|
MySQL 8.0.39
Source Code Documentation
|
|
MySQL 8.0.39
Source Code Documentation
|
The redo log is a write ahead log of changes applied to contents of data pages. It provides durability for all changes applied to the pages. In case of crash, it is used to recover modifications to pages that were modified but have not been flushed to disk.
Every change to content of a data page must be done through a mini-transaction (so called mtr - mtr_t), which in mtr_commit() writes all its log records to the redo log.
Single mtr can cover changes to multiple pages. In case of crash, either the whole set of changes from a given mtr is recovered or none of the changes.
During life time of a mtr, a log of changes is collected inside an internal buffer of the mtr. It contains multiple log records, which describe changes applied to possibly different modified pages. When the mtr is committed, all the log records are written to the log buffer within a single group of the log records. Procedure:
Background threads are responsible for writing of new changes in the log buffer to the log files. User threads that require durability for the logged records, have to wait until the log gets flushed up to the required point.
During recovery only complete groups of log records are recovered and applied. Example given, if we had rotation in a tree, which resulted in changes to three nodes (pages), we have a guarantee, that either the whole rotation is recovered or nothing, so we will not end up with a tree that has incorrect structure.
Consecutive bytes written to the redo log are enumerated by the lsn values. Every single byte written to the log buffer corresponds to current lsn increased by one.
Data in the redo log is structured in consecutive blocks of 512 bytes (OS_FILE_LOG_BLOCK_SIZE). Each block contains a header of 12 bytes (LOG_BLOCK_HDR_SIZE) and a footer of 4 bytes (LOG_BLOCK_TRL_SIZE). These extra bytes are also enumerated by lsn values. Whenever we refer to data bytes, we mean actual bytes of log records - not bytes of headers and footers of log blocks. The sequence of enumerated data bytes, is called the sn values. All headers and footers of log blocks are added within the log buffer, where data is actually stored in proper redo format.
When a user transaction commits, extra mtr is committed (related to undo log), and then user thread waits until the redo log is flushed up to the point, where log records of that mtr end.
When a dirty page is being flushed, a thread doing the flush, first needs to wait until the redo log gets flushed up to the newest modification of the page. Afterwards the page might be flushed. In case of crash, we might end up with the newest version of the page and without any earlier versions of the page. Then other pages, which potentially have not been flushed before the crash, need to be recovered to that version. This applies to: pages modified within the same group of log records, and pages modified within any earlier group of log records.
Redo log consists of following data layers:
User threads need to wait if there is no space in the log buffer.
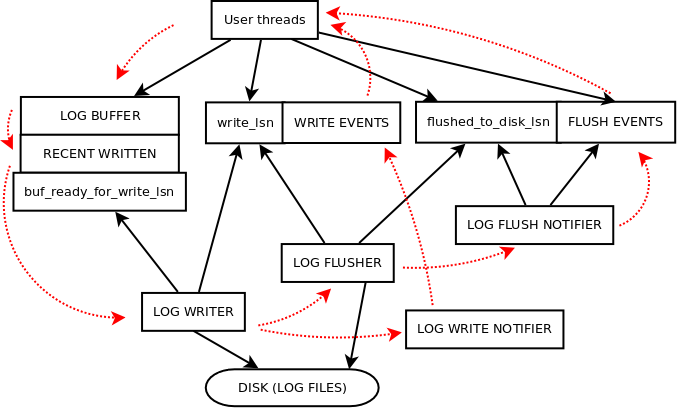
User threads need to wait if there is no space in the log files.
All the new buffers could be resized dynamically during runtime. In practice, only size of the log buffer is accessible without the EXPERIMENTAL mode.
Different fragments of head of the redo log are tracked by different values:
Different fragments of the redo log's tail are tracked by different values:
Up to this lsn we have written all data to log files. It's the beginning of the unwritten log buffer. Older bytes in the buffer are not required and might be overwritten in cyclic manner for lsn values larger by log.buf_size.
Value is updated by: log writer thread.
Up to this lsn, all concurrent writes to log buffer have been finished. We don't need older part of the log recent-written buffer.
It obviously holds:
log.buf_ready_for_write_lsn >= log.write_lsn
Value is updated by: log writer thread.
Up to this lsn, we have written and flushed data to log files.
It obviously holds:
log.flushed_to_disk_lsn <= log.write_lsn
Value is updated by: log flusher thread.
Corresponds to current lsn. Maximum assigned sn value (enumerates only data bytes).
It obviously holds:
log.sn >= log_translate_lsn_to_sn(log.buf_ready_for_write_lsn)
Value is updated by: user threads during reservation of space.
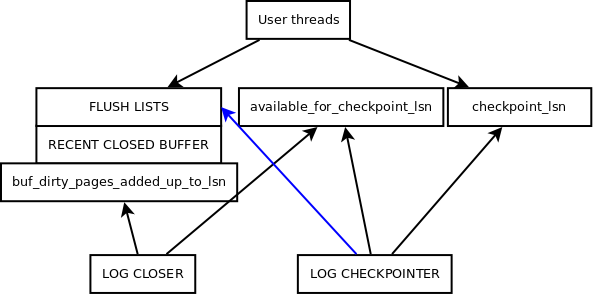
log.buf_dirty_pages_added_up_to_lsn
Up to this lsn user threads have added all dirty pages to flush lists.
The redo log records are allowed to be deleted not further than up to this lsn. That's because there could be a page with oldest_modification smaller than the minimum oldest_modification available in flush lists. Note that such page is just about to be added to flush list by a user thread, but there is no mutex protecting access to the minimum oldest_modification, which would be acquired by the user thread before writing to redo log. Hence for any lsn greater than buf_dirty_pages_added_up_to_lsn we cannot trust that flush lists are complete and minimum calculated value (or its approximation) is valid.
It holds (unless the log writer thread misses an update of the log.buf_ready_for_write_lsn):
log.buf_dirty_pages_added_up_to_lsn <= log.buf_ready_for_write_lsn.
log.available_for_checkpoint_lsn
Up to this lsn all dirty pages have been flushed to disk. However, this value is not guaranteed to be the maximum such value. As insertion order to flush lists is relaxed, the buf_pool_get_oldest_modification_approx() returns modification time of some page that was inserted the earliest, it doesn't have to be the oldest modification though. However, the maximum difference between the first page in flush list, and one with the oldest modification lsn is limited by the number of entries in the log recent closed buffer.
That's why from result of buf_pool_get_oldest_modification_approx() size of the log recent closed buffer is subtracted. The result is used to update the lsn available for a next checkpoint.
This has impact on the redo format, because the checkpoint_lsn can now point to the middle of some group of log records (even to the middle of a single log record). Log files with such checkpoint are not recoverable by older versions of InnoDB by default.
Value is updated by: log checkpointer thread.
Up to this lsn all dirty pages have been flushed to disk and the lsn value has been flushed to the header of the redo log file containing that lsn.
The lsn value points to place where recovery is supposed to start. Data bytes for smaller lsn values are not required and might be overwritten (log files are circular). One could consider them logically deleted.
Value is updated by: log checkpointer thread.
It holds:
log.last_checkpoint_lsn
<= log.available_for_checkpoint_lsn
<= log.buf_dirty_pages_added_up_to_lsn.
Read more about redo log details: