The new addition to the MySQL planet, MySQL Group Replication is now on Labs Release for you to try it! It offers you update everywhere capabilities on any group of normal, out of the box, MySQL servers. Concurrent updates on a setup of several MySQL servers is now possible and this with our trademark: the ease of use.
In fact we ship MySQL Group Replication in such a way that for you to form a group and add new members, all that is needed is to configure the servers with your unique group id and just press start. In this post we show you the “behind the scenes” of this process, on how the joining member catches up with the remaining servers through distributed recovery.
The basics about Distributed Recovery
If we were to summarize what distributed recovery is, we could describe it as the process through which a new server gets missing data from a live member, while paying attention to what happens in the group, eventually catching up to the other members.
This basically defines it, but there is more to it than the simple data transfer.
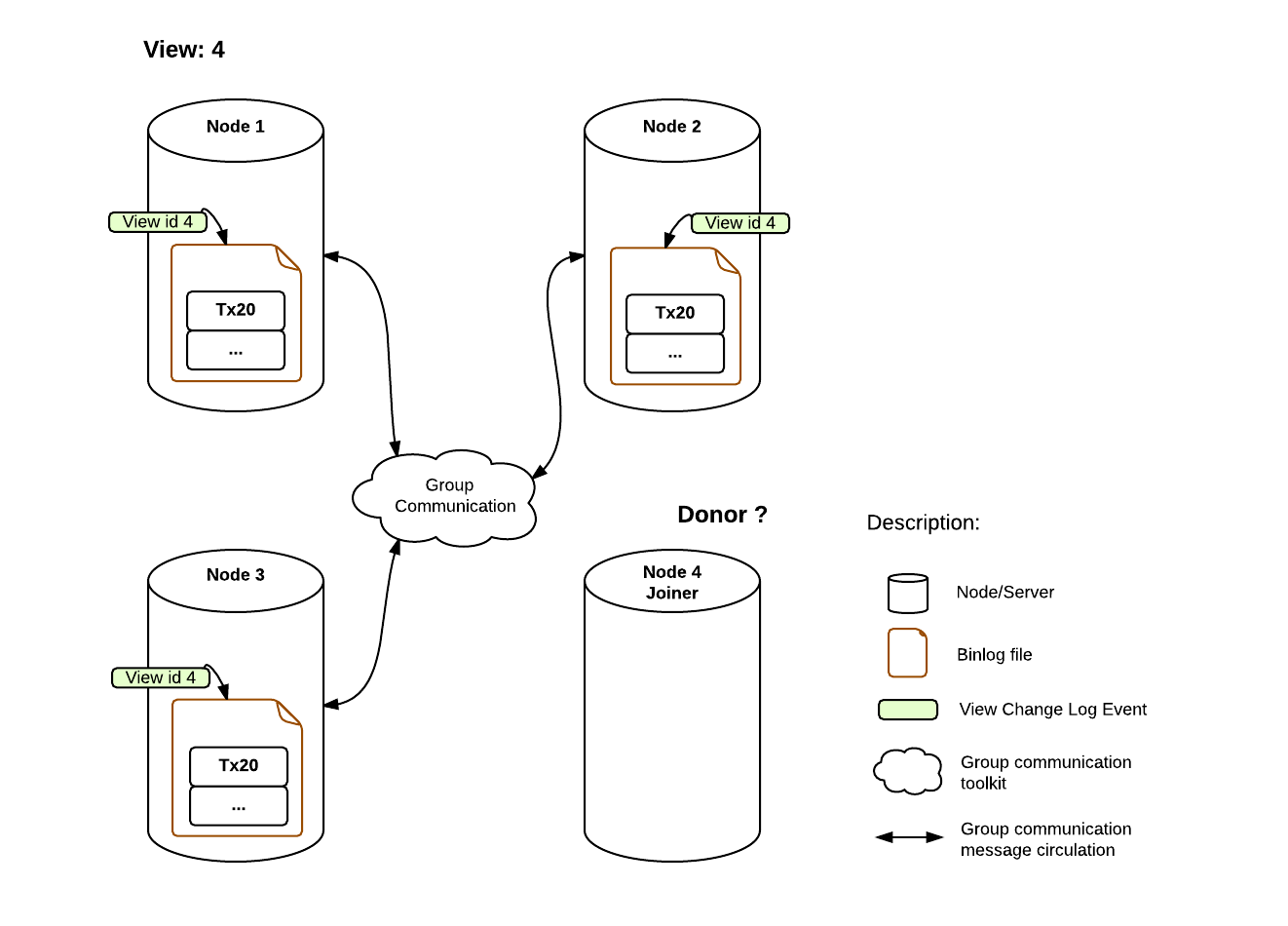
In a first phase, the Joiner (joining member), will select one of the online servers on the group for the role of Donor. The Donor is the server responsible for transmitting to the Joiner all the data up to the moment it joined the group and for this to happen, a standard master slave connection will be established between them.
While the state transfer from the Donor is happening, the plugin is also caching every message that comes from the group. When the first phase ends and the connection to the Donor is closed, the Joiner then starts phase two: the catch up. Here, the Joiner proceeds to the execution of the cached transactions and when the number of transactions queued for execution finally reaches zero, then the member is declared online.
During this process it is possible for server failures to happen, so recovery also comes with failure handling. Every time a Donor dies, if it is still in phase one, recovery reacts by killing the connection and establishing another to a new Donor.
The entrails of Distributed Recovery
How does the Joiner knows what data it should receive from the Donor?
The answer you are probably thinking is that the mechanism is based on GTID executed sets, but in truth, that is not correct. In fact, distributed recovery works through the use of binlog view change markers.
View changes and view ids
To explain the concept of view change markers, lets first define in simple terms what a view and a view change are.
A view corresponds to a group of members recognized as alive and responding at a moment in time. Thence, any modification to the group like a member joining or leaving is what we name a view change. Any group membership change results in an independent view change communicated to all members at the same logic moment. All view changes are also associated to a unique identifier that we call view change id.
At the group layer, view changes with their associated view ids are then frontiers between the data exchanged before and after a member joins. What we do here is to transfer this concept into the database layer through a new binlog event: the view change log event. The view id thus becomes a marker as well for transactions transmitted before and after the group change.
About the view id itself, this is constituted by a generated constant part plus a monotonic increasing identifier. The fixed part is generated whenever a member creates a group, by being the first member to join, and never changes when new members enter or exit while at least one remains. The monotonic view identifier, on the other hand, will be incremented at every group change.
The reason for this heterogeneous pair that constitutes the view id is the need to unambiguously mark group changes whenever a member joins or leaves but also whenever all members leave the group and no information remains of what view the group has in. In fact, the sole use of monotonic increasing identifiers could lead to the reuse of the same id after full group shutdowns, destroying the uniqueness of the binlog data markers that recovery depends on. So, in summary, the first part identifies whenever the group was started from scratch and the incremental part when the group changed from that point on.
Recovery detailed process
Lets now look at the process, on which the view change id is incorporated into a log event and written to the binlog, step by step:
- The stable group
All servers are online and processing transactions from the network. Some servers can be a little delayed in terms transaction execution, but the group acts as one distributed and replicated database.

- A member joins
Whenever a new member joins and the view change is executed, every online server will queue a view change log event for execution. Why do we say queued? Previous to the view change, several transactions can be queued on the server for execution, belonging these to the old view. Queuing the view change event after them guarantees a correct marking of when this happened.
Meanwhile, on the Joiner, the Donor is selected from the pool of online servers.
- State transfer begins
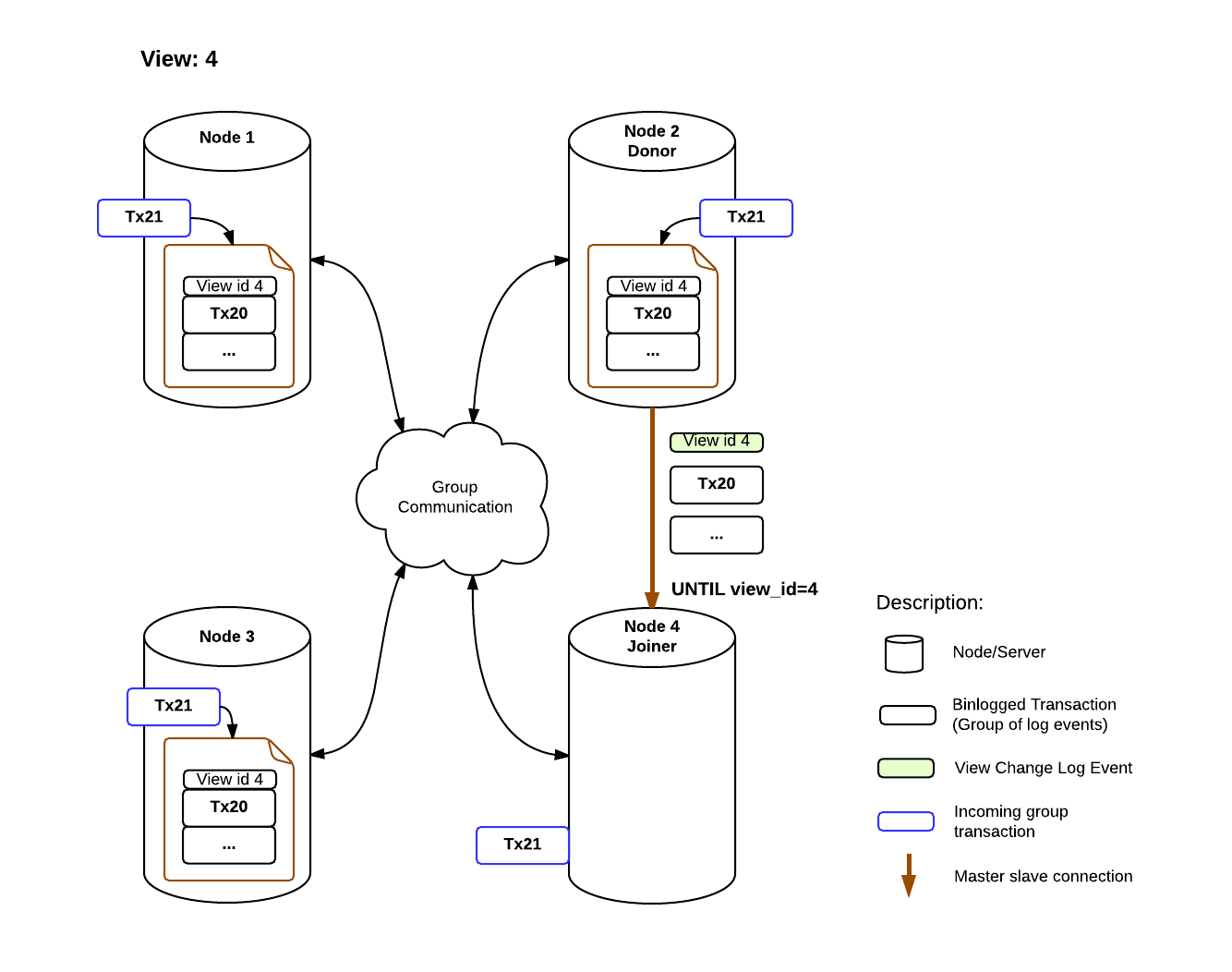
When the Joiner selects a Donor, a new master slave connection is established between the two and the state transfer begins. What differentiates this connection is that the Joiner SQL thread is instructed to stop at a new condition: until view id = N.
As view ids are transmitted to all members in the group at the same logical time, the joiner knows at what view id it should stop. Avoiding tricky GTID set calculations, the view id allows us to clearly mark what data belongs to each group view.
In the meanwhile the Joiner is caching incoming transactions.
- State transfer ends
When the Joiner sees an incoming view change log event with the expected view id, the connection is terminated and the server starts applying the cached group transactions. The view change event also plays another role, as conveyor of the certification information associated to the last view. Without it, the Joiner wouldn’t have the information necessary to know how to certify these transactions.
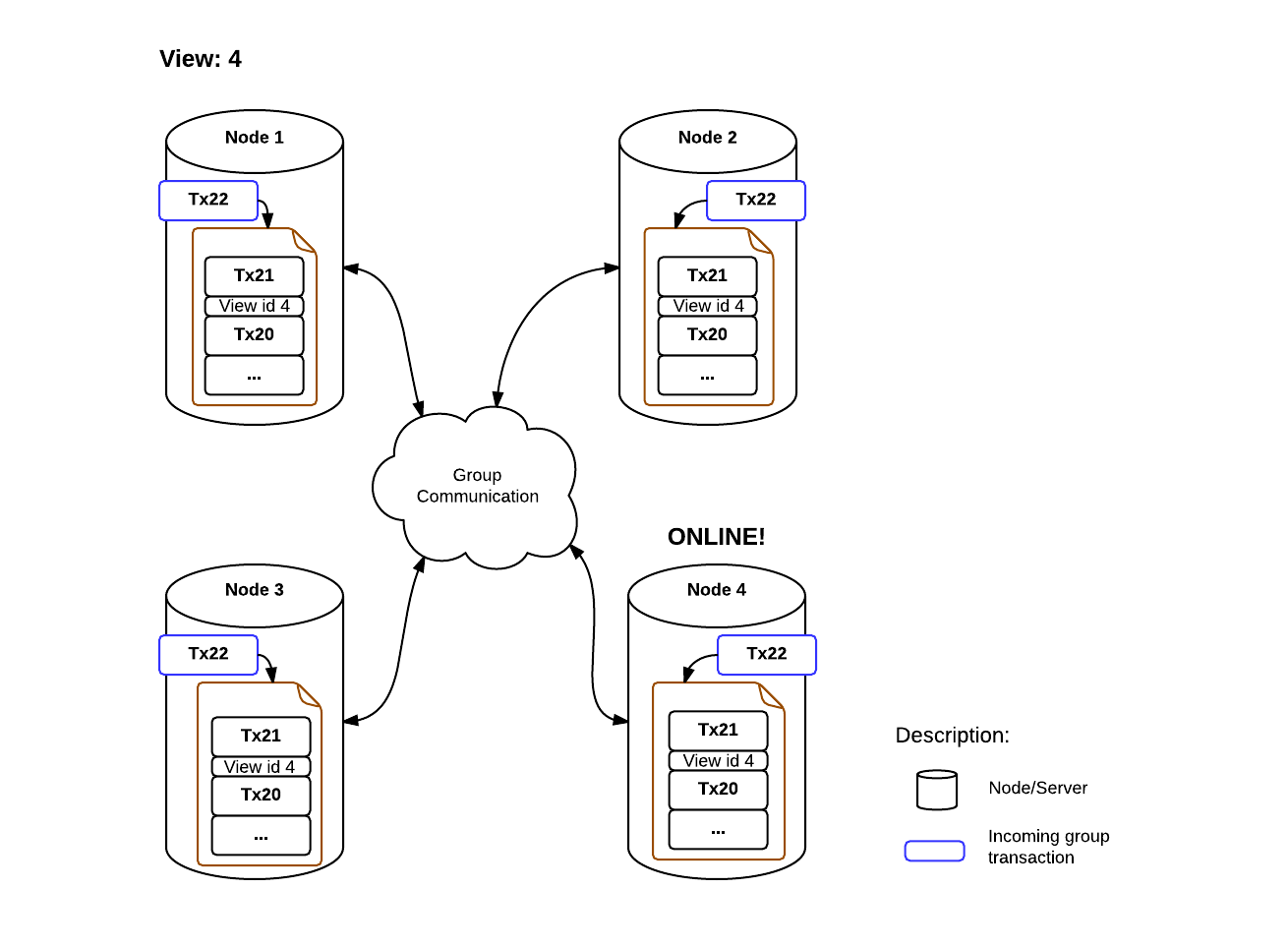
The applying phase duration is not deterministic since it depends on group load. In fact this process does not happen in isolation, as new messages can come in at any time. The number of transactions the member is behind can for this reason vary in time, increasing and decreasing according to the transactional load.
When the member queued transactions reach zero and its stored data is equal to the other members, its public state changes to online.
Use advice and limitations of Distributed Recovery
When trusting distributed recovery, one must still accept its limitations if the data set to transfer is too big. We are still improving recovery and the plugin’s applier to allow speed ups, but for larger loads its still advisable to provision your server before start.
Conclusion
With this blog, we hope we gave you a better understanding of how recovery works behind the scenes. On our side we will keep on improving it, be it in better donor selection algorithms, failure detection or other aspects but we also want your opinion!