In this post I'd like to explain a big optimization in CRC-32C computation, inspired by a paper by Gopal, V., et al.: "Fast CRC computation for iSCSI Polynomial using CRC32 instruction" from Intel, which landed in MySQL 8.0.27 and hugely increases the processing speed (the improvement for ARM64 architectures is more pronounced for reasons explained later in the post):
I want this post to be as accessible, as possible, so it starts slow with building intuitions, thus you might want to scroll down past the things you already know to the section you're interested in:
- What's a checksum?
- How to compute a checksum?
- What's CRC32?
- How does MySQL 8.0.27 compute CRC32-C faster?
Before we proceed, a word of caution about charts like above: even though I took extra care to run 100 iterations, noting median and max, checking they are not far apart (as you can see - or perhaps can't see because it's so small - the difference between max of 100 runs and the median is negligible - literally 0 for ARM64), and repeating the whole procedure twice to see if it replicates, there is still a huge source of "non-determinism" - the compilation. You may get exactly the same result each time you recompile given source on given compiler on given machine, yet be astonished to see +33% or -20% change once you do some trivial change like adding asm("nop":::) somewhere, or changing the linking order. There are many reasons for this and they have to do with complicated heuristics used by modern CPUs when they cache, predict, fetch, and decode your code, all of which depend on the code's layout in memory w.r.t. to 64/32/16-byte boundaries etc. Therefore it's a good idea to look at trends on the whole spectrum of setups, rather than focus on some small change on particular one - unless you want to fine-tune the implementation to this particular platform.
What's a checksum?
When InnoDB stores your data on disc, and later reads it back to hand it to you, it wants to make sure that it wasn't corrupted meanwhile, and that what it read is what was intended to be written. There are various reasons why something could go wrong, and all of them are serious enough, that it's better to panic, than to continue pretending that everything's ok. To name just a few: a neutrino passing by through your data-centre could flip a bit on the disc, a stray cat could pull the plug from the server when it was halfway rewriting a part of data with new data, or perhaps some other process overwrote the data (Notepad.exe?:)). As "D" in ACID stands for "Durable", the InnoDB wants to make sure that the data it wrote is then read back intact.
For this purpose, InnoDB employs checksums for data pages and redo log by default using the CRC-32C algorithm. A checksum is a nice way to solve a difficult problem of identifying typos or errors in a message.
If I accidentally change a letter in an English sentence, there's high chance that it will lead to something noticeably wrong, and thus you'll be able to detect it. This is because English language has quite a lot of redundancy, that is not every sequence of letters has a meaning, and there is a lot of structure in it, which lets you almost immediately see an odd character. For starters it uses just a few dozens of possible letters, out of 256 possible byte values. But what if you had to find a typo in a long chain of digits, that you have no prior idea what they should really be like? Say, like a bank account number. Is 10 1050 0099 7603 1234 5678 9123 a valid bank account number, or did I made a typo in it?
Turns out, there's a quite reliable way to tell. Every International Bank Account Number (IBAN) starts with two digits, which are a checksum (here: 10) of the remaining digits.
A checksum has to correspond to the other digits: there's a single, well known way of computing the checksum from the other digits, and you can repeat this computation for 1050 0099 7603 1234 5678 9123 and see if the result is 10. If it is, then there's a high chance there was no typo. Otherwise, there for sure was a typo.
How is the checksum computed?
This is not an article about IBAN, so please allow me to do some simplifications in my presentation of it (See Wikipedia's International_Bank_Account_Number for more advanced treatment).
But I'll use IBAN to demonstrate some fundamental concepts that we will use later on:
- computing the checksum while reading the data in one go by updating the checksum computed so far
- modulo operations
- impact of data on final result depending on its position
One tempting idea would be to simply add all the digits together: 1+0+5+0+0+0+9+9+7+6+0+3+1+2+3+4+5+6+7+8+9+1+2+3, gives 91, a nice two-digit checksum.
There are some problems with such approach. First, the result might be larger than 99. But there's a bigger one: what if I accidentally reversed the order of two digits. Things like that happen to me quite often. But, 2+3 gives the same result as 3+2, so the final checksum will be the same, and no one will spot the problem. (A related issue is that there are much more ways which lead to the sum being 120 than to being 0)
Another simple idea to reduce a big number into something smaller than 100, would be to ... simply take the remainder from division by 100. That was easy!
But, I hope you see that this is a very bad candidate for checksum algorithm, as it is equivalent to just copying the last two digits of the number (23 in our case). This is bad, because if you made a typo in any other digit than the last two (or the checksum itself!), then you'll never find out about it as they don't participate in computation of the checksum.
So, how about taking the rest from division by 99? We call it "n modulo 99" and most C-like languages denote this as n % 99. I must say this looks tempting. If you feel a bit uneasy about having to divide a very big number by 99 do not panic - it's actually not that complicated when all you care about is the rest. You just process one digit at the time from left to right, remembering that appending one digit (d) to the number (n) is like multiplying the number by 10 and adding the digit: 10n+d, and
(10n + d) mod 99is just
(10*(n mod 99) + d) mod 99Thus, you never really have to deal with big numbers. You just need to multiply the old checksum by 10 and add the new digit, perhaps subtract 99 several times from it, and so on.
In our example it would start with the checksum being 1 (which is just the first digit),
then we update it by appending digit "0", to (1*10+0) mod 99 = 10,
then we update it by appending digit "5", to (10*10+5) mod 99 = 105 mod 99 = 105 - 99 = 6, and so on.
First, let's observe that indeed each digit influences the outcome.
When we change the last digit it directly changes the output.
The impact of the second-to-last digit is magnified by 10 times, this is because if I change the second-to-last digit by 1, it will directly change the checksum so far by 1, which will be multiplied by 10 in the next step.
Similarly, the digit before it, has impact times 100, which mod 99 is like 1.
And so on: the impact of k-th number from the end is 10k mod 99.
Also, note that swapping two consecutive digits always changes the result, because if we found digits a and b such that swapping them doesn't change the checksum, then it would imply that:
(10a+b) mod 99 = (10b + a) mod 99which in turn means:
9a mod 99 = 9b mod 99which, given that 0,1,2,..,9 give different results smaller than 99 when multiplied by 9, implies a = b, so we've haven't really swapped different digits.
Alas, if you swap digits which are two positions apart, like changing "abc" to "cba", then you might have a problem:
(100a + 10b + c) mod 99 = (100c + 10b + a) mod 99means:
99a mod 99 = 99c mod 99which holds for any a and c, as multiplying by 99 gives 0 modulo 99. Indeed 100 and 001 have the same checksum: 1.
This is because, as we've already said, the impact of k-th character from the end is 10k mod 99, and if we look at the sequence of values of this expression for k=0,1,.. we get:
1,10,1,10,1,10,...that is: the impact of any odd position is exactly the same. And so is the impact of every even position. So the problem is not just with switching two digits when they are two positions apart - you can switch any digits which are 4 or 14 positions appart, and still this will not change the checksum.
OK, so the next candidate would be 98, but this is an even number, worse still, it's divisible by 7, too.
Why is this a problem? Because the more divisors such a number has, the more often it "glues together" different data into same checksum. To see why, recall that the impact of k-th digit from the end is 10k mod 98, which for k>0 is always an even number. That means that, except for the last digit, all the other digits can't influence the parity of the checksum. It effectively makes the last bit of the checksum almost useless: instead of differentiating between 100 (or realistically: 98) groups of strings, it glues them into just 49 groups, which means there must be now much more occasions to make an unnoticed mistake.
So, the actual IBAN uses modulo 97, which is a nice prime number, so doesn't have the above problem and is large enough to efficiently use most of the 100 possible values of the checksum.
Also because 97 is a prime swapping any two digits from any two places must get noticed as
(10k a + b) mod 97 = (10k b + a) mod 97
(10k - 1)a mod 97 = (10k - 1)b mod 97
(10k - 1) (a - b) mod 97 = 0which means 97 divides (a-b) (possible only when digits are in fact equal) or (10k-1) which happens only for k=0 (meaning this is the same digit, not two different positions), k=96 and other k's divisible by 96, all of which are much longer than IBAN.
How to compute a checksum?
So, one way to compute the checksum would be to simply ask the calculator (like bc) what is 105000997603123456789123 mod 97, and get 86.
(If you wonder how come 105000997603123456789123 mod 97 is 86, not 10, the answer is: because in reality IBAN checksum is computed in a slightly different way, but with similar properties - see wikipedia for details, but in short, the letters of the country code get encoded as digits too, and the checksum is conceptually the two digits you have to append to the data and country code to make the remainder mod 97 equal to 1. We will stick to the simplified version, sorry. Similar "technical details" apply to CRC32-C, as we shall see later.)
Another way to compute the checksum, which we've already saw, would be to read one digit at a time, updating the rest modulo 97 of the number seen so far:
"105000997603123456789123"
.split("")
.map((letter) => +letter)
.reduce((checksum, digit) => (checksum * 10 + digit) % 97, 0);We've also saw that we can also associate weight mod 97 with each position:
105000997603123456789123
|||||||||||||||||||||||└100 mod 97 = 1
||||||||||||||||||||||└101 mod 97 = 10
|||||||||||||||||||||└102 mod 97 = 3
||||||||||||||||||||└103 mod 97 = 30
|||||||||||||||||||└104 mod 97 = 9
||||||||||||||||||└105 mod 97 = 90
|||||||||||||||||└106 mod 97 = 27
||||||||||||||||└107 mod 97 = 76
|||||||||||||||└108 mod 97 = 81
||||||||||||||└109 mod 97 = 34
|||||||||||||└1010 mod 97 = 49
||||||||||||└1011 mod 97 = 5
|||||||||||└1012 mod 97 = 50
||||||||||└1013 mod 97 = 15
|||||||||└1014 mod 97 = 53
||||||||└1015 mod 97 = 45
|||||||└1016 mod 97 = 62
||||||└1017 mod 97 = 38
|||||└1018 mod 97 = 89
||||└1019 mod 97 = 17
|||└1020 mod 97 = 73
||└1021 mod 97 = 51
|└1022 mod 97 = 25
└1023 mod 97 = 56which opens up various other ways to compute the same checksum. For example:
(1*56 + 0*25 + 5*51 + 0*73 + 0*17 + 0*89 + 9*38 + 9*62 + 7*45 + 6*53 + 0*15 + 3*50 + 1*5 + 2*49 + 3*34 + 4*81 + 5*76 + 6*27 + 7*90 + 8*9 + 9*30 + 1*3 + 2*10 + 3*1) mod 97, which is 86.
More importantly though, this enables us to compute the checksum in "chunks". Bank account numbers are usually presented in nice four-digit chunks, and we know what is the weight of each of them:
1050 0099 7603 1234 5678 9123
| | | | | └100 mod 97 = 1
| | | | |
| | | | |
| | | | |
| | | | └104 mod 97 = 9
| | | |
| | | |
| | | |
| | | └ 108 mod 97 = 81
| | |
| | |
| | |
| | └ 1012 mod 97 = 50
| |
| |
| |
| └ 1016 mod 97 = 62
|
|
|
└ 1020 mod 97 = 73And indeed (1050*73 + 0099*62 + 7603*50 + 1234*81 + 5678*9 + 9123*1) mod 97 is 86.
This is very useful if you have a machine (like a pocket calculator) capable of some computation on relatively small numbers (here: 4 digits at the time), but not on very large numbers (IBAN has 24 digits which often appears to be too much to chew for pocket calculators).
This method requires you to know (perhaps precompute) what are the weights of each quartet.
Another way to process four-digits at a time, without having to precompute the weights, is to use the same update-as-we-go approach we saw earlier, but adjusted to the fact that each chunk has 10000 times larger weight than next one, so the update rule becomes: (old_checksum * 10000 + this_chunk) mod 97.
So, we start with checksum being 0, and update it with quartets one by one:
( 0 * 10000 + 1050) mod 97 = 80
(80 * 10000 + 0099) mod 97 = 43
(43 * 10000 + 7603) mod 97 = 36
(36 * 10000 + 1234) mod 97 = 6
( 6 * 10000 + 5678) mod 97 = 9
( 9 * 10000 + 9123) mod 97 = 86The downside of this approach is that you can't start computing the next step until you have the result of previous step...
But, we can combine the two techniques! Suppose you have a friend, which offered you help with computing the IBAN, say, by processing the final 12 digits, and that you happen to remember (from the picture above) that 1012 mod 97=50 is the weight of the remaining digits. (Note: this 50 is just a single thing to remember, depends solely on the way you plan to split your work, not on the input itself).
You can now perform your operations in parallel, where you compute the checksum of first 3 chunks, and your friend the last 3 chunks:
you: friend:
( 0 * 10000 + 1050) mod 97 = 80 ( 0 * 10000 + 1234) mod 97 = 70
(80 * 10000 + 0099) mod 97 = 43 (70 * 10000 + 5678) mod 97 = 3
(43 * 10000 + 7603) mod 97 = 36 ( 3 * 10000 + 9123) mod 97 = 32And the final step is to combine your 36 with theirs 32, remembering to put weight 50 on your result:
(36*50 + 32) mod 97 = 86What we should take from this, as it will be useful for crc32:
- the checksum should depend on all data (recall the bad "modulo 100" idea),
- the checksum can be computed while reading the data and updating the checksum computed so far
- one can also think of various positions having associated weights
- the checksum should place different weights on different positions in the data, or realistically (note that they can't literally never repeat, as there is just a finite set of possible weights) makes it so that the same weight repeats very rarely (here: every 96 positions, which is longer than IBAN),
- a wrong checksum strongly implies corruption, but a matching checksum only weakly implies everything is correct
- the goal is to make it so that typical errors in data (here: swapping digits) lead to change in the checksum
- a checksum can be computed in chunks, longer than one digit, or even longer than the resulting checksum - as long as you know how to combine the results
- technical implementation of the idea often has some additional steps which do not change much conceptually but standard-compliance requires them to be performed
What's CRC32?
Now, the CRC32 is a very similar idea, but instead of treating the data digits as a single huge number, we treat it as a huge polynomial, where k-th bit of input is either a 0 or 1 coefficient for xk, and similarly instead of 97, we use another fixed polynomial to divide by, and the result is also a polynomial.
There are technical details like: is the "k" numbering the bits from left-to-right or backwards, and what is the actual fixed polynomial to use. Wikipedia mentions 7 different flavors of CRC-32, of which InnoDB uses the CRC32-C (Castagnoli).
But the overall idea remains the same: we try to reduce something big to something smaller than a fixed constant, by taking rest of division by it.
Dividing one polynomial by another polynomial might sound scary, but it's actually simpler than long division of numbers.
This is because long division of a by b can be thought of as repeatedly subtracting (some multiple of) b from a, and in case of polynomials (over the GF-2 field) "subtracting" is just xoring, and multiplying by x is like "shifting", so the whole task of reducing a big polynomial to a smaller one can be imagined as "try to get rid of all bits set to 1 by xoring a shifted image of the fixed polynomial", so in pseudocode:
for(i=n-1;32<=i;i--)
if(input&(1<<i))
input ^= CRC_32_POLYNOMIAL << (i - 32);The 32 in the name of CRC32 means the polynomial has degree 32, that is the highest non-zero coefficient is for x32, and thus the xor operation is always clearing the i-th bit without introducing any new non-zero bits on higher positions, thus eventually this loop will "clear" the whole input except for the lowest 32 bits, which are the remainder of the division, and our checksum.
Such bit-by-bit approach is too slow, thus there are various "exercises in caching" which try to make the loop shorter by processing larger chunks at the time.
We've already saw that in case of numbers we were able to process a four-digit chunk in one step. Can we do a similar trick for polynomials? Surely!
For imagine that you know that the next four bits to process are for example "1001". You need to clear this first "1", so you know you are about to xor CRC_32_POLYNOMIAL with the data. This might change the next three bits, but in a predictable fashion: the CRC_32_POLYNOMIAL is constant, so you know exactly which of the three bits will flip, and thus you know if the second bit will stay "0" or change to "1", and thus can predict if you'll have to xor CRC_32_POLYNOMIAL again at position shifted by one, or not. Similarly for the next two bits.
In other words: the sequence of the next four bits you see, predictably leads to a sequence of four decisions to xor or not CRC_32_POLYNOMIAL at offsets 0,1,2,3 and this is completely determined by the sequence of the four bits, and the bits of CRC_32_POLYNOMIAL.
So you can precompute a table with 16 entries, one for each possible sequence of four bits, which tells you at which offsets you need to xor the CRC_32_POLYNOMIAL, or better yet, what will be the combined effect of such xoring! As the goal of this xoring is to clear the non-zero bits, we know the fate of the first four bits: they'll become zero for sure. And the next 32 bits of data will get xored by one or more shifted images of CRC_32_POLYNOMIAL, which thanks to xor operation being associative we can combine to a single constant.
Obviously, it's more natural to use 8-bit chunks, a.k.a. bytes, when processing binary data, which leads to pseudo-code like:
for(i=n-1;4<=i;i--)
*(uint32_t*)(input+i-4) ^= PRECOMPUTED[input[i]];(Please forgive me ignoring details such as little-endian vs big-endian architectures.)
where we process whole 8-bit byte at a time, by xoring next 32 bits with a 32-bit long PRECOMPUTED value depending on the byte read.
This required a relatively small uint32_t PRECOMPUTED[256] array, but would become impractical for processing 16-bits or 32-bits at a time, given that the size is exponential.
Processing a whole 64-bit at a time would need a precomputed table larger than our planet, so it's not a way to go.
One more mental picture you can get from this "try to eat all zeros by xoring images of CRC_32_POLYNOMIAL", is that of a snow-plough which tries to clean up snow from a street pushing the chaos forward: it sets the bits behind it to 0, by xoring some bits in front of it. There's always 32 bits of chaos in front of it, and it stops 32 bits from the wall at the end of the street, leaving the messy, pseudorandom 32 bits for you to use as a checksum.

So, while it works, there are zeros, then there is a 32-bit messy part, and then the rest of yet unmodified data, and it is rolling forward this mess.
And you can prove to yourself by induction, that the messy part is actually the checksum of the data processed so far (including the messy part).
Clearly it's true at the beginning, when the first 32-bits of data are also equal to the rest of dividing it by CRC_32_POLYNOMIAL, as any polynomial with 32 coefficients is "smaller than" a polynomial of degree 32.
It's also true at the end, when we've cleared almost everything except for the last 32 bits.
But it's also true meanwhile, which is left as an exercise for the reader :)
This mental exercise suggests, that instead of computing the checksum by "modifying the input", we can use a 32-bit register to store the "messy window part", a.k.a. "checksum so far". This is actually how we've dealt with computing the IBAN: by mentally storing the rest of division by 97 of data seen so far, and updating it with new data as it arrives.
Again, there are some technicalities, like: do we mean checksum of the bytes seen so far, as if the data ended here, or as if there were 32 zeros ahead of it, or rather xored with the actual data in those next unseen 32-bits?
But still, I hope you can convince yourself, that if we fix those details, it is a well defined mathematical problem to "update the checksum by next 64-bits of data".
And most of modern CPUs have an instruction for that!
You put the next 64 bits of data in one register, and the 32-bit checksum you saw for data so far in a second register, and this single instruction will give you updated checksum.
And on x64 InnoDB already used such hardware accelerated instruction to compute the hash 64-bits at a time (for "sse4.2" targets).
On ARM64, before 8.0.27 we've fallen back to the PRECOMPUTED[256] approach. Actually, we've used a slightly more sophisticated variant which used 8 such tables, to handle 64-bits "at a time", or rather "8 independent lookups at a time". The way it works is similar to what we've seen for IBAN: we can associate a weight with each of 8 offsets, and precompute the result of multiplying each precomputed weight with each of possible 256 byte values. You then just have to xor the 8 looked up values to get their combined impact on the checksum. The reason such 8 lookups from 8 arrays might be faster than doing them one by one from a single array, has to do with speculative out-of-order execution in modern processors.
You see, a modern CPU is not executing instructions one by one like factory machine attached to a conveyor belt.
It's more like a big busy port, where ships arive and depart, with lots of cranes and workers trying to unpack, process, repack and ship stuff, while respecting "some" rules on arrivals' and departures' ordering, but doing as much of processing in parallel as possible.
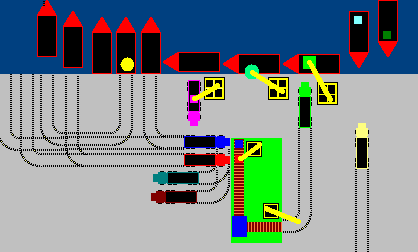
A modern CPU might have hundreds of "in flight" instructions at various stages of completion. So for example you might have an addition operation, which still can't be completed because one of the two operands is yet unknown result of some prior computation, while some other xor operation "few code lines later" is already ready to be performed as both operands are already known.
This means a code like this one:
return (ut_crc32_slice8_table[7][(i)&0xFF] ^
ut_crc32_slice8_table[6][(i >> 8) & 0xFF] ^
ut_crc32_slice8_table[5][(i >> 16) & 0xFF] ^
ut_crc32_slice8_table[4][(i >> 24) & 0xFF] ^
ut_crc32_slice8_table[3][(i >> 32) & 0xFF] ^
ut_crc32_slice8_table[2][(i >> 40) & 0xFF] ^
ut_crc32_slice8_table[1][(i >> 48) & 0xFF] ^
ut_crc32_slice8_table[0][(i >> 56)]);even though executed on single CPU, can actually parallelise all the `(i >> something)`, then all the `something&0xFF`, then all of the lookups, and will only have to "join" the parallel "threads" to compute the 7 xors (and one could even imagine rearranging them in a tree of logarithmic length, instead of chaining them together).
How does MySQL 8.0.27 compute CRC32-C faster?
Newer ARM64 (with "+crc" target) has support for hardware accelerated CRC32CX instruction processing of 64 bits at a time. Changing InnoDB to make use of that was a quick win:

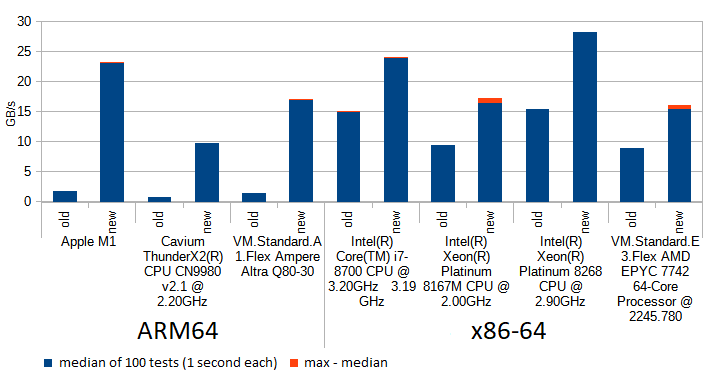
On the chart we see how ARM64 architecture benefits from the change from using software lookup tables (blue "old") to using hardware accelerated CRC32-C instructions (red "old+hardware (1 stream)") as InnoDB already did for x86-64 architecture.
However, even with hardware accelerated 64-bit update steps, each step still has to wait for the previous step before it can start computing, simply because one of its inputs is the result of previous operation. On modern CPUs like Skylake (x64) or M1 (ARM), this is suboptimal use of resources, because these processors are capable of updating more than one crc32 at the same time (either because they have more than one subunit which can do that, or because several instructions can be at various "stages" in the pipeline) - provided that their inputs are already known. The yellow "new (3 streams)" bar on the chart shows the performance of the new implementation which leverages this opportunity.(IIUC the Arm® Neoverse™ N1 Software Optimization Guide this was not a big issue for Ampere Altra, because its "CRC execution supports late forwarding of the result from a producer μOP to a consumer μOP" - I hope this explains why the "new (3 streams)" bar for A1 is very similar to "old+hardware (1stream)").
And we've seen how we can divide the work into independent streams in case of IBAN - we give each worker a separate chunk of data to work on, and combine their results with appropriate weights to form final hash.
Same principle can work for polynomials, too!
Say we have a polynomial like w(x)= ∑i<1024 ai xi, and want to split it into two chunks:
w(x)=∑i<512 ai xi + ∑511≤i<1024 ai xiIf we denote these chunks as:
low(x)=∑i<512 ai xi
high(x)=∑i<512 ai+512 xithen we have w(x)=high(x)x512 + low(x), and thus:
w(x) mod CRC_32_POLYNOMIAL = ((high(x) mod CRC_32_POLYNOMIAL)*(x512 mod CRC_32_POLYNOMIAL) + low(x)) mod CRC_32_POLYNOMIALThe x512 mod CRC_32_POLYNOMIAL part is a constant, analogous to the 1012 mod 97=50 constant in the IBAN story, depends only on the actual bits of the CRC_32_POLYNOMIAL used, and the point at which we split the chunk (512). Thus we can precompute it, and in modern C++ we can use constexpr to do that at compile time!
constexpr uint32_t compute_x_to_8len(size_t len) {
// The x^(len*8) mod CRC32 polynomial depends on len only.
uint32_t x_to_8len = 1;
// push len bytes worth of zeros
for (size_t i = 0; i < len * 8; ++i) {
const bool will_wrap = x_to_8len >> 31 & 1;
x_to_8len <<= 1;
if (will_wrap) x_to_8len ^= CRC32C_POLYNOMIAL;
}
return x_to_8len;
}The "something mod CRC_32_POLYNOMIAL" parts can be done for us using the hardware accelerated crc32 operations mentioned earlier.
But what about the polynomial multiplication used to "scale" the high's checksum by its weight?
A polynomial multiplication is nothing really complicated: to multiply a by b, you just need to xor shifted copies of a, one for each non-zero bit in b:
for(i=0;i<32;++i)
if(b>>i&1)
result^=a<<i;Note, that polynomial multiplication is commutative, so we can make sure that the constant x512 mod CRC_32_POLYNOMIAL plays the role of b in this code, and thus all branches are deterministic thus we know in advance which of the 32 shifted images of the polynomial a we really need to compute.
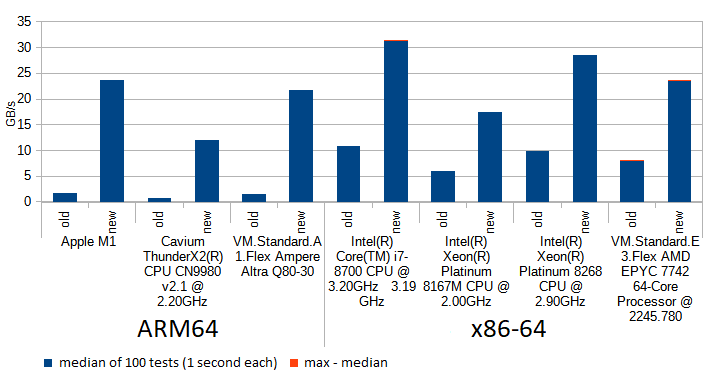
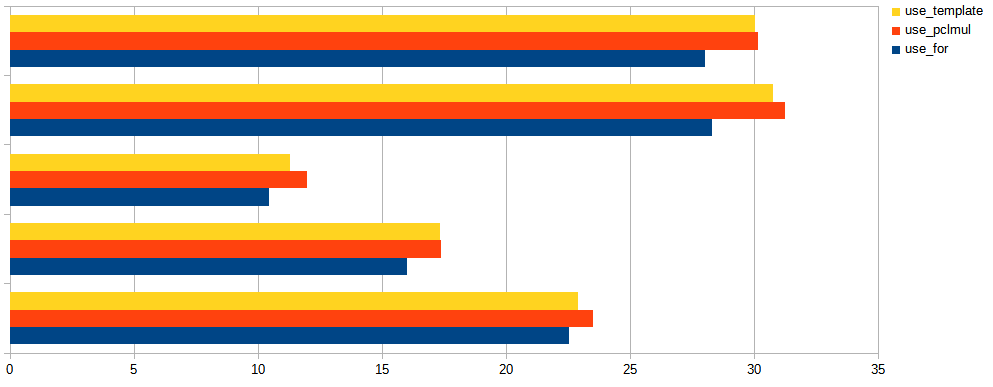
The 8.0.27's implementation uses C++ templates to make sure this loop is unrolled and fully optimized to just a short deterministic sequence of the really needed shifts and xors at compile time, and this indeed helps to improve GB/s processed as demonstrated on this chart:
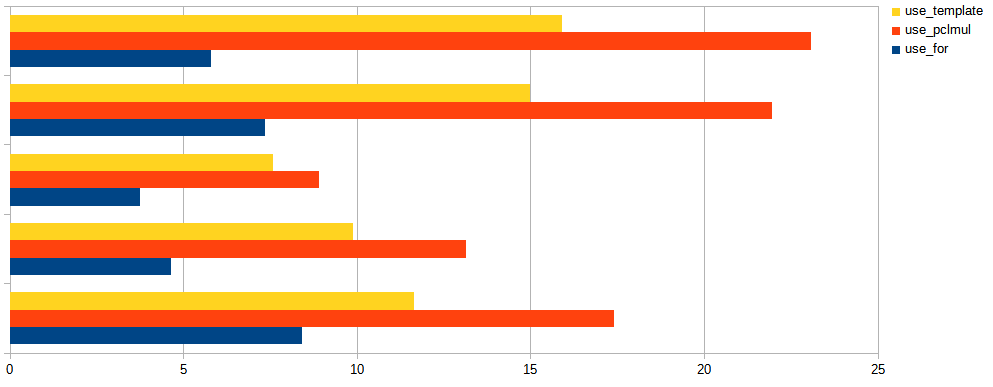
Turns out modern CPUs have a hardware accelerated instruction for polynomial multiplication (vmull_p64 for "crypto" targets on ARM64, and _mm_clmulepi64_si128 for "pclmul" targets on x86). This means the combination step is done by InnoDB in one instruction whenever it detects it's run on a modern CPUs, falling back to unrolled loop if it can't. Above chart shows the difference between using the naive for loop (as in the snippet above), unrolling the loop using C++ templates, and using the hardware accelerated multiplication, for various models of CPUs. Note how unrolling has helped in all tested machines (you never know until you test!), sometimes giving a performance similar to using hardware acceleration. Above chart was for buffers of size 0.5KB which is common for blocks of InnoDB redo log, thus the combination step has to be done 32x more often than for a typical 16KB page. The chart below shows results for 16KB pages, where the impact of combination step is less articulated:
We've talked about splitting the work into two independent streams, but one can divide the work into three or more - the constants involved depend just on the number of streams and length of chunks.
InnoDB (and all above performance tests) uses 3 streams, as suggested by the Intel's paper, and chunks sizes fitted to the most common usecases: computing crc32 of a 16KB tablespace page, or a 0.5KB redolog block. Adding support for other stream counts and sizes is just a matter of recompiling the source with other constants.
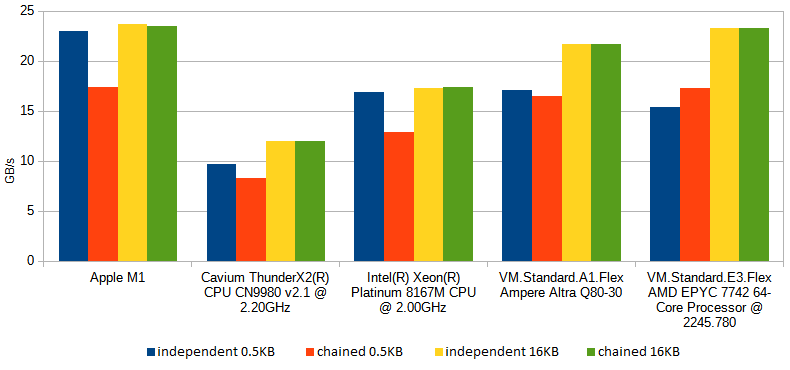
One interesting observation is that the processors with huge reorder buffers - that is those, which have a capacity to look further ahead into the future to see if there are some instructions to execute which don't depend on previous results - seem capable to start computing crc32 for the next block of data (for example: next 0.5KB redo log block) before finishing the previous one. The benchmarks used in experiments above (BM_CRC32_0_508 and BM_CRC32_6_16338 from InnoDB unittests suite) give opportunity for such behaviour as they call the crc32 function many times in a for loop, and each such invocation does not depend on the previous one. This effect is more pronounced for smaller buffers (such as the 0.5KB redo log blocks) and processors with longer reorder buffers (Skylake, Apple M1) and can be demonstrated by repeating the test with slight modification: using the computed hash of previous block as the initial value for hash computation of the next block, effectively chaining together all computation - this prevents such speculative computations and indeed you see impact on speed for some of the processors.
Summary of the new algorithm
So, to wrap it up, the MySQL 8.0.27's implementation of CRC-32C, on a modern CPUs - such as AMD EPYC or Ampere Altra you'll find in Oracle Cloud - will consume the buffer in 3*5440 byte chunks, using hardware accelerated crc32 instructions to consume 64 bits at a time from each of 3 streams, and combine the three results by using hardware accelerated polynomial multiplication. (For smaller buffers it falls back to processing 3*168 bytes, and if that is still too much, falls back to processing 8 bytes at a time. And if polynomial multiplication is not supported by given CPU, it falls back to unrolled loop which doesn't hurt much for large buffers. Finally, if even crc32 is not hardware accelerated then buy a new machine it falls back to using lookups in eight precomputed tables.).
Let me wrap it up, with yet another chart, similar to the one we've started with, but for 0.5KB buffers, as opposed to 16KB: