|
MySQL 8.0.40
Source Code Documentation
|
|
MySQL 8.0.40
Source Code Documentation
|
Three background log threads are responsible for writes of new data to disk:
Two background log threads are responsible for checkpoints (reclaiming space in log files):
This thread is responsible for writing data from the log buffer to disk (to the log files). However, it's not responsible for doing fsync() calls. It copies data to system buffers. It is the log flusher thread, which is responsible for doing fsync().
There are following points that need to be addressed by the log writer thread:
Find out how much data is ready in the log buffer, which is concurrently filled in by multiple user threads.
In the log recent written buffer, user threads set links for every finished write to the log buffer. Each such link is represented as a number of bytes written, starting from a start_lsn. The link is stored in the slot assigned to the start_lsn of the write.
The log writer thread tracks links in the recent written buffer, traversing a connected path created by the links. It stops when it encounters a missing outgoing link. In such case the next fragment of the log buffer is still being written (or the maximum assigned lsn was reached).
It also stops as soon as it has traversed by more than 4kB, in which case it is enough for a next write (unless we decided again to do fsyncs from inside the log writer thread). After traversing links and clearing slots occupied by the links (in the recent written buffer), the log writer thread updates log.buf_ready_for_write_lsn.
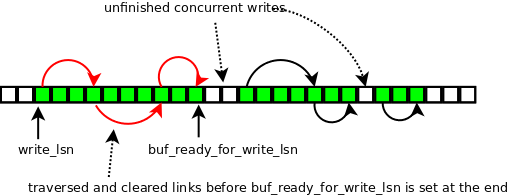
If there were no links to traverse, log.buf_ready_for_write_lsn was not advanced and the log writer thread needs to wait. In such case it first uses spin delay and afterwards switches to wait on the writer_event.
Prepare log blocks for writing - update their headers and footers.
The log writer thread detects completed log blocks in the log buffer. Such log blocks will not receive any more writes. Hence their headers and footers could be easily updated (e.g. checksum is calculated).
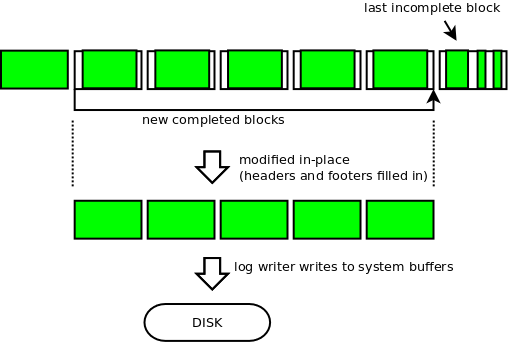
If any complete blocks were detected, they are written directly from the log buffer (after updating headers and footers). Afterwards the log writer thread retries the previous step before making next decisions. For each write consisting of one or more complete blocks, the MONITOR_LOG_FULL_BLOCK_WRITES is incremented by one.
The special case is also for the last, incomplete log block. Note that log.buf_ready_for_write_lsn could be in the middle of such block. In such case, next writes are likely incoming to the log block.
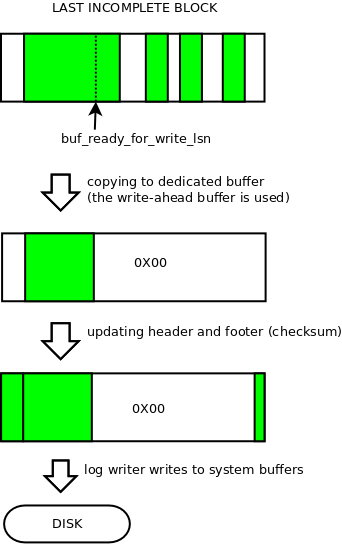
For performance reasons we often need to write the last incomplete block. That's because it turned out, that we should try to reclaim user threads as soon as possible, allowing them to handle next transactions and provide next data.
In such case:
the MONITOR_LOG_PARTIAL_BLOCK_WRITES is incremented by one.
Avoid read-on-write issue.
The log writer thread is also responsible for writing ahead to avoid the read-on-write problem. It tracks up to which point the write ahead has been done. When a write would go further:
If we were trying to write more than size of single write-ahead region, we limit the write to completed write-ahead sized regions, and postpone writing the last fragment for later (retrying with the first step and updating the buf_ready_for_write_lsn).
Else, we copy data to special write-ahead buffer, from which we could safely write the whole single write-ahead sized region. After copying the data, the write-ahead buffer is completed with 0x00 bytes.
Update write_lsn.
After doing single write (single log_data_blocks_write()), the log writer thread updates log.write_lsn and fallbacks to its main loop. That's because a lot more data could be prepared in meantime, as the write operation could take significant time.
That's why the general rule is that after doing log_data_blocks_write(), we need to update log.buf_ready_for_write_lsn before making next decisions on how much to write within next such call.
Notify log writer_notifier thread using os_event_set on the write_notifier_event.
The log flusher thread is responsible for doing fsync() of the log files.
When the fsync() calls are finished, the log flusher thread updates the log.flushed_to_disk_lsn and notifies the log flush_notifier thread using os_event_set() on the flush_notifier_event.
If the log flusher thread detects that none of the conditions is satisfied, it simply waits and retries the checks. After initial spin delay, it waits on the flusher_event.
The log flush_notifier thread is responsible for notifying all user threads that are waiting for log.flushed_to_disk_lsn >= lsn, when the condition is satisfied.
The log flush_notifier thread waits for the advanced flushed_to_disk_lsn in loop, using os_event_wait_time_low() on the flush_notifier_event. When it gets notified by the log flusher, it ensures that the flushed_to_disk_lsn has been advanced (single new byte is enough though).
It notifies user threads waiting on all events between (inclusive):
Events are assigned per blocks in the circular array of events using mapping:
event_slot = (lsn-1) / OS_FILE_LOG_BLOCK_SIZE % S
where S is size of the array (number of slots with events). Each slot has single event, which groups all user threads waiting for flush up to any lsn within the same log block (or log block with number greater by S*i).
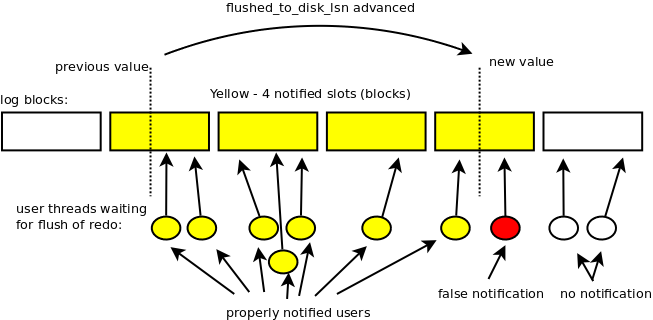
Internal mutex in event is used, to avoid missed notifications (these would be worse than the false notifications).
However, there is also maximum timeout defined for the waiting on the event. After the timeout was reached (default: 1ms), the flushed_to_disk_lsn is re-checked in the user thread (just in case).
The log write_notifier thread is responsible for notifying all user threads that are waiting for log.write_lsn >= lsn, when the condition is satisfied.
The log write_notifier thread waits for the advanced write_lsn in loop, using os_event_wait_time_low() on the write_notifier_event. When it gets notified (by the log writer), it ensures that the write_lsn has been advanced (single new byte is enough). Then it notifies user threads waiting on all events between (inclusive):
Events are assigned per blocks in the circular array of events using mapping:
event_slot = (lsn-1) / OS_FILE_LOG_BLOCK_SIZE % S
where S is size of the array (number of slots with events). Each slot has single event, which groups all user threads waiting for write up to any lsn within the same log block (or log block with number greater by S*i).
Internal mutex in event is used, to avoid missed notifications (these would be worse than the false notifications).
However, there is also maximum timeout defined for the waiting on the event. After the timeout was reached (default: 1ms), the write_lsn is re-checked in the user thread (just in case).
The log checkpointer thread is responsible for:
This thread has been introduced at the very end. It was not required for the performance, but it makes the design more consistent after we have introduced other log threads. That's because user threads are not doing any writes to the log files themselves then. Previously they were writing checkpoints when needed, which required synchronization between them.
The log checkpointer thread updates log.available_for_checkpoint_lsn, which is calculated as:
min(log.buf_dirty_pages_added_up_to_lsn, max(0, oldest_lsn - L))
where:
The special case is when there is no dirty page in flush lists - then it's basically set to the log.buf_dirty_pages_added_up_to_lsn.
disk
User has to wait until the log writer thread has written data from the log buffer to disk for lsn >= end_lsn of log range used by the user, which is true when:
write_lsn >= end_lsn
The log.write_lsn is updated by the log writer thread.
The waiting is solved using array of events. The user thread waiting for a given lsn, waits using the event at position:
slot = (end_lsn - 1) / OS_FILE_LOG_BLOCK_SIZE % S
where S is number of entries in the array. Therefore the event corresponds to log block which contains the end_lsn.
The log write_notifier thread tracks how the log.write_lsn is advanced and notifies user threads for consecutive slots.
to disk
If a user need to assure the log persistence in case of crash (e.g. on COMMIT of a transaction), he has to wait until [log flusher](Thread: log flusher) has flushed log files to disk for lsn >= end_lsn of log range used by the user, which is true when:
flushed_to_disk_lsn >= end_lsn
The log.flushed_to_disk_lsn is updated by the log flusher thread.
The waiting is solved using array of events. The user thread waiting for a given lsn, waits using the event at position:
slot = (end_lsn - 1) / OS_FILE_LOG_BLOCK_SIZE % S
where S is number of entries in the array. Therefore the event corresponds to log block which contains the end_lsn.
The log flush_notifier thread tracks how the log.flushed_to_disk_lsn is advanced and notifies user threads for consecutive slots.