Blood, sweat, tears and the JSON format logging is finally supported by the Audit Log plugin. This comes in pair with the feature that allows to read log events, which could be useful for rapid analysis of the audit log trail without the need of accessing the files directly. Both features are available from 5.7.21 or 8.0 GA and come along with the MySQL Enterprise Edition.
JSON logging can be enabled by setting the audit_log_format=JSON.
Comparing to XML, the whole structure of the single log entity has changed. Example of the successful connect event:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
{ "timestamp": "2018-05-24 23:15:07", "id": 0, "class": "connection", "event": "connect", "connection_id": 12, "account": { "user": "user", "host": "localhost" }, "login": { "user": "user", "os": "", "ip": "::1", "proxy": "" }, "connection_data": { "connection_type": "tcp/ip", "status": 0, "db": "bank_db" } } |
Every log item is composed of the common fields:
- timestamp – Date and time value.
- id – Identification event counter that enumerates events with same timestamp value.
- class – Class name of the event.
- event – Event name of the specified class.
- connection_id – Identifier of the connection (session) that has triggered the event.
- account – Account the current session is using. This corresponds to the user and host stored in the
mysql.usertable. - login – Login details used for connecting the client.
Remaining fields of the event depend on the event class type. Full field descriptions can be found here.
For better readability of the high volume data, every JSON event is written in a single line in the log file:
|
1
2
3
4
5
6
7
8
9
|
[ { "timestamp": "2018-05-24 22:19:41", "id": 0, "class": "audit", "event": "startup", ... { "timestamp": "2018-05-24 22:19:45", "id": 0, "class": "connection", "event": "connect", ... { "timestamp": "2018-05-24 22:19:45", "id": 1, "class": "connection", "event": "disconnect", ... { "timestamp": "2018-05-24 22:19:47", "id": 0, "class": "connection", "event": "connect", ... { "timestamp": "2018-05-24 22:19:47", "id": 1, "class": "general", "event": "status", ... { "timestamp": "2018-05-24 22:19:47", "id": 2, "class": "connection", "event": "disconnect", ... { "timestamp": "2018-05-24 22:19:53", "id": 0, "class": "audit", "event": "shutdown", ... ] |
Note that the id value increments when two or more audit log events are logged within the same second.
Audit Log File Reading
Audit Log can store log files as the XML or JSON format, depending on the specified output format. When the JSON logging is enabled, we can read events using the provided audit_log_read() UDF. This is not supported for XML logging, sorry!
Audit Log file reading requires SUPER privilege or AUDIT_ADMIN dynamic privilege in 8.0.
Bookmark
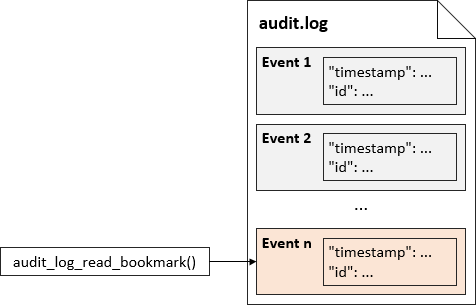
Before we start reading events, we have to understand the bookmark concept. The bookmark is nothing more than a "timestamp" and "id" pair of the event. Referring to the events presented earlier, the bookmark of the last event would be:
|
1 |
{ "timestamp": "2018-05-24 22:19:53", "id": 0 } |
A bookmark specifying the "timestamp" and "id" pair of the last event written to the log file, can be obtained using the audit_log_read_bookmark() UDF:
|
1
2
3
4
5
6
7
|
mysql> SELECT audit_log_read_bookmark(); +-------------------------------------------------+ | audit_log_read_bookmark() | +-------------------------------------------------+ | { "timestamp": "2018-05-24 22:19:53", "id": 0 } | +-------------------------------------------------+ 1 row in set (0.00 sec) |
This is illustrated in the following picture:
Because new events are in general logged between two subsequent audit_log_read_bookmark() invocations, the new bookmark will not be the same:
|
1
2
3
4
5
6
7
|
mysql> SELECT audit_log_read_bookmark(); +-------------------------------------------------+ | audit_log_read_bookmark() | +-------------------------------------------------+ | { "timestamp": "2018-05-24 22:20:00", "id": 0 } | +-------------------------------------------------+ 1 row in set (0.00 sec) |
The following picture illustrates the new event added to the log file:
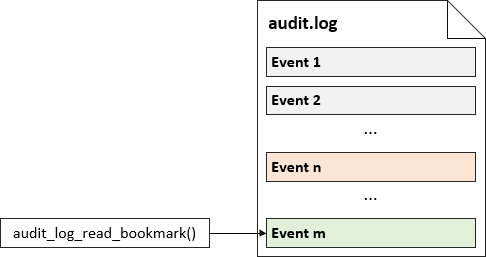
In the preceding example we obtained the two bookmarks, which uniquely identify two events written to the log file.
Reading Events
Once we have a valid bookmark value, we can initiate reading the events from the log file. Reading always starts from the event specified with the bookmark, passed as the argument to the audit_log_read() UDF:
|
1
2
3
4
5
6
7
|
mysql> SELECT audit_log_read('{ "timestamp": "2018-05-24 22:19:53", "id": 0 }'); +----------------------------------------------------------------------------------------------------------+ | audit_log_read('{ "timestamp": "2018-05-24 22:19:53", "id": 0 }') | +----------------------------------------------------------------------------------------------------------+ | [ { "timestamp": "2018-05-24 22:19:53", "id": 0, "class": "connection", "event": "connect", ... }, ... ] | +----------------------------------------------------------------------------------------------------------+ 1 row in set (0.00 sec) |
Subsequent invocations of audit_log_read() do not require bookmark argument, because the reading has been initialized :
|
1
2
3
4
5
6
7
|
mysql> SELECT audit_log_read(); +------------------------------------------------------------------------------------------------------+ | audit_log_read('{ "timestamp": "2018-05-24 22:23:05", "id": 0 }') | +------------------------------------------------------------------------------------------------------+ | [ { "timestamp": "2018-05-24 22:23:05", "id": 0, "class": "general", "event": "status", ... }, ... ] | +------------------------------------------------------------------------------------------------------+ 1 row in set (0.00 sec) |
audit_log_read() will return audit events until the last element of the JSON array is null:
|
1
2
3
4
5
6
7
|
mysql> SELECT audit_log_read(); +-------------------------------------------------------------------------------------------------------+ | audit_log_read('{ "timestamp": "2018-05-24 22:23:43", "id": 0 }') | +-------------------------------------------------------------------------------------------------------+ | [ { "timestamp": "2018-05-24 22:23:43", "id": 0, "class": "general", "event": "status", ... }, null ] | +-------------------------------------------------------------------------------------------------------+ 1 row in set (0.00 sec) |
When the last element of the JSON array is null, subsequent audit_log_read() will report an error:
|
1
2
|
mysql> audit_log_read(); ERROR 3200 (HY000): audit_log_read UDF failed; Reader not initialized. |
The entire event reading process is illustrated in the following picture:
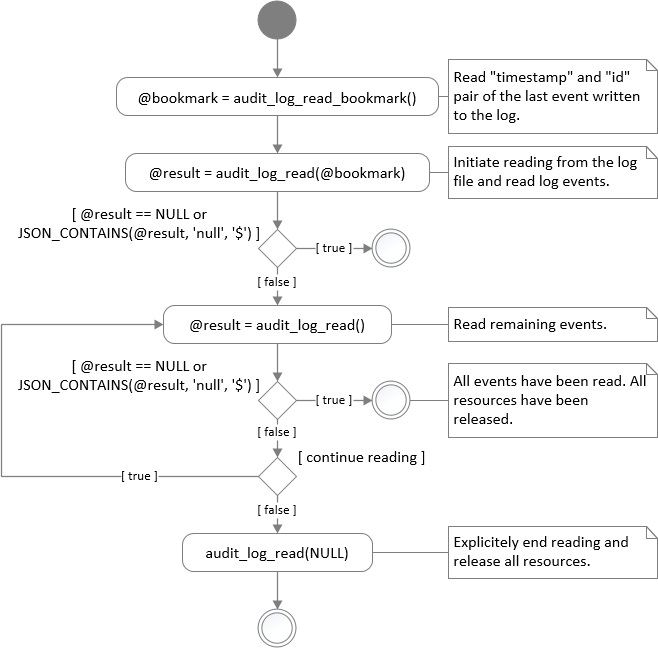
It’s important to understand that the first successful invocation of audit_log_read(@bookmark) (note the bookmark argument) opens the audit log file and keep it open for reading until one of the condition is met:
- All events have been acquired. The end of the audit log file has been reached.
-
audit_log_read(NULL)has been explicitly invoked. - The user has disconnected the session.
Because the opened file is bound to the user session, audit_log_read(@bookmark) closes the previously opened log file and initiates reading from the position specified by the newly provided bookmark argument. The session can read events only from one position at given time.
Note: The first invocation of audit_log_read(@bookmark) can take longer. It must position the reader to the place, where the requested JSON event, specified by the bookmark, is placed. Subsequent audit_log_read() invocations will not take longer than other SQL statements.
JSON
Successful invocation of audit_log_read() should return result in a valid JSON format. Variety of available JSON utility functions can be applied to perform custom data transformation. Example of the pretty-printing (introduced as of 5.7.22 or 8.0) of the JSON result:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
mysql> SELECT JSON_PRETTY(CONVERT(audit_log_read() USING UTF8MB4)); +-------------------------------------------------------------+ | SELECT JSON_PRETTY(CONVERT(audit_log_read() USING UTF8MB4)) | +-------------------------------------------------------------+ | [ { "timestamp": "2018-05-24 22:23:43", "id": 0, "class": "general", "event": "status", ... }, ... ] | +-------------------------------------------------------------+ 1 row in set (0.00 sec) |
Before any JSON utility function is applied, the data returned by audit_log_read() must be explicitly casted to UTF-8 using the CONVERT clause. This is the limitation of the UDFs.
Read buffer size
The number of events returned per audit_log_read() invocation is determined by the size of the buffer associated with the audit_log_read() UDF. The default buffer size is 32 KB (from the next maintenance release), which allows to contain only several log events at once. The buffer can be increased up to 4 MB, by setting the audit_log_read_buffer_size session variable.
If the size of the buffer is small (close to the default value), the user must invoke audit_log_read() more often, comparing to the larger buffer size value. Increasing the buffer size reduces the number of audit_log_read() invocations, but the server needs to allocate and deallocate a larger buffer. There is no single configuration that will satisfy all. Users must find each application’s best setting.
When the buffer is too small to hold an event, an error is generated and the event is skipped:
|
1 |
[Warning] [Server] Plugin audit_log reported: 'Buffer is too small to hold JSON event. Number of events skipped: 1.' |
Maximum event count
Besides of controlling the buffer size, the number of returned events can be specified by using the "max_array_length" JSON element in the invocation of audit_log_read():
|
1 |
mysql> SELECT audit_log_read('{ "max_array_length": 10 }'); |
The preceding example returns maximum 10 events in the result buffer, however the event count could be less if the buffer is not large enough to hold them all at once. The buffer size takes precedence over the specified maximum number of events.
Limiting the number of events can be also used during the initialization of reading. Thanks to this the first event can be skipped:
|
1 |
mysql> SELECT audit_log_read(JSON_INSERT(@bookmark, "$.max_array_length", 1)); |
File rotation
File rotation enables splitting a single, large log file into several smaller files. When file rotation is enabled, a new file is created whenever the current file reaches a certain size. This results in creation of the multiple files containing the logs. Audit Log plugin always writes to the file specified by the audit_log_file variable, which has a default value of audit.log. Rotated file names are derived from the audit_log_file variable value:
|
1
2
3
4
5
6
7
8
9
|
shell> ls audit.20180524T221953.log audit.20180524T222007.log audit.20180524T222022.log audit.20180524T222033.log audit.20180524T222118.log audit.20180524T222128.log audit.20180524T222132.log audit.log |
The Audit Log plugin keeps the reference to the all log files, so that the user can read events from the file that has been rotated:
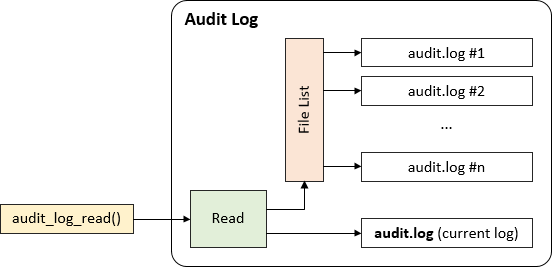
When the user requests reading from the log that is no longer used for logging, the Audit Log must localize the file that contains the event specified with the bookmark. When all events from particular log file are read, next file from the list is opened and the reading process continues. audit_log_read() ends reading, when the end of the current log file is reached:
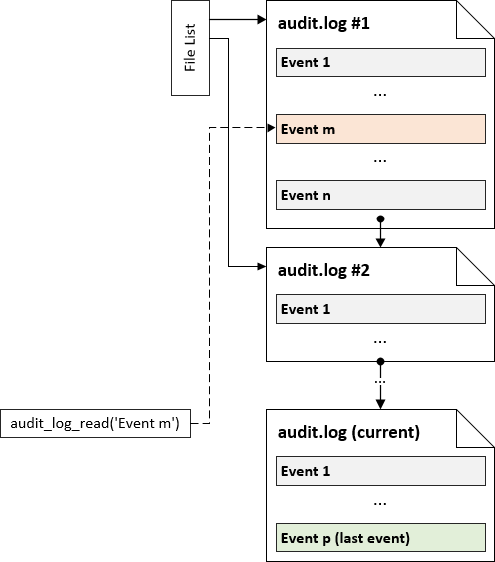
The Audit Log plugin does not maintain indexes of the events stored in the log files. When the user requests reading from the specified event, the file containing the event must be matched and the position of the event must be found. If the event in placed close to the end of the file and the file is very large, it can take extra time.
Server Restart
During the Audit Log installation (at startup or plugin install) the plugin scans the directory and creates the log file list. All bookmarks acquired so far are still valid and ready to be used for reading events using the audit_log_read() UDF.
Note: File list is built based on the audit log file name pattern (audit_log_file). If the variable changes between restarts, the list could not be created.
Summary
Benefits of using the log reading feature:
- Access to the log files does not require direct file access.
- Reading log data can be used for real time log analysis.
- Thanks to the
AUDIT_ADMINprivilege, accessing the logs do not requireSUPERprivilege.
I hope that this blog post will make you familiar with the audit log JSON logging and reading feature and everyone will find own useful applications.
As always, thank you for using MySQL!