In a previous blog post, we discussed how the initialization and restart of the MySQL server has changed between versions 5.6, 5.7 and 8.0. Now, we will take a closer look at MySQL 8.0 to explain in more detail how the transactional data dictionary is bootstrapped. This happens whenever the MySQL server process starts, and we often distinguish between the first time start and the subsequent restarts or upgrades.
The chicken and egg problem
When something depends on itself, we commonly refer to it as the chicken and egg problem. Bootstrapping the data dictionary is such an issue, because we now store the meta data for all tables in dedicated dictionary tables. And we mean all tables, including the dictionary tables themselves.
So to get hold of table meta data we need to read it from the dictionary tables. And to read from the dictionary tables, we need to get hold of the meta data for the dictionary tables to be able to open them.
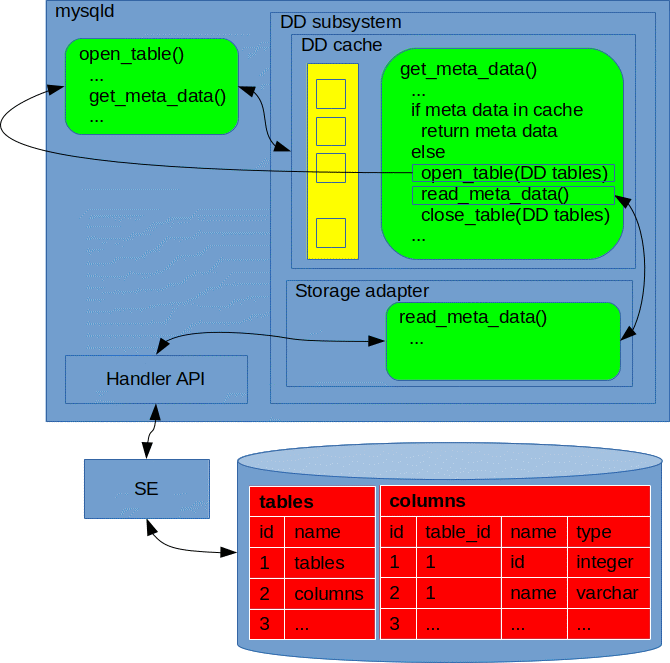
This situation is illustrated above. In the lower part of the figure, we see two dictionary tables: tables and columns. In the tables table, there is a row for each table, including one row for the tables table itself. And in the columns table, there is a row for each column in each table, so we see e.g. one row for each of the two columns in the tables table.
When we want to access a table, e.g. open a user table to read its contents, we first need to get hold of the meta data representing the table. We do this by accessing the cache in the dictionary subsystem. If the meta data is not present in the cache, we have a cache miss which must be handled, and to handle that, we must open the dictionary tables and read the appropriate meta data. So then we must first open the dictionary tables. This is done, again, by accessing the cache. But now, if the meta data representing the dictionary tables is not present in the cache, and we get another cache miss, how can we handle that? We need to get hold of dictionary table meta data in order to open the dictionary tables, but we first need to open the dictionary tables to get hold of the dictionary table meta data…
So how can we resolve this? To break the circular dependency and handle the situations explained above, we make use of the three design principles or objectives:
- Provide a uniform dictionary cache behavior.
- Make use SQL to define the dictionary tables.
- Employ a multi stage approach to bootstrapping the data dictionary.
These three design objectives will be further elaborated below.
Uniform caching behavior
We want to keep the dictionary cache uniform without special handling of the meta data related to the dictionary tables themselves. Thus, we need to short circuit the handling of cache misses in the dictionary cache, because if the meta data of a dictionary table is evicted from the cache, we will not be able to open the dictionary tables to read meta data, as we explained above. To remedy this, we introduce a layer between the dictionary cache and the handler interface which we call the storage adapter. This was already shown in the previous figure, and below, we provide a simplified exploded view of this subsystem.

Here, as illustrated in the figure above, we store the meta data of the dictionary tables in a dedicated data structure called the core registry. Thus, when meta data of a dictionary table is evicted from the dictionary cache, sooner or later, we will need to get hold of that meta data. Then, handling the cache miss for the dictionary table meta data will be dispatched by the storage adapter, and the meta data will be read from this dedicated core registry instead of the data dictionary tables.
Use SQL
The bootstrapping uses SQL to create the dictionary tables. Below, we show a very simplified view of the interaction between the SQL layer, the data dictionary and the storage engines while creating a user table.
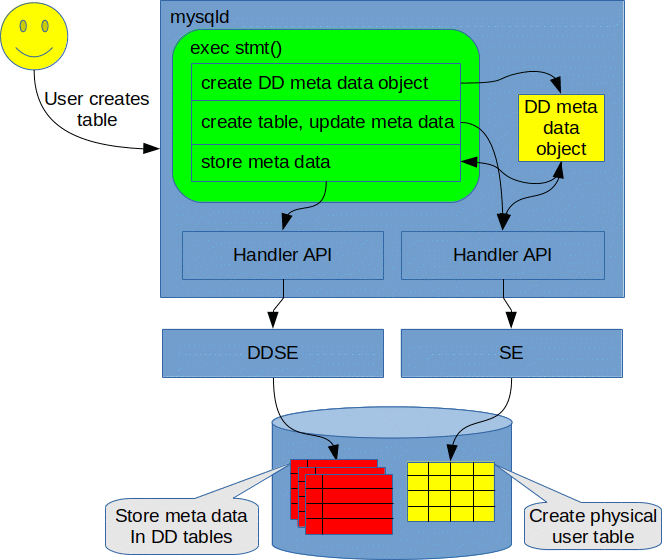
When creating a user table, we collect the relevant meta data and create the dictionary object representing the table. Then, we invoke the storage engine where the table should be created, which creates the table physically, and also updates the dictionary meta data if needed. This is relevant if the storage engine needs to store special meta data in addition to the meta data handled by the SQL layer. Finally, the meta data which has been collected is stored persistently; this is done by invoking the DDSE (data dictionary storage engine), i.e., the storage engine which handles the data dictionary tables.
The procedure above is for creating user tables. So what is different when it comes to creating dictionary tables? There are mainly two issues:
- The storage engine may want to handle the meta data of dictionary tables in a different way than user tables. Thus, when creating a table, the storage engine may need to know whether it is creating a user table or a data dictionary table.
- When meta data is to be stored, we need all data dictionary tables to be present in order to store meta data for a table. Say we first create the data dictionary table called tables. Then, when we want to store the meta data for this table, there is no table for storing column meta data, since the columns table has not been created yet.
In the figure below, we show how we handle these two issues. If we look at the second issue first, we see that this is indeed solved by the core registry in the storage adapter. While bootstrapping the data dictionary, when we create tables, the meta data is dispatched in the storage adapter, and stored only in the core registry. This means that when bootstrapping is completed and all dictionary tables are created, we need a stage where the meta data in the core registry is flushed to the dictionary tables to be stored persistently.
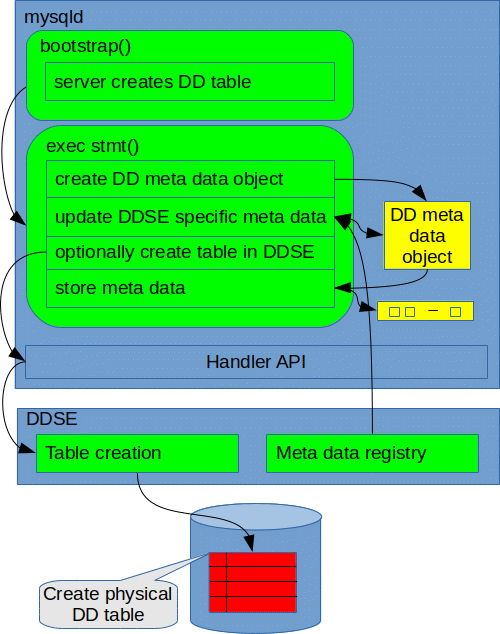
For the first issue, we have introduced a new handler function that retrieves storage engine private data from a storage engine. While creating dictionary tables at the SQL layer, we recognize dictionary tables based on their names, and invoke this function prior to creating the table physically. This allows the DDSE to provide the meta data it needs. While this could also be done while creating the table physically, in the same way as we do for user tables, we separate it because e.g. during server restart, we may want to execute the CREATE TABLE statement only for generating the meta data, not for creating the physical table.
Multi-step process
The dictionary bootstrapping is implemented as a multi step process. A very simplified outline is the following:
- First, there is a preparation phase, where we fetch required information from the DDSE (data dictionary storage engine).
- Next, the scaffolding is built. This means to pre-populate the core meta data registry in the storage adapter to allow the dictionary tables to be opened. This will behave differently for server initialization and server restart, since in the first case, we want to create the tables physically, while in the second case, the tables already exist, and should not be created physically.
- Finally, we can fetch the actual dictionary table meta data from the dictionary tables, and replace the meta data in the core registry in the storage adapter by the real meta data. The way this is done also depends on the context, and is different for first time start and the subsequent restarts or upgrades.
In forthcoming blog posts, we will take a closer look at how these steps are implemented and what is being done for the different bootstrapping use cases.
Thank you for using MySQL !