Introduction
The multi master plugin for MySQL is here. MySQL Group Replication ensures virtually synchronous updates on any member in a group of MySQL servers, with conflict handling and failure detection. Distributed recovery is also in the package to ease the process of adding new servers to your server group.
For a better understanding on how things work, we go under the hood in this post and you will have a better understanding about the communication layer functionality and implementation.
Group Communication concepts

As the architecture shown in Figure 1, Group Replication is a classic modular and layered piece of software and the bottom two layers comprise the communication module. But, it is not a regular point-to-point connection, as in classical Replication, but rather a different paradigm: Group Communication.
The Group Communication abstraction can be seen as a vast field of study about distributed interprocess communication, providing a set of primitives and services that allows the creation of reliable, dependent and highly available software. Apart from being an academic concept it is implemented, in the form of libraries and frameworks, and used thoroughly in the software industry.
Talking about the concepts, one of the cornerstones in Group Communication is the Group itself. It can be defined as a set of nodes that have the ability to communicate with each other. On top of this, one can build all sort of services and functionalities.
In order to be aware of the groups members in any moment in time, we use a service named Group Membership. It builds itself using the Group definition and adding the notion of View, which can be defined as the state of the Group in a certain moment in time. If offers primitives that allow a member to Join and Leave a group, informing all the interested parties of that event. It also offers dynamic Group reconfiguration, in which failed members are automatically evicted from a Group.
Another service relevant to Group Replication is the Total Order broadcast primitive. It allows for a member to send a message to a Group and ensure that, if one member receives the message, then all members receive it. It also guarantees that all messages arrive in the same order in all members that belong to a Group.
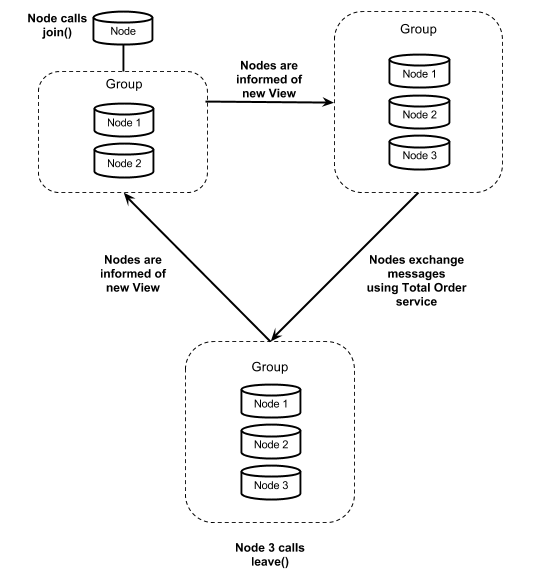
A typical lifecycle of a member can be seen in Figure 2:
1. A new Node, soon to be a member, calls join() in order to enter a group;
2. All members in the group, including the new Node receive the Group’s new View.
It becomes Node 3 within the Group.
3. All nodes in the Group continue to exchange messages. Those messages
will be delivered using Total Order Broadcast.
4. Node 3 decides to leave the Group. It calls the leave() primitive.
Note: This could also happen due to Node 3 crash. Then it would
not call leave(), but the View Membership would detect the failure
and start this process automatically.
5. All members receive the Group’s new View, without Node 3.
6. The process can start all over again.
Just to open the hood on Group Communication frameworks, the above services are mostly implemented using, in the communication layer, multicast or full network meshes and in the logical layer, software components such as failure detectors and consensus algorithms. The beauty lies in the combination of all these to provide middleware with such strong guarantees and above all, with a simple API.
These strong reliability properties will allow us to create a Distributed State Machine on top of it, that will serve as a base for implementing the algorithms described in [1].
How was it designed and implemented?
We followed a top-down approach on this subject. A generic interface was created to serve the business logic layer. It has the obvious advantage of decoupling any external software that we use from the actual implementation. It will also allow us to benchmark individually each Group Communication framework with a single test platform in order to compare performance and limitations of different implementations.
Without entering in too much detail, we gathered the common functionality from most implementations and together with our requirements, three interfaces were devised:
– A Control interface that will allow a member to manage its status within
a group with primitives like Join, Leave and callbacks to View
Membership information.
– A Message interface that allows a member to send and receive messages.
– A Statistics interface to store and extract information about the
Group and Messages.
We call this the Interface, as opposing to the actual implementation that we shall call Bindings. In this project, we did not implemented a full-fledged Group Communication Framework, but instead we decided to use an existing product that would suit our needs. That product is Corosync [2], and it will be the single Binding available in this first release.
Corosync is a cluster engine that has in its base the usage of Group Communication. Its goal is to aid in the development of reliable and highly available application. Taking into account our requirements its a good first choice since:
– If offers what we need in terms of functionality in its Closed Process
Group communication model.
– It has a C API.
– It is proven and deployed solution, for instance, in Pacemaker
and Apache Qpid.
Corosync binding implements all three sub-interfaces, adding on top of it some customizations, being the main one an algorithm in which all members execute an additional step by exchanging their status right after a View Membership change. In that step, they agree upon the next View and exchange generic data provided by the upper layers that use the binding implementation.
In order to install and configure Corosync and MySQL Group Replication, please follow the link to this blog post and try this exciting new feature.
references
[1] – Fernando Pedone, Rachid Guerraoui, and Andre Schiper. The database state machine approach, 1999.
[2] – Corosync – http://corosync.github.io/corosync/