|
MySQL 8.0.39
Source Code Documentation
|
|
MySQL 8.0.39
Source Code Documentation
|
When mtr commits, data has to be moved from internal buffer of the mtr to the redo log buffer.
For a better concurrency, procedure for writing to the log buffer consists of following steps:
Afterwards pages modified during the mtr, need to be added to flush lists. Because there is no longer a mutex protecting order in which dirty pages are added to flush lists, additional mechanism is required to ensure that lsn available for checkpoint is determined properly. Hence the procedure consists of following steps:
Range of lsn values is reserved for a provided number of data bytes. The reserved range will directly address space for the data in both the log buffer and the log files.
Procedure used to reserve the range of lsn values:
Increase the global number of reserved data bytes (log.sn) by number of data bytes we need to write.
This is performed by an atomic fetch_add operation:
start_sn = log.sn.fetch_add(len) end_sn = start_sn + len
where len is number of data bytes we need to write.
Then range of sn values is translated to range of lsn values:
start_lsn = log_translate_sn_to_lsn(start_sn) end_lsn = log_translate_sn_to_lsn(end_sn)
The required translations are performed by simple calculations, because:
lsn = sn / LOG_BLOCK_DATA_SIZE * OS_FILE_LOG_BLOCK_SIZE
+ sn % LOG_BLOCK_DATA_SIZE
+ LOG_BLOCK_HDR_SIZE
Wait until the reserved range corresponds to free space in the log buffer.
In this step we could be forced to wait for the log writer thread, which reclaims space in the log buffer by writing data to system buffers.
The user thread waits until the reserved range of lsn values maps to free space in the log buffer, which is true when:
end_lsn - log.write_lsn <= log.buf_size
Wait until the reserved range corresponds to free space in the log files.
In this step we could be forced to wait for page cleaner threads or the log checkpointer thread until it made a next checkpoint.
The user thread waits until the reserved range of lsn values maps to free space in the log files, which is true when:
end_lsn - log.last_checkpoint_lsn <= redo lsn capacity
This mechanism could lead to a deadlock, because the user thread waiting during commit of mtr, keeps the dirty pages locked, which makes it impossible to flush them. Now, if these pages have very old modifications, it could be impossible to move checkpoint further without flushing them. In such case the log checkpointer thread will be unable to reclaim space in the log files.
To avoid such problems, user threads call log_free_check() from time to time, when they don't keep any latches. They try to do it at least every 4 modified pages and if they detected that there is not much free space in the log files, they wait until the free space is reclaimed (but without holding latches!).
This mechanism does not provide safety when concurrency is not limited! In such case we only do the best effort but the deadlock is still possible in theory.
After a range of lsn values has been reserved, the data is copied to the log buffer's fragment related to the range of lsn values.
The log buffer is a ring buffer, directly addressed by lsn values, which means that there is no need for shifting of data in the log buffer. Byte for a given lsn is stored at lsn modulo size of the buffer. It is then easier to reach higher concurrency with such the log buffer, because shifting would require an exclusive access.
Writes to different ranges of lsn values happen concurrently without any synchronization. Each user thread writes its own sequence of log records to the log buffer, copying them from the internal buffer of the mtr, leaving holes for headers and footers of consecutive log blocks.
When mtr_commit() finishes writing the group of log records, it is responsible for updating the first_rec_group field in the header of the block to which end_lsn belongs, unless it is the same block to which start_lsn belongs (in which case user ending at start_lsn is responsible for the update).
recent written buffer
Fragment of the log buffer, which is close to current lsn, is very likely being written concurrently by multiple user threads. There is no restriction on order in which such concurrent writes might be finished. Each user thread which has finished writing, proceeds further without waiting for any other user threads.
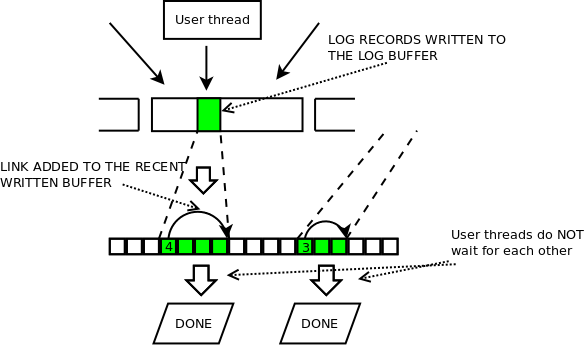
The log recent written buffer is responsible for tracking which of concurrent writes to the log buffer, have been finished. It allows the log writer thread to update log.buf_ready_for_write_lsn, which allows to find the next complete fragment of the log buffer to write. It is enough to track only recent writes, because we know that up to log.buf_ready_for_write_lsn, all writes have been finished. Hence this lsn value defines the beginning of lsn range represented by the recent written buffer in a given time. The recent written buffer is a ring buffer, directly addressed by lsn value. When there is no space in the buffer, user thread needs to wait.
Let us describe the procedure used for adding the links.
Suppose, user thread has just written some of mtr's log records to a range of lsn values tmp_start_lsn .. tmp_end_lsn, then:
tmp_end_lsn - log.buf_ready_for_write_lsn <= Swhere S is a number of slots in the log recent_written buffer.
User thread adds the link by setting value of slot for tmp_start_lsn:
log.recent_written[tmp_start_lsn % S] = tmp_end_lsn
The value gives information about how much to advance lsn when traversing the link.
The log writer thread follows path created by the added links, updates log.buf_ready_for_write_lsn and clears the links, allowing to reuse them (for lsn larger by S).
Before the link is added, release barrier is required, to avoid compile time or memory reordering of writes to the log buffer and the recent written buffer. It is extremely important to ensure, that write to the log buffer will precede write to the recent written buffer.
The same will apply to reads in the log writer thread, so then the log writer thread will be sure, that after reading the link from the recent written buffer it will read the proper data from the log buffer's fragment related to the link.
Copying data and adding links is performed in loop for consecutive log records within the group of log records in the mtr.
Range of lsn values start_lsn .. end_lsn, acquired during the reservation of space, represents the whole group of log records. It is used to mark all the pages in the mtr as dirty.
Each page modified in the mtr is locked and its oldest_modification is checked to see if this is the first modification or the page had already been modified when its modification in this mtr started.
Page, which was modified the first time, will have updated:
and will be added to the flush list for corresponding buffer pool (buffer pools are sharded by page_id).
For other pages, only newest_modification field is updated (with end_lsn).
After writes of all log records in a mtr_commit() have been finished, dirty pages have to be moved to flush lists. Hopefully, after some time the pages will become flushed and space in the log files could be reclaimed.
The procedure for adding pages to flush lists:
Wait for the recent closed buffer covering end_lsn.
Before moving the pages, user thread waits until there is free space for a link pointing from start_lsn to end_lsn in the recent closed buffer. The free space is available when:
end_lsn - log.buf_dirty_pages_added_up_to_lsn < L
where L is a number of slots in the log recent closed buffer.
This way we have guarantee, that the maximum delay in flush lists is limited by L. That's because we disallow adding dirty page with too high lsn value until pages with smaller lsn values (smaller by more than L), have been added!
Add the dirty pages to corresponding flush lists.
During this step pages are locked and marked as dirty as described in Marking pages as dirty.
Multiple user threads could perform this step in any order of them. Hence order of dirty pages in a flush list, is not the same as order by their oldest modification lsn.
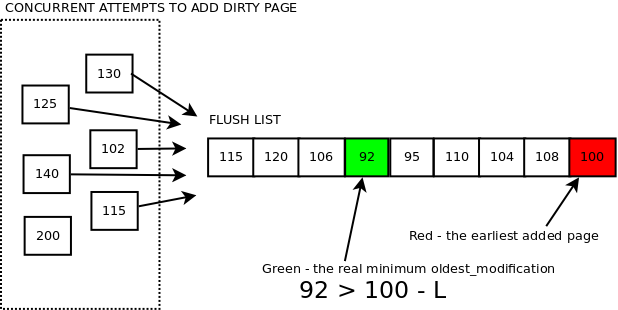
closed buffer
After all the dirty pages have been added to flush lists, a link pointing from start_lsn to end_lsn is added to the log recent closed buffer.
This is performed by user thread, by setting value of slot for start_lsn:
log.recent_closed[start_lsn % L] = end_lsn
where L is size of the log recent closed buffer. The value gives information about how much to advance lsn when traversing the link.
After the link is added, the shared-access for log buffer is released. This possibly allows any thread waiting for an exclussive access to proceed.
Recall that recovery always starts at the last written checkpoint lsn. Therefore log.last_checkpoint_lsn defines the beginning of the log files. Because size of the log files is fixed, it is easy to determine if a given range of lsn values corresponds to free space in the log files or not (in which case it would overwrite tail of the redo log for smaller lsns).
Space in the log files is reclaimed by writing a checkpoint for a higher lsn. This could be possible when more dirty pages have been flushed. The checkpoint cannot be written for higher lsn than the oldest_modification of any of the dirty pages (otherwise we would have lost modifications for that page in case of crash). It is log checkpointer thread, which calculates safe lsn for a next checkpoint (subsect_redo_log_available_for_checkpoint_lsn) and writes the checkpoint. User threads doing writes to the log buffer, no longer hold mutex, which would disallow to determine such lsn and write checkpoint meanwhile.
Suppose user thread has just finished writing to the log buffer, and it is just before adding the corresponding dirty pages to flush lists, but suddenly became scheduled out. Now, the log checkpointer thread comes in and tries to determine lsn available for a next checkpoint. If we allowed the thread to take minimum oldest_modification of dirty pages in flush lists and write checkpoint at that lsn value, we would logically erase all log records for smaller lsn values. However the dirty pages, which the user thread was trying to add to flush lists, could have smaller value of oldest_modification. Then log records protecting the modifications would be logically erased and in case of crash we would not be able to recover the pages.
That's why we need to protect from doing checkpoint at such lsn value, which would logically erase the just written data to the redo log, until the related dirty pages have been added to flush lists.
When user thread has added all the dirty pages related to start_lsn .. end_lsn, it creates link in the log recent closed buffer, pointing from start_lsn to end_lsn. The log closer thread tracks the links in the recent closed buffer, clears the slots (so they could be safely reused) and updates the subsect_redo_log_buf_dirty_pages_added_up_to_lsn, reclaiming space in the recent closed buffer and potentially allowing to advance checkpoint further.
Order of pages added to flush lists became relaxed so we also cannot rely directly on the lsn of the earliest added page to a given flush list. It is not guaranteed that it has the minimum oldest_modification anymore. However it is guaranteed that it has oldest_modification not higher than the minimum by more than L. Hence we subtract L from its value and use that as lsn available for checkpoint according to the given flush list. For more details read about adding dirty pages.