
-
Checkpoint LSN– As mentioned, InnoDB does not flush the pages in memory immediately after a page write. Instead, it flushes modified pages lazily with the help of background threads. To know the state of the flushing at any given time, InnoDB follows a process called checkpointing that occurs intermittently owing to factors that are beyond the scope of this blog. This process checks the LSN up to which all pages are already flushed and notes it as the checkpoint LSN. One can think of a checkpoint LSN as a marker that tells us until when we can find all page changes flushed to disk, and checkpointing as the process which moves this marker ahead from time-to-time.NOTE - The page that is being flushed could have changes ahead of the checkpoint LSN, but never behind the checkpoint LSN.
Page level LSNs
-
Page LSN– The memory copy of the page may have multiple changes, but it’s not necessary for all these changes to be present on disk. This LSN, stored in the page header, indicates the LSN up to which the page changes reside on disk.NOTE - This LSN is updated only at the time of a page flush and since page tracking also happens during a flush (as we'll see later) any reference to the page LSN in this blog refers to the old value present on disk and not the updated one.
-
Oldest Modification LSN– Each page stores this LSN in memory, and it refers to the LSN of the oldest page modification that is not yet flushed to disk.NOTE - Unlike page LSN, this LSN does not reside on disk as it's not part of the header.
The WAL along with the process of checkpointing is what allows InnoDB to recover from crashes. In the case of a crash, InnoDB starts the crash recovery process even before the database is up and reads the redo log for changes after the checkpoint LSN. It checks each redo log record to see if it needs to be applied, by comparing its page LSN to the LSN of the change, and applies it only if the change appears to be missing. This brings the entire system to a state that it was in just before the crash, thereby recovering the lost data.
With this, we are now ready to move to the actual topic of discussion.
Tracking
So how and when are modified pages actually tracked? Well, the tracking is done at the IO layer when the page is being flushed to disk.
When page tracking is started for the first time, the system LSN at the time of the start request is noted down as the tracking LSN. Any page being flushed thereon, whose page LSN is less than the tracking LSN, is tracked. The idea is that we do not want pages already tracked to be tracked again, and page LSN >= tracking LSN would mean that the page was already flushed and tracked after tracking was enabled, since page LSN refers to the latest LSN on disk.
Similarly when page tracking is stopped, the checkpoint LSN at the time of the stop request is noted down as the stop LSN. This is because checkpointing ensures that all the page changes before the checkpoint LSN are already on disk; and that consequently means that these pages would have been tracked.
This helps the page tracking system to formally give a guarantee that all pages modified between the start LSN and the stop LSN would definitely be tracked. Although, there could be cases where there are a few extra pages which do not belong to the tracking period. This could potentially occur if the page was modified even before tracking was started but flushed after it, or if one of the page modifications done at LSN > checkpoint LSN was already flushed to disk before the issued stop request. This is an unintended side-affect of the design that is in place, though, in the larger scheme of things, a few extra pages shouldn’t really be a cause for worry.
Let us take an example to understand what was just described.
![]() Fig 1. The horizontal line indicates the increasing LSN order from left to right. And for the purpose of the illustration we assume that the checkpoint LSN is just behind system LSN, which may not be the case all the time.
Fig 1. The horizontal line indicates the increasing LSN order from left to right. And for the purpose of the illustration we assume that the checkpoint LSN is just behind system LSN, which may not be the case all the time.
Let’s say we started tracking pages at the time when system LSN was 5 and stopped tracking pages when the checkpoint LSN was 20. Then as stated, the start LSN and the stop LSN of the tracking period would be 5 and 20, respectively. With this tracking period, the guarantee that page tracking gives is that any page modified between LSN [5,20] is tracked. But the list of pages returned could have pages that were modified before LSN 5 or after LSN 20.
Interfaces
Since MEB is an external product, a component service API implementation was provided for MEB to utilise the feature via a component as that is the preferred way to extend the server capabilities currently in 8.0. More information about components and extending MySQL server can be found here.
As part of Service API implementation, there were mainly 4 interfaces provided to MEB to interact with the page tracking feature. Each interface and what it does is briefly explained below.
Start/Stop
The start and stop interface starts and stops page tracking respectively. As previously explained, system LSN is used as the tracking LSN and the checkpoint LSN as the stop LSN. They are also returned to the caller so that they can note down this LSN and later use it to query pages.
Reset
Although not really an interface, calling start interface when tracking already has been started causes a reset. As part of the request, the tracking LSN is reset to the system LSN at the time and this LSN is returned to the caller to be used for querying purpose in the future.
This is mainly used to infuse querying points between the start LSN and the stop LSN so that only the pages modified between the querying points can be retrieved, instead of having to retrieve all the pages tracked from start LSN. This is especially useful for MEB’s incremental backups (will be explained in the next section).
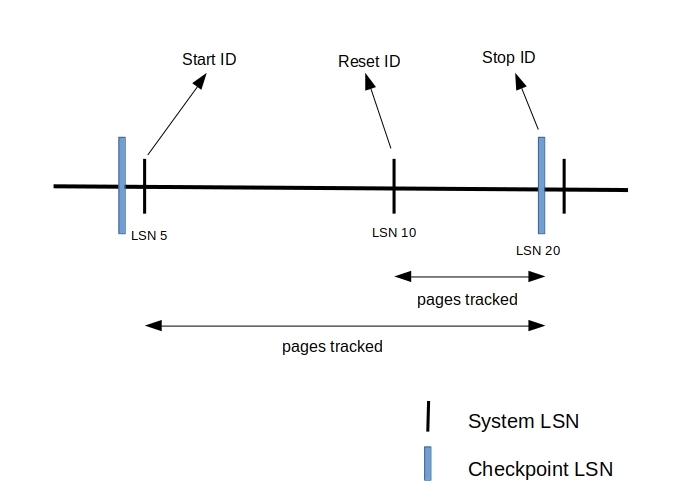
Consider an example, as illustrated above, where page tracking was started with start LSN as 5, followed by a reset request issued when the system LSN was 10, and finally with a stop request with stop LSN as 20. As part of the reset request, page tracking resets the tracking LSN from LSN 5 to 10 and returns it to the caller. Now the caller, with this querying point, can query for modified pages between LSN 10 and 20 in addition to querying for modified pages between LSN 5 and 20.
An important point worth mentioning here is that reset results in duplicate page entries. This can be seen when the user queries for modified pages spanning a wider region i.e., across resets. The reason being that, when a reset is issued, the tracking LSN is reset to the system LSN at the time which means that any pages modified thereon should be tracked regardless of whether they were tracked previously or not. Taking the above example, if a page was modified at system LSN 7 and 12, it would get tracked again the second time. So when the user issues a request for pages tracked between 5 and 20, they would see this page entry twice.
Fetch pages
This interface is provided to fetch the list of tracked pages between two LSNs – (begin LSN, end LSN]. The two LSNs can be any two LSNs but it’s preferred that the begin LSN is one of the tracking start points – start LSN or reset LSN, and the end LSN is the current checkpoint LSN or tracking end point – stop LSN. The reason for the preference is that with any two random points the range returned might get expanded leading to the interface returning more number of tracked pages. This is because the page tracking system tries to map the begin LSN to the closest start/reset LSN and the end LSN to the closest checkpoint LSN we’ve noted down internally in our implementation. In case neither of the LSNs provided is within the tracking period, the interface will return an empty list.
Consider the above example for which the start LSN is 6, reset LSN 22, and stop LSN 34. We also have LSN [5,10,17,29,34] as the checkpoint LSN we’ve noted down internally. If the user issues a fetch pages request for the LSN range (11,16] then the range gets expanded to (6, 17], and with (25, 32] the range gets expanded to (22, 34]. The LSN range considered would be the same though if the user issued request between (6, 34] or (22, 34].
Purge
Since the tracking data is persisted, if tracking is enabled for a longer duration the files might take up sufficient space on disk. In case it’s decided that tracking data until a certain LSN is not required then purge interface can be called with this LSN to purge the data to save space.
Although the concept of groups will be explained in detail in the next section, for now, consider group as an entity that maintains tracking information for a specified period – from start LSN to stop LSN. As part of the purge request, the group for which the start LSN <= purge LSN is identified, say the purge group. Any group preceding this purge group is completely purged and any group after it is not touched. Within the purge group, however, partial purge is carried out by deleting those files which do not have changes ahead of the purge LSN.
Tracking Data
There are two sets of information stored by the page tracking system that constitutes as tracking data. One is the main tracking information related to the tracking of modified pages and the other is the reset information related to the resets requested by the user. Since page tracking is mainly concerned with which page was modified since the tracking was started, the tracking information is merely the page ID – space number and page number – information of the modified page. The reset information, on the other hand, consists of the reset LSN and the position of the reset with respect to the tracking information. This information also needs to be stored because fetch pages request needs to map the begin LSN of the request to the nearest reset LSN and return only the pages modified since then.
Since MEB backup works across restarts, the tracking data needs to be persisted too. To get the picture of the storage structure on disk, we need to first understand the concept of groups. Groups are a logical layer added on top of tracking to maintain the tracking information for a specified period. It represents continuous tracking information from start LSN without any gaps in between. They are set to active as part of the start request and marked finished as part of the stop request. Once the group is active, our tracking data gets tracked to this group. Although the page tracking system can have more than one group, only one group can be active at any given time.
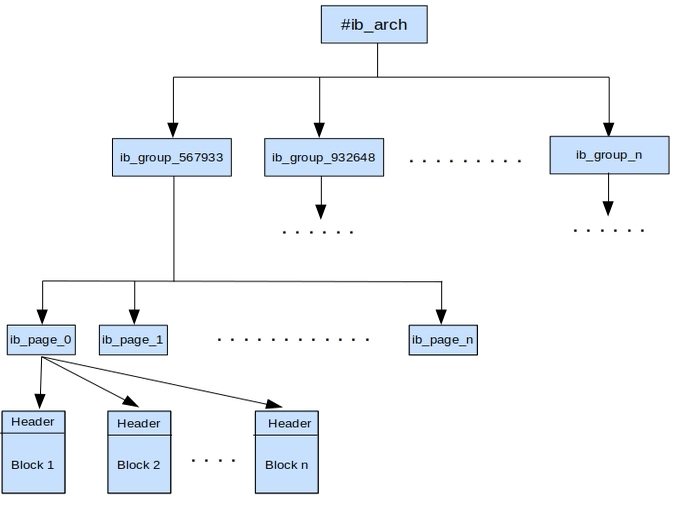 Fig 4. Storage Format
Fig 4. Storage Format
Physically, groups are represented as a directory containing a set of files of a fixed size of 32MB. All the tracking data related to the group resides in these files. While the directory names follow the format of start LSN of the group prefixed by ib_group_ , the file names follow the format of index of the file (starting with 0) prefixed by ib_page_. All the group directories would reside in the umbrella directory #ib_arch, which further resides in the data directory. An example illustration is shown above.
In memory, the tracking data is stored in blocks of size 16KB which is tracked as part of a group that is active. There are two types of these blocks – reset block and data block. Internally, a set of 32 data blocks and 1 reset block are maintained to store tracking information and reset information respectively. The reset block corresponds to the first block of every file and gets flushed at the time the system is switching to a new file and subsequently gets overwritten. The data blocks, on the other hand, are filled in a circular fashion one after the other and flushed to files lazily by a background flusher thread.
Having discussed the storage format, it maybe worth mentioning the rate of disk usage as a closing point. The data that mainly grows is the tracking information as the reset information would constitute only one 1 block in a file. Since only page ID is maintained as the tracking information, each page modification would require 8 bytes of space. So that’s roughly 2K page modifications for a single data block to be filled. And since we have a fixed file size of 32MB, each file can contain 2K blocks, and hence can host up to 4M page modifications. Although it may not seem much, it needs to be noted that leaving page tracking on for a long period of time without purging the data could lead to the system occupying significant amount of disk space. So care must be taken to purge the data from time-to-time.
Crash Recovery
As discussed, the page tracking system maintains a circular list of 32 data blocks in memory which are written to sequentially one after the other and flushed to disk lazily by a background flusher thread. This approach could potentially result in data loss as we might lose page entries in the case of a crash if a block isn’t flushed at the time. What this means is, with just this approach, there’s no way of guaranteeing that the list of pages that the system returns when queried between two points (within a tracking period) are consistent and complete.
To overcome this issue, the page tracking system relies on the crash recovery mechanism that InnoDB has in place. In addition to having the blocks being flushed by the background thread, it also flushes necessary blocks as part of the checkpointing process. To decide which blocks needs to be flushed as part of checkpointing it makes use of the the oldest modification LSN concept. For each block, it maintains the oldest of the oldest modification LSN of all the pages tracked in the block header. Since at the time of checkpointing the next chosen checkpoint LSN guarantees that all page changes before it are already on disk, it makes sense for us to flush only the blocks whose oldest of the oldest modification LSN is less than the next checkpointing LSN as they need to be persisted and cannot be lost. This ensures that the page changes and their corresponding page entry in the page tracking system till the checkpoint LSN are flushed to disk and are hence safe from crashes.
With this safety in place, all that needs to be done now is to initialise the page tracking system and start page tracking even before the crash recovery process is started, as during crash recovery we redo the changes done after the checkpoint LSN,thereby tracking these pages yet again.
How MEB uses Page Tracking
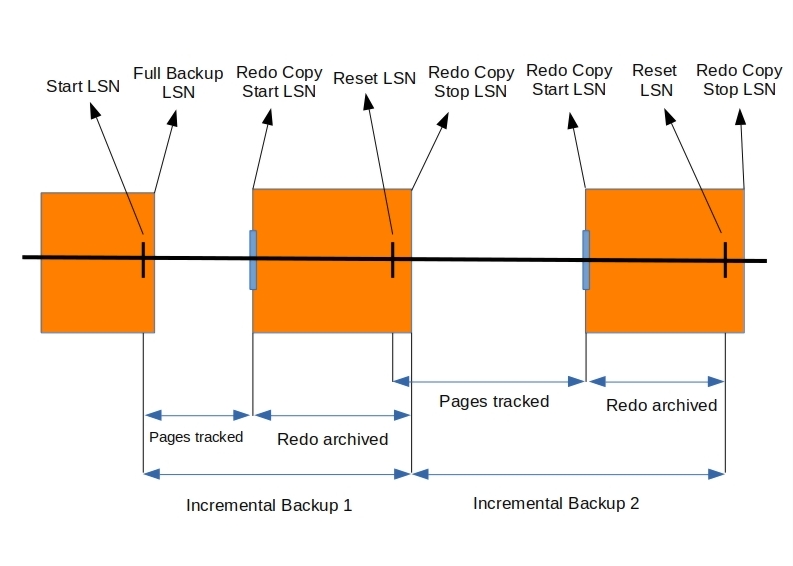 Fig 5. The horizontal line indicates the increasing LSN order from left to right. And for the purpose of the illustration we assume that the checkpoint LSN is just behind system LSN, which may not be the case all the time.
Fig 5. The horizontal line indicates the increasing LSN order from left to right. And for the purpose of the illustration we assume that the checkpoint LSN is just behind system LSN, which may not be the case all the time.MEB follows a series of steps to take incremental backup using the page tracking feature.
- Incremental backups are always coupled with previous backups. To
take advantage of page tracking for subsequent incremental backups, MEB
starts page tracking as final step of a backup. This ensures that
the tracking LSN <= end LSN of the previous backup; hence all modified pages since the previous backup are guaranteed to be tracked and included in the subsequent incremental backups.
- Now, let’s assume that after some point in time when the system LSN and checkpoint LSN have moved well beyond the full backup LSN, the user issues a request to take an incremental backup. As part of this request, MEB starts copying redo logs from the checkpoint LSN at that point as the page tracking system gives a guarantee of tracking pages only till checkpoint LSN.
The redo is required to roll-forward all the pages on the disk to a certain version. We know that the modified pages are tracked until the checkpoint LSN, but the tracked pages on disk may have a change greater than the checkpoint LSN, as most often than not the system LSN is greater than checkpoint LSN, and this change could have been flushed independently. Since we need to have a system which has all the changes until a certain LSN,we need to rely on the redo logs to roll-forward.
- Once done, MEB issues a fetch pages request between start LSN and the current checkpoint LSN of the system to get the list of all modified pages between the two points.
- MEB now backs up only the pages present in this list, while the redo log is being copied in the background.
- Once the copying is over, a reset request is issued to the page tracking system for the next incremental backup and the redo copy process is stopped. The copy of the pages tracked by the tracking system coupled with the copied redo logs essentially constitutes the incremental backup.
- Since the incremental backup is already taken, the tracking data is now a candidate to be purged with the checkpoint LSN used in step 3 as the purge LSN.
In this manner, MEB makes uses of the page tracking feature to get the list of all modified pages without having to scan each and every page in InnoDB, thereby resulting in faster incremental backups for MEB.
Incremental Backup Performance with Page tracking
Page tracking is extremely useful for MEB when the modified pages are a smaller percentage of the total pages. Below are some numbers to demonstrate the performance gain in MEB incremental backups using the page tracking feature.
| For 1TB Database | without page track | with page track |
| No changes to table | 6897 seconds | 10 seconds |
| 1% of changed pages | 7233 seconds | 1016 seconds |
| 33% of changed pages | 7640 seconds | 1185 seconds |
As you can see, the gain is clearly large when there are no page modifications since the previous backup. Decreasing the time taken to 10s from what could take about 2 hours is a big win for MEB. This is expected as with just one query MEB can now know that there are no pages to be copied. With 1% and 33% of changed pages, it can be seen that there’s an impressive 600% increase in performance. But with percentage of modified pages close to 100, it was observed that the brute force approach performed better. But this is mainly due to the overhead incurred by MEB because of their architecture, and in such cases, currently, MEB switches to the brute force approach.
Conclusion
As you have seen, we have introduced a full-fledged feature to track pages within InnoDB. Although the feature is not really usable from the end-user perspective, it has the needed support to be made available to the end-user by adding the required SQL interface, which we plan on doing in the future. This blog was merely an attempt in giving the background information and explaining the feature and the potential of it.